
In-Memory已成為近期最熱門的巨量資料技術,Apache Spark憑藉其特有的資料封裝操作框架RDD以及In-memory資料儲存技術,解決傳統MapReduce框架在迭代式演算法中所遇到的效能瓶頸。基於Spark框架上,有許多擴充模組,包含以SQL指令操作資料的SparkSQL、豐富的機器學習函式庫Mllib以及即時串流處理技術Spark Stream等足以覆蓋巨量資料90%的處理需求。
為了滿足業界需求,資策會特規劃「Spark巨量資料分析實務班」課程,本課程將學習Hadoop儲存系統與資源管理框架及Spark In-Memory巨量資料相關關鍵技術,藉由實際案例操作,讓學員能夠了解Spark核心技術、SparkSQL操作方式以及巨量資料應用程式實際開發與效能調教。並將透過實際分組演練真實數據,了解資料處理時可能會面臨的狀況。
12/30前報名享早鳥優惠,詳細相關資訊請參閱課程網頁http://www.iiiedu.org.tw/ites/SPARK.htm,或來電洽詢(02)6631-6533,黃小姐。
熱門新聞
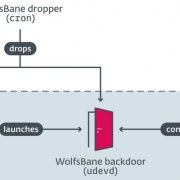
2024-11-22

")
2024-11-15
與CNCF推廣大使太田航平(圖左)來臺在K8s Summit中分享K8s未來發展方向,提到要聚焦雲端永續性的發展,讓企業可以透過新工具在雲原生環境中觀察、記錄並評估碳排放。")
2024-11-15

2024-11-22

2024-11-24


2024-11-22
Advertisement