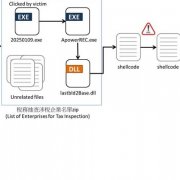
")
玉山銀行資訊處襄理洪采襄表示,資料分析人員必須讓資料分析更快速、有效率。像玉山是以資料倉儲作為資料集散中心,來滿足後續資料科學分析時的需求。(圖片來源/iThome)
每個人生活都很難脫離銀行,舉凡從戶頭中提領到第一份薪水、信用卡消費,以及車貸、房貸等大小事,都必須借助銀行的幫助,面臨未來金融科技FinTech、理專機器人,甚至軟體機器人Bot的競爭,銀行也得走向Bank 3.0的轉型之路。
目前正處於數位轉型階段的玉山銀行,近年已經開始利用大數據、資料科學,來分析全臺灣數百家分行,根據各區域擬定不同的經營策略,連只用54天就讓銀行核心系統上線的上海華瑞銀行CIO孫中東閃電來臺時,都指名要和玉山銀行見面。
身為玉山銀行資料科學團隊一員的玉山銀行資訊處襄理洪采襄表示,過去舉凡存錢、領錢、繳費等業務,大多必須仰賴實體分行,不過隨著行動裝置愈加普及,銀行所能觸及的業務範圍越廣,例如網路銀行、線上櫃臺,以及網路ATM,甚至是跨業合作、跨境金流、線上購物業者結盟。
凡走過必留下痕跡,消費者在銀行中一舉一動所留下的記錄,也都成為銀行發展業務的重要分析參考。
擁有如此大筆資料,對於資料科學家理應是喜事,「不過之後我們便開始苦惱了。」洪采襄表示,銀行旗下業務不僅繁雜,各自還有對應的業務系統,每套系統都對應到不同的開發人員、維護廠商。面對如此複雜內部系統產生的龐大資料,她表示,資料科學團隊不可能臨時才決定使用哪些資料來滿足特定分析需求,「光是整理、收集完所需資料得花的時間,大概就足以遭到老闆開除了。」
洪采襄表示,資料分析人員必須讓資料分析更快速、更有效率,玉山銀行就是用資料倉儲作為資料集散中心,來滿足後續資料科學分析時的需求。
玉山銀行資料處理4大步驟
一般來說,銀行內部資料倉儲彙集來自各業務系統的資料後,需先對資料進行ETL處理(Extract-Transform-Load,萃取、轉換及載入)。洪采襄表示,ETL程序包括四個步驟。第一是統一資料格式,例如像常見的日期資料,除了系統開發者或廠商不同,對於日期格式的呈現和記錄方式也都不一樣,如採用民國年或用西元年。在時序安排中,也有年月日、日月年、月日年等不同排列組合,「為了要讓資料分析人員更為便利,玉山銀行統一採用西元年,採年月日的方式呈現。」
第二步驟則是初步資料檢核,確保收集到的資料不會重複。像用戶身份證字號都是唯一值,就可作為判斷資料是否重複的檢查條件。洪采襄歸納2種常見資料重複的原因。一是行員手動輸入資料錯誤,而業務系統沒有查核。第二是,業務系統開發人員多次將同樣的資料存入資料倉儲中導致重複。為了避免出錯,洪采襄提醒,業務系統開發者要確認匯出,再者是資料邏輯轉換,她解釋,例如針對特定的業務需求,玉山銀行會事先進行資料邏輯轉換,將轉換後的成果儲存在資料倉儲,例如將顧客存款、基金、保險等不同類型的資產資訊改以顧客身分別彙整集中後,資料分析人員就可以在資料倉儲中查詢到特定客戶擁有的總資產數目。
不過,由於個資法的規範,洪采襄表示,雖然資料倉儲內有原始資料,但用於分析時,系統提供出來的資料,都會經過用戶個資去識別化處理,同時,玉山銀行也對嚴格控管使用分析軟體的使用者權限,與將所有操作過程用螢幕錄影來稽核。
最後一個階段才是依照資料科學團隊設計的資料模型,將資料匯入資料倉儲中。洪采襄認為,收集這些資料只是最基本的功夫,後續才可以產出報表、儀表板等視覺化應用,或是整理行銷名單給相對應單位來進行銷售活動。
資料梳理後才是挑戰的開始
收集如此多筆資料後,要如何利用資料科學,解決銀行的營運問題?洪采襄表示,經營銀行碰到的問題多如牛毛,像是思考顧客喜歡的通路形式,ATM設點位置、安排客服人員,或是衡量網路銀行使用狀況,評估未來是否能找到更多潛在顧客。
玉山銀行資料科學團隊目前有3大資料應用,第一是了解不同屬性顧客,在不同通路的使用狀況以及偏好。第二是剖析分行通路,了解它面臨數位轉型過程中,每一間分行是否存在獨特的特質。第三則是思考能否將目標縮小至單一消費者,能為不同顧客提供各自專屬的客製化服務。
分析不同用戶的跨通路使用習慣
第一層面著重於了解不同用戶在各通路的使用行為,以及他們對於通路的偏好為何。為了達成此目的,必須利用用戶在玉山銀行儲存的帳務資料以及客戶屬性。洪采襄解釋,帳務資料包含存款、貸款、每月刷卡金額,以及基金、理財投資等財富管理金額。顧客屬性資料則包含年齡、性別、職業,以及薪轉戶等資料。
而玉山銀行資料倉儲內有數百萬筆此類資料,她表示,玉山團隊使用了邏輯迴歸模 (Logistic regression model),來預測每一位顧客在不同通路中所使用的相對機率為何,例如ATM、分行、客服中心、行動銀行、以及網路銀行的使用機率。
經過比對之後,洪采襄得出了幾個有趣結論。像是頻繁使用者實體分行通路的用戶,通常是年紀長、存款數目高的使用者,「不過公教人員使用分行的比例較低。」她也發現除了網路銀行,其他通路大多得不到公教人員的喜愛。
根據此觀察,她認為,必須思考過去玉山銀行針對公教人員的行銷管道,大多是透過電話、EDM、DM,或是簡訊等較高成本的溝通渠道。在了解公教人員的使用習慣後,未來就可以直接將促銷方案放置於網路銀行平臺上,除了可以節省成本外,也能更直接地進行促銷。
而擁有較高資產的理財會員客戶,使用實體分行、客服中心的比例也都偏高。她解釋,理財會員大多喜歡透過行員、客服人員當面提供服務。
至於信用卡刷卡金額高的用戶,使用客服中心、行動銀行的機率都比較高。不過,客服中心礙於人力問題,提供服務的成本比起行動銀行要高。因此,透過此研究成果,玉山銀行可以先統計這類顧客經常打電話查詢的問題為何,再將這些資訊公告於行動銀行,「漸漸地將顧客引導至行動銀行上,藉此降低客服中心的人力成本。」
用數據了解不同分行的通路特質和差異
在比較過用戶跨通路使用行為以及偏好後,洪采襄發現分行的使用比例仍然偏高,而目前玉山銀行正處於分行數位轉型的階段,分行正面臨裁撤、轉型、合併,使得數量減少過程中,玉山銀行也得試圖降低對於客戶產生的影響。因此,玉山銀行資料科學團隊,從跨通路比較中,更進一步地深入分析各個分行特質間的差異。
就如比較使用者跨通路行為,解析分行特質也會使用用戶在玉山銀行的帳務資料,並且找出其使用頻率較高的分行進行分析。
假設某用戶在某一段時間內,總共使用了A分行10次、B分行3次,以及C分行3次,即可得知其最常與A分行往來。更進一步,也要了解最常前往該分行用戶的財務狀況,像是財務管理、刷卡、存款、貸款的額度等資訊。洪采襄表示,此類資料若用報表呈現,由於數據過多,不易從中判讀有意義的資訊。因此,資料科學團隊便將分行資料進行主成分分析,將多維度資料降級成二維度的資料,「這樣比較利於視覺化。」
-600-1.png)
用2維圖表呈現多維資料
玉山銀行將全臺灣分行一同進行比較,而各分行在顧客資產、顧客負債都有不一樣的表現。
洪采襄也指出,分析後可歸納出兩項主成分,第一種是偏向反應用戶資產狀況,包含存款、財富管理。第二種則是負債程度,可用來代表其負債面狀況,像是貸款、刷卡金額。多維資料降級二維資料後,資料科學團隊以客戶資產面作為橫軸,用戶負債程度作為縱軸,將各個分行數據納入來比較各自的特性。玉山銀行還將臺灣畫分為東、西、南、北四大區域,作為比較南、北差異或東、西部差異的另一個分類向度。
利用此圖,也能看出某些分行用戶持有較高資產,例如理財、存款。反之,某些分行用戶則擁有較多負債,像是信用卡消費、貸款需求。此圖中,洪采襄也發現,南北部分行的特質也頗符合傳統中的印象,例如,南部居民理財行為偏向保守,除了存款比例偏高外,也通常購買投資報酬較穩定的理財商品,而北部居民則較常利用信用卡購物,貸款需求也偏高。
不過,只用4大地理區域的比較,尺度仍舊太大。玉山銀行更進一步從縮小到地理區域中的特定行政區,進一步比較行政區內每間分行的特色。例如,洪采襄發現北部某行政區中的4間分行,有2間分行不論是客戶資產、負債數值表現都相當不錯,但是其餘2間,用戶的資產數目就表現較普通。她解釋,行政區內被畫分為商業區、住宅區,或是交通樞紐。而由於分行處於不同交通位置,導致各分行特性不同。
尋找鄰近相似特質的分行
除了分行的差異,玉山銀行也想要了解各分行間的相似程度。洪采襄表示,除了用二維圖表來分析外,玉山也利用分群技術,如根據存款、信用卡、貸款,以及財富管理等四構面,並且用顏色來呈現各分行之間的相似程度,來提供更直覺的視覺化呈現。
例如,若想要臺北將近30間分中,其中兩間的特性時,則在橫軸尋找A分行,縱軸則找到B分行,在相似度矩陣中尋找A與B的交集點。
若此交集點的顏色愈偏紅色,代表A、B的相似度越高。反之,如果交集點偏向黃色,相似度則比較低。此外,在相似度矩陣中,也可以利用分群,將特性相似的分行繪製在相鄰區域。
-600-2.png)
用顏色漸層反應相似度
玉山也用紅黃兩色漸層,將相似度視覺化。如在相似度矩陣中尋找A分行與B分行的交集。交集點的顏色愈偏紅色,代表A、B的相似度越高,反之,如果交集點偏向黃色,相似度則較低。
結合外部開放資料及內部營運資料
洪采襄表示,除了內部營運資料,玉山銀行也在思考是否還有其他資料能介接使用。恰好在2014年,前行政院院長毛治國祭出科技三箭:開放資料、大數據,以及群眾外包。她表示,在政府、民間團體協力下,政府開放資料也越來越步上軌道。因此,玉山銀行團隊主管丟給洪采襄一個難題:「銀行內部資料能否跟政府開放資料互相串接?」
洪采襄表示,目前玉山銀行只串接了兩種開放資料,包括了鄉鎮區總所得,以及鄉鎮區人口數的資料集。利用這兩個資料集,資料科學團隊就可以得知某一分行服務範圍內的總所得、總人口數,並且推算該分行用戶所得跟存款間的轉換率,以及分行在其地域的占有率。不過,首先要釐清玉山銀行在全臺灣136間分行,每一間的潛在服務範圍究竟有多廣。
洪采襄表示,透過空間分割法沃羅諾伊圖,將尺度範圍縮小,假設某行政區有數間分行,而該區的任一點,必定可以找到與它距離最近的分行,依此類推,計算該行政區內每點與分行的距離,資料科學團隊就可以細分每間分行的服務區域。
找出分行的服務區域之後,就可以計算分行潛在服務顧客的總所得情報。洪采襄舉例,像是A分行潛在服務範圍總共橫跨4個鄉鎮,按分行服務區在每個鄉鎮的面積比例作為加權參數,對這4個鄉鎮公開資料中的居民所得來加權計算,如A分行服務區只涵蓋甲鎮的面積40%,就把所得平均值乘以40%,如此算分行服務區的整體所得平均值,進一步乘以涵蓋人口數,就可得出A分行潛在服務範圍的居民平均總所得。再和A分行存款資料相比,就可以知道居民所得,和來玉山銀行存款的轉換率多少,來採取適當對策,如發現該行存款轉換率偏低,代表居民存款意願較低,則可以多推相關理財行銷方案,來提高顧客投資理財額度。
-600-3-V2.png) |
-600-4-V2.png) |
用空間分割法計算分行服務區
透過空間分割法沃羅諾伊圖,找到某分行的潛在服務範圍,假設某行政區有數間分行,而該區的任一點,必定可以找到與它距離最近的分行,反過來劃分出每個分行的服務區,進一步再找出全臺各分行的服務潛在範圍。
分析各分行營運狀況不佳的原因
除了計算分行潛在總所外,利用同樣加權平均概念,也可計算潛在可服務的人口數量。洪采襄舉例,若甲分行理論上應可服務10萬人,但是經常服務客戶卻只有2萬人,就可考慮要求甲分行應該要更努力地吸引客戶,不過也可能是同一個行政區中,同業競爭者比玉山銀行來得更有吸引力,就得另外找對策。
此時,資料科學團隊也能夠尋找距離甲分行最近的數間分行,比較甲分行與他者的相似度為何。洪采襄舉例,如甲分行才剛成立不久,消費者通常習慣前往以前的分行,因此才導致該行的存款數量不足。
或是比較同區域的分行,觀察到乙分行表現特別好,這時可能因為該分行位於商業區,客戶前往該地的難易度較低,導致其業績勝過其他分行。
可用來預測顧客特質,量身打造促銷方案
從比較用戶在跨通路行為,到各區域分行的異同,最後玉山銀行則要將分析單位縮小至每一個消費者,在了解不同用戶習慣、特質後,推出客製化服務,這時候信用卡的消費明細紀錄就可以派上用場。
洪采襄表示,由於消費明細的資訊過於複雜,包含日期、地點、金額等資料,所以得先簡化,例如玉山只選定旗下顧客最常光顧的1萬間商店作為標的,再用二進度來呈現消費情況,1代表有,0是沒有,標記出一位顧客有無在這一萬多家商店中消費的記錄。
不過,每一位消費者的購物記錄是長達1萬個字元的字串,「這樣的變數分析還是相當困難。」因此,玉山團隊再用主成分分析方法,來降低變數的維度,搭配邏輯迴歸分析,藉以預測顧客身份,像是性別、職業,或是VIP會員等。
洪采襄舉例,當A明細記載著該消費者往往在加油站、3C購物商場消費時,按照常理推斷,很容易聯想到該消費者的性別為男性。反之,當B明細多記載藥妝店、百貨公司的消費記錄時,亦可以推斷該用戶為女性。
-600-5.png)
用分群分析顧客消費特性
當左邊明細記載著該消費者往往在加油站、3C購物商場消費時,按照常理推斷,很容易聯想到該消費者的性別為男性。反之,當右邊明細多為藥妝店、百貨公司的消費記錄時,亦可以推斷該用戶為女性。
再者,許多和玉山銀行往來的公教人員,使用國民旅遊卡的比例偏高,所以當一個消費明細中,出現許多相關特約商店如福華大飯店、臺灣中油、農會時,也可以推斷其極為可能是公教人員。
最後則是理財VIP會員以及高資產會員,其消費大多集中在保險投資、海外旅遊、房地產,以及奢侈品,「因此,只要分析玉山銀行的消費明細,就可以猜到顧客的特質。」目前在性別預測上,玉山銀行可以達到將近9成(88%)的預測水準,而是否為公教人員、理財VIP的預測正確率也都突破了8成。
在了解各個消費者特質後,玉山銀行也可以給予不同的客製化服務。洪采襄表示,像是近年相當流行分析用戶點擊行為。若可以藉由點擊行為鎖定特定客戶,即可以推薦適合的行銷方案。她舉例,若該用戶經常常常點擊匯率、旅遊平安保險的按鍵,此時就可以推測他是否有旅遊需求,以提供相關刷卡零利率的優惠方案。
熱門新聞

2025-03-03
2025-03-03

2025-03-05


2025-03-05