GitHub
Hadoop企業版發行商Cloudera與Google共同宣布,Google的大資料分析雲端平臺Dataflow的程式開發模型搬上Apache Spark資料處理引擎,且開源授權免費釋出。
可在Spark上執行將有助於Spark和Google生態體系的成長,且Google產品經理William Vambenepe在官方部落格也表示,Google期待也看好未來Dataflow生態體系的發展。
Google在2014年的Google I/O大會上投下震撼彈,Google技術架構資深副總裁Urs Hölzle宣布,Google不再使用MapReduce。同時,Google也發表了雲端Dataflow平臺,提供開發者完整的資料處理管道(Pipelines),可與BigQuery互通,被視為取代MapReduce的PB級分析技術。
而Google和Cloudera攜手合作,將Google Dataflow搬上Spark,來加速大量資料在雲端環境的分析,Google在Google雲端平臺部落格表示,目前有3種工具(Runner)允許Dataflow程式在不同的環境執行,包含了直接管道(Direct Pipeline)、Google大資料分析雲端平臺Dataflow,以及大資料分析工具Spark。
其中直接管道是開發者可以在直接本地端機器的程式上執行Dataflow程式。Google雲端Dataflow服務則是管理Google雲端平臺上Dataflow程式的執行環境,使用者可以透過Google雲端Dataflow部署程式在Dataflow平臺,不過,目前此服務還在Alpha(α)階段測試,只有少數的使用者可以進行測試。而Spark則允許在雲端或本地端環境且相同的Dataflow程式在Spark叢集上執行。
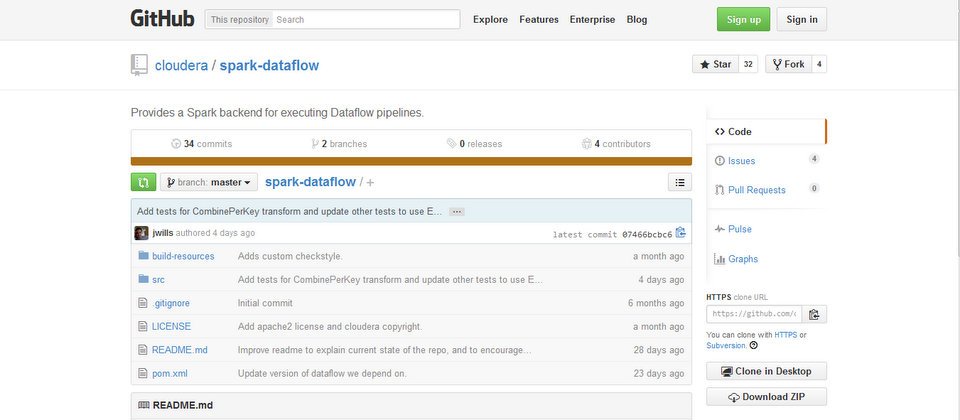
目前,Spark的版本已可在GitHub上取得,Cloudera在官方部落格表示,Google雲端Dataflow在Spark上執行是個在Cloudera實驗室孕育的新專案,且Google也表示,目前該服務還在Alpha階段測試,所以企業若想應用在正式上線環境(Production)就得要自行承擔風險。
另外,Spark在去年11月的Sort Benchmark Competition(資料排序基準競賽)中,僅以不到30分鐘就完成排序多達100 TB的資料量,打破了Hadoop 72分鐘的世界記錄。Spark最終約費時23分鐘,完成排序100 TB的資料量,約為1兆筆資料,意即Spark平均每分鐘可以處理排序4.27 TB的資料量。
熱門新聞

2024-12-24


2024-12-22

2024-12-20

2024-11-29

2024-08-14
