
毫無疑問,ASCII是電腦產業中最重要的標準,但即使從一開始,它的缺陷也很明顯。最大的問題是,美國資訊交換標準代碼太美國化了!事實上,ASCII甚至不適合其他主要語言是英語的國家。
當微軟的Windows首次發布時,它支援ASCII的擴展,微軟稱之為ANSI字符集,儘管它實際上並沒有得到美國國家標準協會(American National Standards Institute)的批准。
ANSI字符集之所以流行,是因為它是Windows的一部分,但它只是幾十年來定義之ASCII的眾多不同擴展之一。為了區分它們,它們被賦予了不同的數字和其他識別符。Windows ANSI字符集成為了國際標準組織的標準,稱為ISO-8859-1或Latin Alphabet No. 1(拉丁字母表1號)。當這個字符集本身被擴展到包含代碼80h到9Fh的字符時,它被稱為Windows-1252(如下圖)。
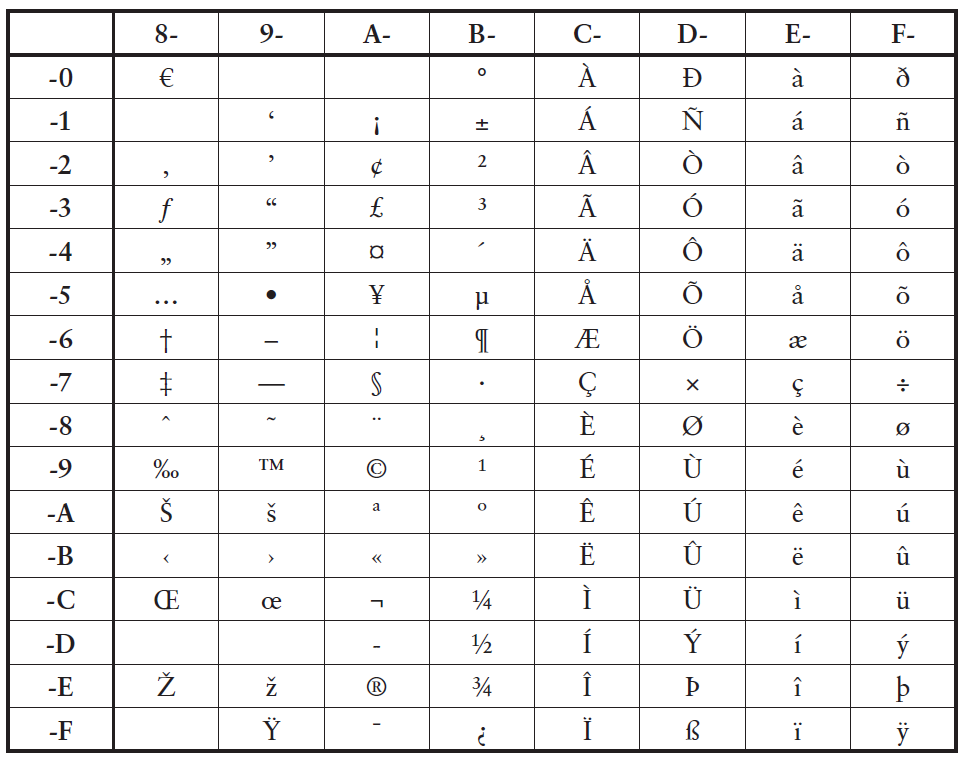
數字1252稱為代碼頁識別符(code page identifier),該術語起源於IBM,用於區分EBCDIC的不同版本。各種代碼頁與「需要自己的重音字符甚至整個字母表(如希臘文、西里爾文和阿拉伯文)的國家」相關聯。為了正確呈現字符資料,有必要知道所涉及的代碼頁。這在網際網路上變得至關重要,因而需要在HTML檔案之頂部的資訊(稱為標頭)指出建立網頁的代碼頁。
ASCII還以更激進的方式擴展了對中文、日文和韓文之表意文字的編碼。在一種被稱為Shift-JIS(日本工業標準)的流行編碼中,代碼81h到9Fh實際上表示了一個2位元組(2-byte)字符代碼(character code)的初始位元組(initial byte)。透過這種方式,Shift-JIS允許大約6000個額外字符的編碼。不幸的是,Shift-JIS並不是唯一使用這種技術的系統。還有三個標準的雙位元組字符集(double-byte character sets或DBCS)在亞洲開始流行。
存在多個不相容的雙位元組字符集只是其問題之一。另一個問題是,某些字符(特別是普通的ASCII字符)由1位元組代碼(1-byte codes)來表示,而數千個表意文字由2位元組代碼(2-byte codes)來表示。這使得處理此類字符集變得很困難。
如果你認為這聽起來像是一團糟,那麼你並不孤單,所以是否有人可以想出一個解決方案?
ASCII 的替代方案
假設最好只有一個適用於世界所有語言之明確的字符編碼系統,幾家主要的電腦公司於1988年聚集在一起,著手開發了一種名為Unicode的ASCII替代方案。ASCII是7位元代碼,而Unicode是16位元代碼(至少在最初的設想中是這樣的)。在其最初的設想中,Unicode中的每個字符都需要2個位元組,字符代碼的範圍從0000h到FFFFh,代表65,536個不同的字符。這被認為足以滿足世界上所有可能用於電腦通訊的語言,並有擴展的空間。
Unicode並不是從頭開始的。Unicode的前128個字符(代碼0000h到007Fh)與ASCII字符相同。此外,Unicode代碼00A0h到00FFh與ASCII的Latin Alphabet No. 1擴展相同。其他世界性的標準也被納入Unicode。
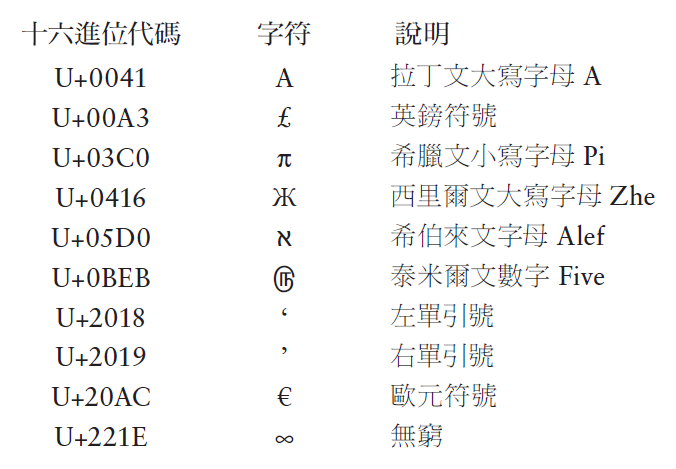
儘管Unicode代碼只是一個十六進位值,但指示它的標準方法是在值前面加上大寫的U和加號。以下是一些具有代表性的Unicode字符。
但是,從8位元字符代碼遷移到16位元代碼會引發問題:不同的電腦將以不同的方式讀取16位元值。例如,考慮這兩個位元組:20h Ach
有些電腦會將該序列讀取為16位元值20ACh,即歐元符號的Unicode代碼。這些電腦被稱為大端(big-endian)機器,這意味著最高效的位元組(大端)是第一個位元組。其他電腦則是小端(little-endian)機器。小端機器則會將該值讀取為AC20h,這在Unicode中是韓文字母表中的갠字符。
為了解決這個問題,Unicode定義了一個稱為「位元組順序標記」(byte order mark或BOM)的特殊字符,即U+FEFF。它應該被放在內含16位元Unicode值之檔案的開頭。如果檔案中的前兩個位元組是FEh和FFh,則檔案處於大端序(big-endianorder)。如果它們是FFh和FEh,則檔案處於小端序(little-endian order)。
1990年代中期,正當Unicode開始流行的時候,有必要超越16位元,以包含那些已經滅絕、但出於歷史原因仍有必要使用的字母,以及許多新符號。其中一些新符號是那些被稱為表情符號(emojis)之流行和令人愉快的字符。
撰寫本文當時(2021年),Unicode已擴展為21位元代碼,其值的範圍為U+10FFFF,可能支援超過100萬個不同的字符。以下是16位元代碼未納入的幾個字符。

將表情符號(emojis)納入Unicode可能看起來很無聊,但前提是你認為在簡訊中輸入的表情符號,在接收者的手機上顯示成完全不同的內容,是可以接受的。這可能會導致誤解,而且關係可能會受到影響!
最重要的Unicode轉換格式:UTF-8
當然,人們對Unicode的需求是不同的。特別是在呈現亞洲語言的表意文字時,有必要廣泛使用Unicode。其他文件和網頁的需求就比較小了。許多人可以用普通的舊ASCII來做。因此,已經定義了幾種不同的方法來儲存和傳輸Unicode文字。這些格式被稱為「統一碼轉換格式」(Unicode transformation format或UTF)。
最直接的Unicode轉換格式是UTF-32。所有Unicode字符都被定義為32位元值。每個字符所需的4個位元組可以按小端序或大端序進行指定。
UTF-32的缺點是它佔用了大量的空間。包含《白鯨記》內容之純文字檔的大小將從ASCII的125萬位元組增加到Unicode的500萬位元組,但Unicode僅使用32位元中的21個位元,每個字符都會浪費11個位元。
一個折衷方案是UTF-16。使用這種格式,大多數Unicode字符被定義為2個位元組,但代碼高於U+FFFF的字符則被定義為4個位元組。在最初的Unicode規範中,從U+D800到U+DFFF的區域並沒有被指定用於此目的。
最重要的Unicode轉換格式是UTF-8,它現在已經在整個網際網路上被廣泛使用。最近的一項統計表明,97%的網頁在使用UTF-8。這已經是你想要的通用標準。古騰堡計劃的純文字檔案都是UTF-8。預設情況下,Windows的Notepad和macOS的TextEdit係以UTF-8格式保存檔案。
UTF-8是靈活性和簡潔性之間的折衷方案。UTF-8的最大優點是它向後相容ASCII。這意味著,一個僅由7位元ASCII代碼組成的、以位元組儲存的檔案會自動成為UTF-8檔案。
為了實現這種相容性,所有其他Unicode字符都以2、3或4個位元組來儲存,這取決於它們的值。下表總結了UTF-8的運作原理。

對於第一行中所示之代碼範圍,每個字符都是由第二行中所示的位元數來唯一標識。然後,這些位元以1和0為前綴,如第三行所示,形成一個位元組序列。第三行中之x的數量與第二行中的計數相同。
第一列表明,如果字符來自7位元ASCII代碼的原始集合,則該字符的UTF-8編碼是0位元後跟這7個位元,與ASCII代碼本身相同。
Unicode值為U+0080及更大的字符,需要2個或更多位元組。例如,英鎊符號(£)是Unicode U+00A3。因為此值在U+0080和U+07FF之間,所以UTF-8運作原理表的第二列指出它是用2個位元組之UTF-8編碼的。對於此範圍內的值,只需使用最低效的11個位元來導出2位元組編碼,如下圖所示。
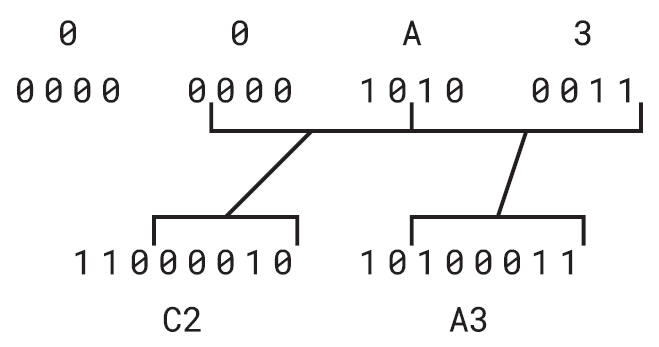
Unicode值00A3顯示在圖的頂部。四個十六進位數字中的每一個對應於數字正下方顯示的4位元值。我們知道該值為07FFh或更小,這意味著最高效的5位元將為0,可以忽略它們。接下來的5位元以110開頭(如圖底部所示)形成位元組C2h。最低效的6位元以10開頭,形成位元組A3h。
因此,在UTF-8中,C2h和A3h這兩個位元組代表英鎊符號£。需要2個位元組來編碼基本上只有1個位元組的資訊,似乎有點可惜,但對於UTF-8的其餘部分來說,這是必須的。
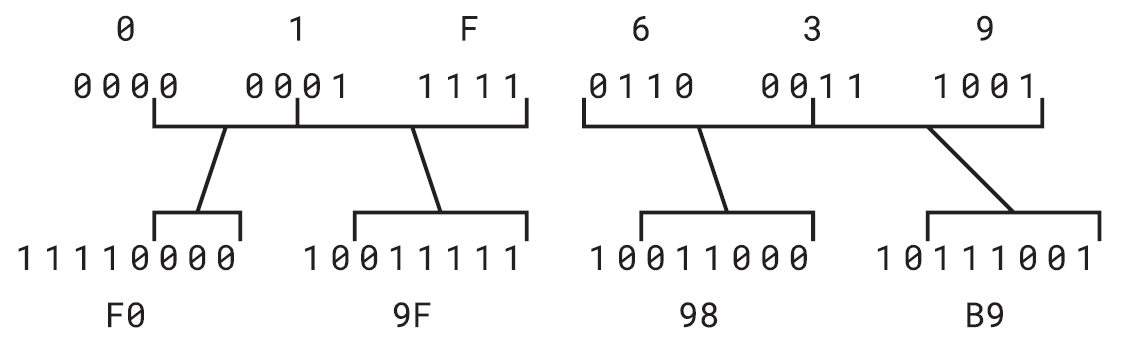
下面是另一個例子。希伯來字母א(alef)在Unicode中為U+05D0。同樣,該值介於U+0080和U+07FF之間,因此使用UTF-8運作原理表的第二列。這與£字符的過程相同。
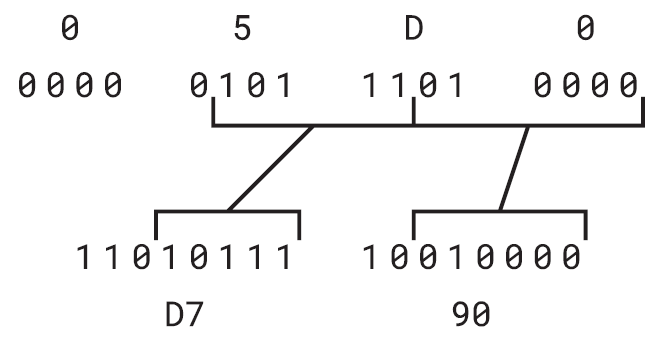
值05D0h的前5位元可以忽略;接下來的5位元以110開頭,最低效的6位元以10位開頭,形成UTF-8位元組D7h和90h。
無論圖像的可能性有多大,帶有喜悅之淚的貓臉表情符號是由Unicode U+1F639來表示的,這意味著UTF-8將其表示為4個位元組的序列。下圖顯示了如何從原始代碼的21個位元來形成這4個位元組。
透過使用不同數量的位元組來表示字符,UTF-8破壞了Unicode的一些純度和美感。過去,這樣的方案與ASCII一起使用會引起問題和混亂。UTF-8並非完全不受問題影響,但它的定義非常明智。當一個UTF-8檔案被解碼時,可以非常精確地識別每個位元組:
•如果位元組以0開頭,則它只是一個7位元ASCII字符代碼。
•如果位元組以10開頭,則它代表一個多位元組字符代碼(multibyte character code)之位元組序列的一部分,但它不是該序列中的第一個位元組。
•否則,位元組至少以兩個1位元(two 1 bits)開頭,並且是多位元組字符代碼(multibyte character code)的第一個位元組。這個字符代碼的總位元組數,由第一個位元組上第一個0位元之前,以1位元開頭的位數來表示。這可以是兩個、三個或四個。
讓我們再試一次UTF-8轉換:右單引號字符為U+2019。這需要查閱UTF-8運作原理表的第三列,因為該值介於U+0800和U+FFFF之間。UTF-8表示為3個位元組。
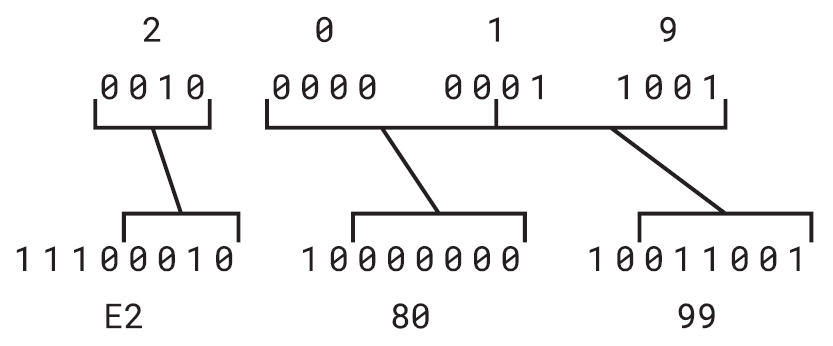
原始Unicode數字的所有位元都是組成3個位元組所必需的內容。前4位元以1110開頭,接下來的6位元以10開頭,最低效的6位元也以10開頭。結果是E2h、80h和99h所組成的3位元組序列。
現在來看這封郵件的問題,它的主旨是:We’ve received your payment, thanks.
第一個單字顯然是“We’ve”(我們已經),但這個縮略語並非使用老式的ASCII撇號(ASCII的27h或Unicode的U+0027),而是更奇特的Unicode右單引號,它在UTF-8中被編碼為三個位元組E2h、80h和99h。
到目前為止,沒問題。但這封電子郵件中的HTML檔案指出,它使用的是字符集windows-1252。它其實應該指出使用的是utf-8,因為這就是文字的編碼方式。但是由於此HTML檔指出使用的是windows-1252,因此我的電子郵件程式會使用Windows-1252字符集來解釋這三個位元組。回頭看看本文開頭的Windows-1252代碼表,自己確認一下E2h、80h和99h這三個位元組確實映射到字符â、€和™,正是電子郵件中的字符。
謎團解開了。
透過將電腦的使用擴展成一種普遍和多元文化的體驗,Unicode已經成為一個非常重要的標準。但像其他任何東西一樣,除非它被正確使用,否則它是不會發揮作用的。(本文摘錄整理自第13章,碁峰資訊提供)

圖片來源_碁峰資訊
書名 Code:隱藏在電腦軟硬體底下的秘密(第二版)
Charles Petzold/著;蔣大偉/譯
碁峰資訊出版
定價:680元

作者簡介
Charles Petzold
從事程式設計和電腦方面的寫作已有35年。他的著作包括十幾本的程式設計教材和《The Annotated Turing A Guided Tour through Alan Turing Historic Paper on Computability and the Turing Machine》。他與妻子Deirdre Sinnott(歷史學家和小說家)以及兩隻名叫Honey和Heidi的貓一同住在紐約市。他的網站是www.charlespetzold.com。圖片來源_Amazon
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
")
2026-02-09
")
2026-02-09

2026-02-09