攝影:李宗翰
最近幾年,繪圖處理器(GPU)在高效能運算領域(HPC)應用得越來越普遍,英特爾後來也推出了Xeon Phi的協同運算處理器來對應,提供的核心數量也有所提升,但聲勢仍然不如競爭對手,而在當前熱門的深度學習和人工智慧領域,對於這類運算技術的需求更為迫切,也使得該公司在此蒙受相當大的競爭壓力。
而在今年6月底於德國法蘭克福舉行的國際超級電腦大會(ISC)上,英特爾正式推出了研發代號為「Knights Landing」的新一代Xeon Phi,正式捨棄了先前所用的協同處理器(Coprocessor)名稱,而是挾帶著集合處理器、記憶體與網路於一體的新特色,以及該公司獨霸全球的伺服器廠商生態系,再加上去年成立的OpenHPC社群之力,這些策略若能奏效,英特爾扳回一成的新機會似乎有可能出現。
新Xeon Phi的正式發表場合也很特別,其實是在ISC大會第一天結束前的特殊主題演講上,由該公司資料中心事業群副總裁Rajeeb Hazra所宣布。原本,他的講題是「人工智慧:下一個會產生Exa超大規模的工作負載應用」,不過等到他真正開講時,所用的題目卻叫做「AI and more on IA」,這裡用了雙關語的巧喻,AI當然是指人工智慧,而IA則是英特爾運算架構(Intel Architecture),可見英特爾希望人工智慧系統的建置,都能越來越仰賴英特爾運算架構來幫忙。
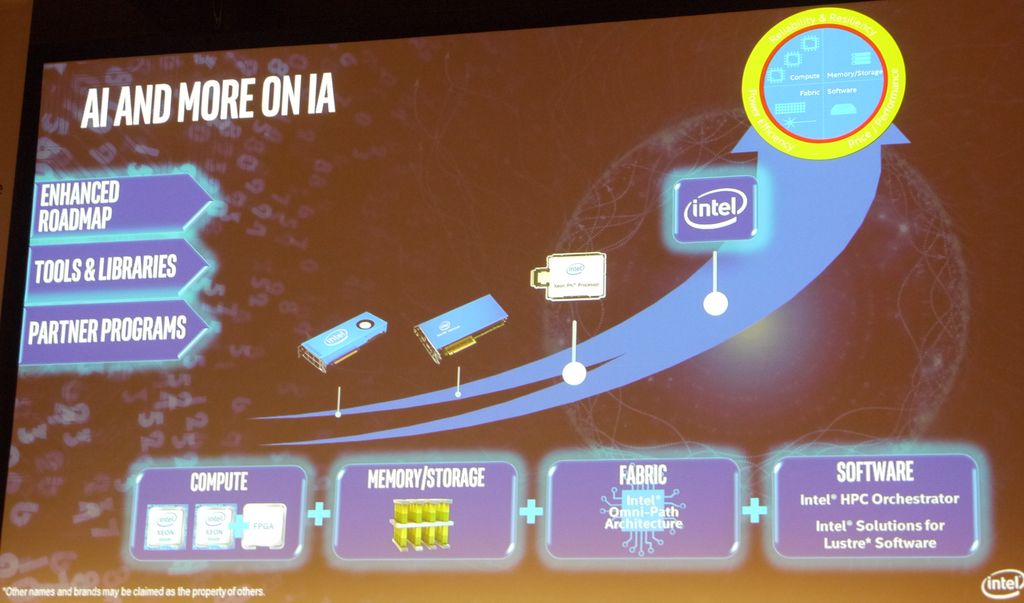
該場演講另一個耐人尋味的部份是,Rajeeb Hazra以目前當紅的智慧車輛、自動駕駛車的技術發展,延伸至認知型應用系統基礎架構(Cognitive Infrastructure),進而推論至Exa超大規模應用需求出現的必然性,接著提到英特爾近期主推可延展式系統框架(Scalable System Framework,SFF),能夠因應這類應用所需的IT基礎架構,最後再以新的Xeon Phi推出作結。
從自動駕駛車對運算資源的需求,直到透過超多核心處理器的來幫忙,這些都和當前GPU廠商當前主要發展的應用,都是相同的方向。但Xeon Phi最大的差別在於能以一顆處理器的架構,同時整合伺服器系統端原本的處理器、記憶體、網路,而不是採取協同運算的模式、從旁扮演輔助加速運算的角色。
這樣的高度整合運算架構,無疑是為了針對當前不少人所採用的GPGPU(General-purpose computing on graphics processing units)的架構而來。Rajeeb Hazra強調,基於新的Xeon Phi平臺,用戶不用再煩惱程式運作的模式(programming model),只需統一標準、用Intel架構,即能以單一而非多重的程式碼來因應整體運算系統的執行,如此可因為程式碼能重複利用、便於共用,而增進系統開發效率。
因此,在這樣的運算架構下,英特爾認為可以執行任何的工作負載,而且提升可程式化的能力,而在整合處理器、記憶體與網路之後,Xeon Phi又可以獲得一些其他效益,例如提升用電效率、支援大型記憶體應用,以及免除了PCIe介面所可能造成的傳輸瓶頸。而在運作效能、能源效率與成本等指標上,相較於市面上的GPU加速器產品,該公司強調Xeon Phi具有相當領先的表現,最高可提供5倍的效能,8倍的每瓦效能,而效能單位成本(每一美元提供的效能)更可達到9倍。

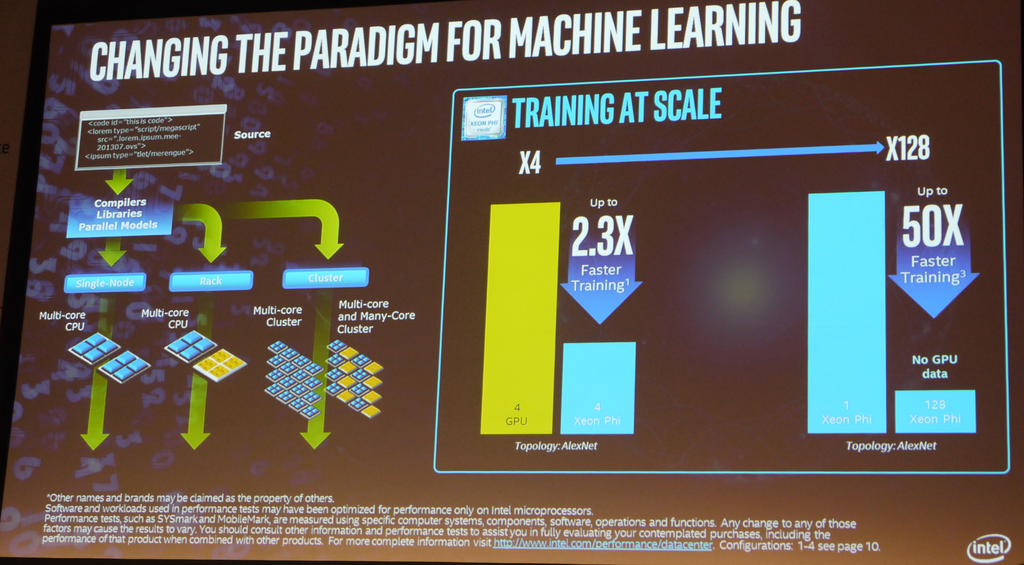
在性能上,Rajeeb Hazra也特別公布了一項針對機器學習應用的效能比較數據,突顯Xeon Phi的優勢。他們主要是以訓練人工智慧系統學習的處理程序為例,以4個GPU加速器對上4個Xeon Phi,並架設在AlexNet的拓樸模式下運作,結果,Xeon Phi訓練速度是2.3倍;他們也將Xeon Phi的處理器數量擴增到128顆,最後得到的速度,相當於單顆Xeon Phi的50倍,藉此證明了這顆處理器的延展性。
發表會最後,Rajeeb Hazra也提到有許多伺服器廠商的產品,能支援Xeon Phi,包括Dell、HPE、Fujitsu、NEC、Supermicro、聯想、浪潮、中科曙光、雲達,我們在ISC大會展覽上,也看到永擎(ASRock)展出相關產品。
另外,對於英特爾參與由Linux基金會發起的OpenHPC計畫,Rajeeb Hazra也進一步闡述他們接下來要推動的Intel HPC Orchestrator,當中將會提供基於OpenHPC的系統軟體,而且是由英特爾所支援;同時,也將推出3套可立即使用的整合式產品,並提供組態調整彈性,而第一套產品預計今年第四季推出,由通路合作廠商提供,目前已有一些單位開始試用,包含OEM廠商、軟體供應商、系統整合商與HPC研究中心等。