不論是個人或企業,每天都在面臨許多作決定的時刻,而要做出好的抉擇,我們需要有充分的資訊,才能做出不讓自己後悔的判斷,但在現實生活裡面,由於很多因素的影響,往往我們只能獲得有限的資訊,再依此判斷該怎麼做,這樣受到種種局限的決策方式,甚至被自己或他人的主觀經驗蒙蔽,因此,最後的決定經常會導致出人意表的結果,而無法真正做到運籌帷幄。
難道不能用更科學、更有憑有據的方法,來面對這樣進退兩難的處境嗎?要達到這樣的理想,我們需要更多資訊來進一步分析、找出對策,而且不是只靠局部或片段的資訊,而是盡可能透過「全部的」資訊來做分析,才能避免一開始分析時,其實就已經註定判斷失準的結局。
用全部的資訊來分析,有可能嗎?是的,基於當前這個時代所發展出來的種種技術,是非常有可能完成這樣的工作,而且許多原來需要投入的軟硬體成本已經大大降低,技術發展上也已經成熟不少,甚至有許多非常經典的實例已經出現。
例如Google透過分析所有用戶的特定關鍵字搜尋記錄,而準確地預測了2009年的流感爆發,此外,像是Amazon的書籍推薦系統、Wallmart懂得在颶風前促銷小甜點,以及紐約市解決人孔爆炸採取了預測方式找到問題點。
至於臺灣呢?
先前我們在大資料3部曲之1,所提到的幾個例子,大多是針對如何具備快速處理大資料的能力,例如振鋒公司、元富證券都是透過導入記憶體式資料庫(In-Memory Database)的技術,來達到這樣的效能要求,也有一些政府單位開始採Hadoop,例如國網中心在2009年推出了公用Hadoop資料探勘實驗叢集,後來也發展出入侵偵測雲端分析系統。
這樣看起來,大資料的應用似乎只是用來被動地因應大量、即時的資料處理需求,或是作為雲端運算平臺,但事實上,不盡如此。
因為,IT應用系統既然已經可以負荷得了越來越多的資料,接下來你要思考的是,這意味著,過去不容易辦到、需要花大錢擴充軟硬體,才能及時完成的大量資料分析應用,如今,可以基於這樣低成本的大資料處理平臺來發展。
大資料可應用到各種層面
看看國外的大資料應用實例,除了讓人嘖嘖稱奇之外,回頭看看臺灣,不免讓人覺得汗顏。例如,以幾家居龍頭地位的網路購物業者來看,過去這幾年以來,似乎很少有人願意將發展重點放在推薦系統的改良上,讓大多數民眾有印象的服務還是到貨時間的縮短或是交易機制的便利性,而不是在這些網站瀏覽購物時,因為站方的貼心推薦,而覺得被吸引、進而決定購物。於是,如果說到讓人印象深刻的推薦系統,我們多數人首先想到的都是Google的網路廣告,或是Facebook的好友推薦,都不是國內業者所提供的服務。而要提供精準、貼心的顧客推薦功能,背後需要有強大的資料收集、處理與分析能力作後盾,無法憑空猜測。
有的網購業者對於提升這樣的分析能力,不只是有所覺悟,而且是開始有明顯積極的動作。
例如,最近我們看到旗下有東森購物網、森森百貨網的東森國際,已經開始正式對外招募資料科學家,甚至主辦了號召學子參與的校園資料分析競賽。同時,該公司董事長接受媒體採訪,表示他們已經委託SAS和精誠/Etu等廠商,協助建構相關功能。若是在網購相關服務的部份能成功導入大資料應用分析技術,可望將臺灣的網購服務等級提升到新的境界。
這是消費性議題上的應用,那麼民生呢?今年2月舉辦的智慧城市展中,臺北自來水事業處獲得2014智慧城市創新獎,這不免讓人想到多年以來,我們偶爾在新聞看到全臺自來水管漏水率偏高的問題,根據一些媒體的報導,2012年臺灣的漏水率是19.55%,因此浪費掉的水量有6.09億噸之多,相當於1.8座翡翠水庫。
這幾年以來,除了經濟部水利署、台灣自來水公司之外,全臺有越來越多的大城市注意到相關的問題,紛紛尋求解決之道。
要解決這問題有很多種方法,有些單位已經開始行動,例如,今年台南市政府已考慮裝設電子水表來偵測漏水情況,而有些廠商,像是IBM、HDS則提出用大資料分析的方式,來協助找出破損風險最高的水管,其中他們會透過預測模型來識別這些可能壞掉的水管,而且據說已經有實際的例子。
諸如此類的大資料應用技術,所帶來的效益相當高,因此,未來,臺灣官方和民間採用的例子,應該會越來越多。
看得見的問題容易被正視,而對於看不見的問題,需要透過資料分析來突顯
上述這些例子所面對的問題,其實都是屬於受到許多人關注而會被突顯的情況,但如果是既有的環境下所看不見的問題,那又如何?你只能靠資料證明這個事實存在。
例如,如果你經營的是一個提供線上購書的網站平臺,如何界定你的客戶群作促銷?當你打算分析的網站資料來尋求目標時,是否常因為資料太多、太大了,所以只好針對特定的項目來檢視?而決定這些項目的關鍵,經常是憑藉個人的主觀經驗。
但這樣會不會有盲點?
來自網路的使用者,虛無飄渺,對於願意登錄會員資料的人,你可以透過儲存在系統中的資料庫來描繪他們的意向和喜好,但如果是非會員呢?你所能收集到的恐怕只有對方使用的作業系統平臺、瀏覽器類別等資訊吧!
如果你的資料分析無法涵蓋到這群人,是否表示你只能做會員的生意,對於非會員的用戶拿不出吸引他們的辦法,如果你沒有將所有能掌握的資料,全部放到你的分析模型裡面,很可能就根本無法提出對策。
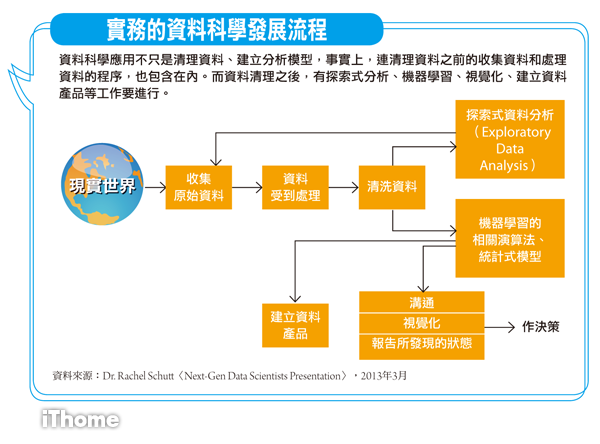
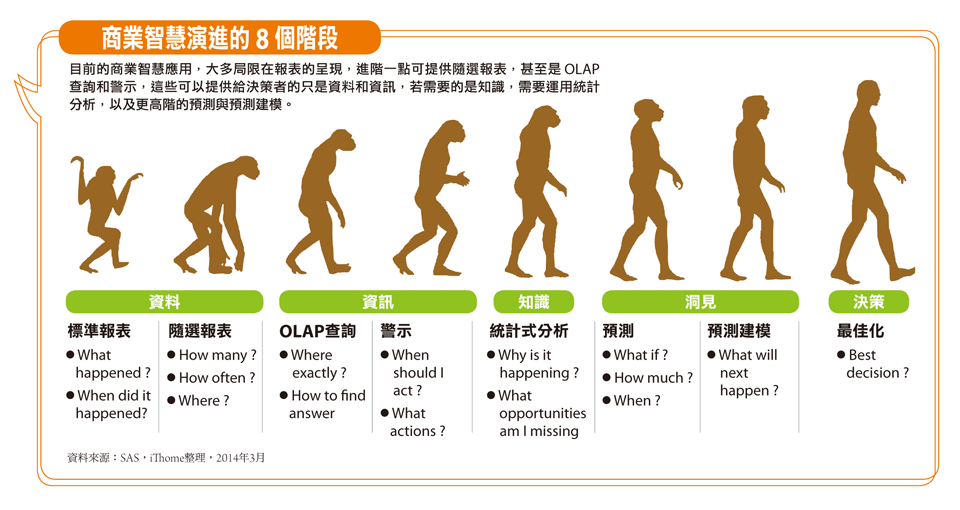
類似的狀況你該怎麼辦?首先,你當然要想辦法拿到所有可能提供相關資訊的資料,所以先解決收集資料的需求;其次,是你要能夠轉化這些格式不同的資料,成為後續分析可以進一步運用的素材;最後,你可以透過視覺化的方式,將分析結果,透過圖表的形式,以較簡單易懂的方式呈現出來。而要快速完成這些工作,Teradata大中華區Aster與Hadoop事業部總監孔宇華認為,可以仰賴資料科學家來協助。
而資料科學家所做的這些事情,會比傳統的商業智慧應用,提供更深入的分析結果,不只是告訴你What,而且更有機會回答How和Why等問題。同時,在分析作業上也更趨於主動,不像過去的商業智慧應用,後來逐漸走向被動。
孔宇華說,因為所能處理的資料來源更多,不只是抽樣,而且花的時間更短,最重要的是,發現的價值更大。這些因素的成立,都讓資料科學應用越來越受到重視。
除了這些,今日的資料科學存在的必要性,也在於它能做到比過去更細微的分析,SAS臺灣區銷售顧問暨經銷業務部副總經理高芬蒂說,目前每一家公司的產品服務之間的競爭,經常會面臨到彼此相似度很高的窘境,如果想要做出差異化,高人一等僅能在細微處下功夫,而這需要透過結合數學統計的進階資料分析來協助。
資料科學家是驅動資料科學運用的關鍵人物
很多公司其實本身都有一些人員在分析資料,那他們是資料科學家嗎?或者可成為資料科學家嗎?其實,表面上擔任分析人員的角色,但實際上只是作報表。
一個資料科學家怎麼看待這樣的工作領域?中央研究院資訊科學研究所副研究員陳昇瑋,他本身專精於網路效能、使用者滿意度、網路安全、線上遊戲等領域,因為多次以〈資料科學家未曾公開之資安研究事件簿〉為題演講,對這方面的實務經驗也有很深的體認。他強調,資料科學家必須有一定的獨立空間去探索資料價值,而且,至少要有30%、40%的獨立性,如果資料科學家的日常工作,很緊密結合在公司業務流程裡面,都是依據公司的業務需求來作分析,他會很難有所發揮,會沒辦法產生新的價值。
陳昇瑋覺得探索未知這項工作,不能放到企業的流程裡面去,因為那就變成在管資料,跟企業既有管資料和分析資料的人沒有差異了。
他說,「如果你的需求都是人家告訴你的,你就不是一個資料科學家。」因為科學家這樣的工作,本來就有探索、研究的味道,「你不讓他Re-Search,他怎麼會有空間去研究」,所以,沒有獨立的空間來做這項工作,就不能稱之為資料科學家。
對於這點,104人力銀行研發處資深經理李魁林也很認同,他說,科學家,就是要探索未知的事情,他在解決一些他不知道的問題,不管是從探索或解決問題的角度。
李魁林強調,過去做事情的方式,都是有人告訴你一個任務,很明確,你去注意它就好了,但是,在資料科學家這個腳色上,他只能靠自己去找到任務和解法,對方通常只能告訴他有這些資料可以分析,但有時候,甚至連取得資料的過程,都需要靠資料科學家協助。例如,若要收集許多記錄檔來處理、分析,資料科學家可能連要記錄的格式,可能都要協助事先定義,一般IT人員可能不會去刻意做這些事情。
不過,在目前臺灣企業的實際環境中,資料科學家可能很難不受到公司的營運需求所影響。而且,更現實的問題是,企業要找到十八般武藝樣樣精通的資料科學家,仍然非常困難,因此像是104人力銀行和趨勢科技的作法,他們現實遇到的狀況是,找不到滿足所有資料科學家技能需求的人,都會傾向成立資料科學家團隊的方式來因應。
李魁林說,他們透過團隊合作的方式,因為資料科學面對的範疇複雜,單靠一個人要具備這麼多不同能力,其實是很困難的,但他們可以做到的是:讓每個人在一個領域很專精,其他人也涉獵一些這個領域的相關知識,彼此互補。
趨勢科技研究開發部協理黃懷德說,在他們公司一樣會遇到類似狀況,因為不是人人都有辦法同時精通資料採礦、機器學習等技術,他們會透過調度人力的方式來支援這樣的專案。
而研究資料的任務都是由資料科學家啟動嗎?黃懷德說,他們自己會提需求,有些會來自產品研發,也有一些來自老闆給予的方向,他強調,團隊所做的研究,絕對不是漫無目的地研究某種技術,會先設定想解決的問題是什麼。
因為他認為就像《與成功有約》一書中所提到的,要「Begin with the end in mind」,先去想想要達成的目標,接下來,再去規畫要做的事情。這意思是,當團隊看到問題發生了,而且需要解決,除了設定去解決之外,也要往前回推,需要取得那些資料,需要調整分析模型,然後再去看能否解決。
成立資料科學家團隊
在臺灣,要找到一個十全十美的資料科學家來主持分析作業,可能是一個難以達成的夢想,所以,你可以像上述兩家公司一樣,透過組成資料科學家團隊的方式,來達到目的,可能比較務實。
陳昇瑋說,一個資料科學家團隊可以包含:該業務領域的專家、資料科學工程師(Data Science Engineer)、統計學家或分析師,這三種人員當中,如果其中有人能夠逐漸掌握到其他兩部分的專業,他就可以升格了。
事實上,他看到目前如果企業要找到上述三種人,可能連資料科學工程師都很難找到,但這職務所需的能力,還有機會透過一些教育訓練的機構,例如資策會來養成,但如果是統計學家和分析師,是更難培養,因為對於資料的洞察力、對數字的敏感度,可能除了後天的努力之外,還需要一點天份。
因此他認為最好切入資料科學應用的方式,可能是先培養資料科學工程師。而除了直接找已經受訓的人來擔任該項職務,另一種養成資料科學工程師的方法,陳昇瑋的建議是,可以先將管理資料庫系統的工程師轉型成資料科學工程師,但他的工作不是管資料庫系統,而是管「資料」,資料來源、存放方式、如何取出,都由這樣的角色來全盤監督控管,而且這些資料要夠「大」,等到他駕輕就熟之後,若能再往視覺化分析應用延伸,懂得去解釋所看到的分析結果,這樣,其實已經相當不錯了。
所謂的資料科學家,你一定要給他一些空間去探索資料的價值。沒有獨立性就不可能產生價值。——中央研究院資訊科學研究所副研究員陳昇瑋