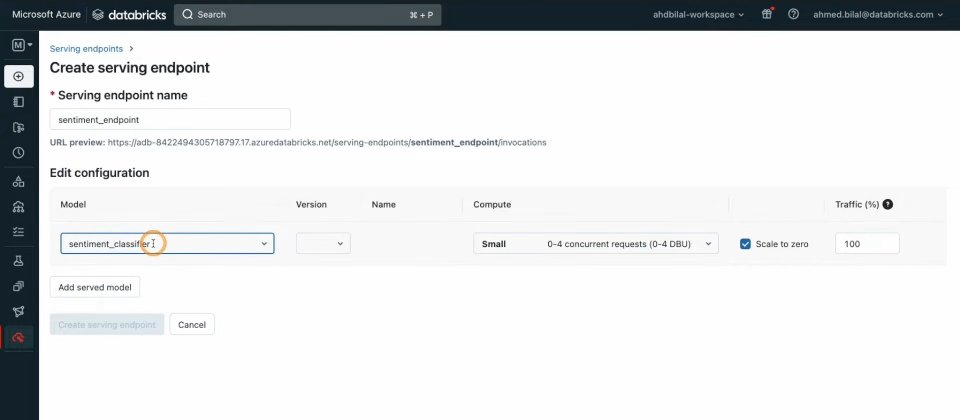
Apache Spark技術團隊所成立的新創Databricks正式推出Model Serving,這是一項無伺服器機器學習模型服務,透過將模型部署在湖邊小屋(Lakehouse)就近整合資料,用戶可以利用REST API存取模型,以快速建構包括個人化建議、聊天機器人和詐騙偵測等即時機器學習應用程式。
不少企業希望在應用程式添加機器學習技術,提供創新服務,但Databricks提到,即時機器學習系統需要快速可擴展的服務基礎架構,不只需要專家知識建立和維護,也需要進行監控、自動部署和模型再訓練等工作,這對企業來說是一大挑戰。
透過API提供機器學習服務則有助克服此挑戰,Databricks模型服務將模型部署於資料和訓練基礎設施旁,以進一步簡化用戶在機器學習生命周期管理工作。模型服務建構在Databricks湖邊小屋服務之上,使資料和人工智慧整合至同平臺,提供一個無伺服器解決方案,供企業以整合工具的方式添加機器學習技術,加速創新應用開發。
用戶不需要考慮底層,由Databricks處理基礎設施的可擴展性,以及版本相容性和程式修補,且模型服務能夠原生與各種服務整合,用戶在單一平臺就能管理資料擷取、訓練、部署和監控整個機器學習工作流程,掌握模型生命周期整體情況。
模型服務整合Databricks特徵商店,而特徵商店是一個方便查詢和共享特徵的集中式儲存庫,用戶可在訓練期間定義一次特徵,之後便由Databricks自動擷取並聯合相關特徵,以完成推論工作負載。Databricks模型服務還整合MLflow自動部署模型,用戶只要提供模型,MLflow便能自動準備容器,並將其部署成無伺服器服務。
熱門新聞
2024-04-29
2024-04-29
2024-04-28

2024-04-29
2024-04-26
2024-04-26

2024-04-27