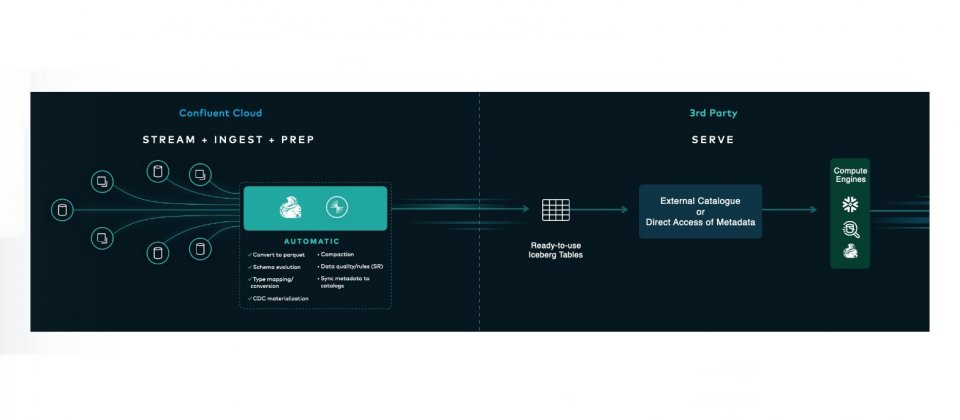
企業級Kafka平臺Confluent推出新解決方案Tableflow,其目的在於簡化將Apache Kafka串流資料轉換為Apache Iceberg表格,用於資料湖、資料倉儲和分析引擎的過程。Tableflow能夠一鍵將Kafka主題和相關架構轉換成Iceberg表格,省去過去分析營運資料所需要的繁瑣過程。
Confluent強調,Iceberg逐漸成為資料分析領域中,資料表格式的開放標準。不同的計算引擎和資料湖倉能夠透過Iceberg,簡單地存取和處理資料,進而支援靈活且開放的資料架構。雖然企業的營運和分析兩大領域,需要存取相同的資料,但是不同存取方式的需求,導致組織需要重複執行同樣的工作,像是將應用程式串連起來,資料再經過ETL流程轉移到資料湖倉中。
因此營運和分析領域之間更方便的資料流動和轉換,成了企業重要的需求之一,而Tableflow的出現,便是要統一營運和分析領域的資料處理,使Confluent用戶可一鍵將Kafka和相關架構轉換為Iceberg表格,使得將串流資料存放進資料湖倉的過程更加簡單。
Tableflow運用了Kora儲存層創新技術,將Kafka片段寫入為Apache Iceberg底層儲存格式Parquet。而在後臺,Tableflow使用了一個新的後設資料轉換器(Materializer)連接Confluent架構註冊表,生成Iceberg後設資料,同時處理架構映射、架構演變和類型轉換等工作。讓用戶不需要手動映射。
資料品質規則會在上游強制執行,不相容的資料在源頭就會被拒絕,並且可在開發中簡單地被偵測出來。用戶的資料產品可以進入自家的資料湖倉,並且以串流和表格等方式存取。除了架構管理之外,Tableflow還會持續將串流資料產生的Parquet小檔案,壓縮轉換成更大的檔案,也維持良好的讀取效能。
目前透過Iceberg REST目錄就可以存取Iceberg表格,使用者只要複製Iceberg REST目錄端點,並使用Confluent Cloud API金鑰和機密作為憑證,並將其傳遞給Iceberg相容的運算引擎即可。Tableflow的初始版本會將資料儲存在Confluent Cloud中,之後官方會允許用戶選擇將Iceberg後設資料和Parquet檔案儲存在自己的物件儲存中。現在Tableflow還處於早期階段,想嚐鮮的開發者可以申請搶先體驗。
熱門新聞
2024-04-29
2024-04-29
2024-04-28
2024-04-26
2024-04-26
2024-04-26
")
2024-04-26