
使用資料採礦,似乎可以增加收益」、「聽說某公司藉由資料採礦找到了隱藏的定律,並運用在業務上」──。這樣的論調流行了一段時日。
資料採礦不是萬靈丹
最出名的就是「購買紙尿布的顧客,連同啤酒一起購買的可能性很高。某家超市藉由這個在資料採礦中發現的定律,將這兩樣商品擺在一起,大幅提升了業績」。
上面的傳述,造成有一段時期資料採礦被當成是萬靈丹一樣的寶物。在這樣的背景下,系統集成商想賣系統整合、出版社想促銷相關書籍的意圖不言可喻,不過活絡的氣氛至今已逐漸沉寂下來。
期望過高,導致實際引進資料採礦的使用者,失望也很大。
然而資料採礦畢竟不像那些被遺忘在歷史洪流中的無用工具,不再會被使用。
資料採礦與傳統統計分析的不同
學習資料採礦技巧時,一定會碰到一個疑問,那就是分不清楚資料採礦與傳統統計分析之間的差異。
雖然被稱為資料採礦,但並沒有所謂「資料採礦」的分析技巧。資料採礦是一種行為的總稱,其中存在著許多種分析技巧,根據分析的目的不同而被選擇使用。
● 迴歸分析
● 決策樹分析
● 群集分析
● 類神經網路
大致上這些是常聽到的分析技巧。資料採礦就是綜合上述技巧來分析資料。其中的迴歸分析和決策樹分析,並不是什麼新的技巧,在基本的統計分析中也會運用到。很多人可能在高中或大學時已經接觸過。
資料採礦的本質不在於技巧的翻新,而是在於準備資料的質與量上。資料採礦使用極為龐大的資料量來執行分析,使得分析的目的也變得不同。
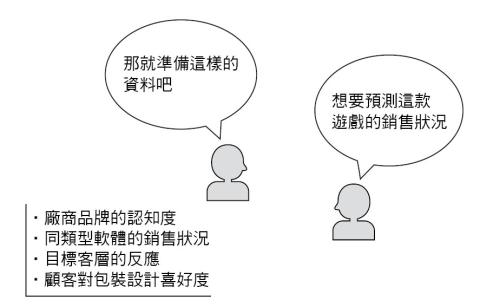
如同圖1-1中的案例,以往的步驟是「那麼,開始準備資料吧!」然後委託市調公司蒐集、購買資料,或是自己做問卷調查。這個步驟並沒有什麼錯,方法論本身也是對的,可以得到頗為穩定的結果。
但是在這個方法中,只要超出「蒐集到的資料」的範圍,就無法進行分析行為了(圖1-2)。
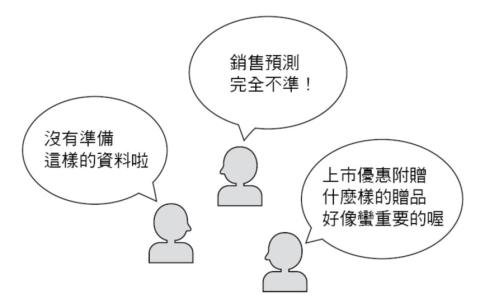
當然,執行分析的人會盡可能大範圍地蒐集資料,有經驗的分析人員會判斷篩選適當的資料,以導出正確的結果。
問題在於蒐集資料時的取捨選擇具有很大的限制,很難發現或驗證出超出理解範圍之外的定律。
這是因為,一開始就不具備能夠導出理解範圍之外定律的資料。
這樣的特性,造成統計分析變成只是專家在用的工具。而且,其使用目的也屬於事後驗證型(後面將會說明)。
儲存資料的成本變低了
大環境的變化,使得情況劇烈改變。資訊器材大量普及而且成本降低了,尤其是運算設備和記憶設備。
傳統上統計分析的一個弱點是,必須先建構分析才有辦法開始蒐集資料。在這個過程中再篩選資料,但畢竟資料蒐集需要時間,於是會有時間上的落差。
不過,資訊化的進展,使得街頭巷尾到處都有資訊設備。原本,資訊設備是用在留下使用紀錄並加以保存的,於是便產生了利用其來補足資訊貧乏性、降低資訊蒐集成本的想法。
在資料採礦之前,這樣的想法之所以無法獲得認同,是因為儲存資料的成本非常高。
不論是主記憶設備、或是輔助記憶設備,單價都被以位元組為單位精確地計算,系統工程師和程式設計師必須竭盡所能壓低價格來架構系統。
公元兩千年的電腦千禧年危機,就是因此而產生的。用現在的成本概念來看,實在很難理解當初為何只取西元後兩碼做為變數的規格。因為這種做法只能夠節省少量的位元組,事後卻帶來龐大的處理成本和工作時數。不過話說回來,即使當時容許採用全部的西元年數來計算,還是有必要抑制資訊量。
在那樣的情況下,任誰也不會想到要保存處理過程中所有的資料。因為連馬上用得到的資料都無法全部儲存,怎麼可能保存那些不知道什麼時候才會用到的資料呢。
但是資訊化的快速發展,使得資訊設備大量普及,資料儲存成本如同幾何級數般地下降。即使初看無用的資料,現在也可以暫時保存於電腦上。
只要可以儲存,就會有無限多的資料想要儲存。儲存下來的銷售紀錄,或許以後可以再拿出來檢視、遇到顧客抱怨時也可以馬上調資料出來。
這樣的理由造成企業等等組織團體,開始儲存「不知道用不用得到的資料」。而且數量越來越龐大,毫無停止的跡象。今後諸如政府機關各種公文的電子化,必須義務保存一定的年限,整體社會儲存的資料量只會繼續增加。幾乎可以說是「資訊爆炸」了。
從龐大的資料中淘金
有些人對資訊爆炸的情形抱持負面的看法並提出警告,但凡事都有正反兩面,有壞的必定有好的。資料儲存量無預警的增加,對於分析人員而言卻是個大好消息。這代表的是,可以自由使用的資料量大幅增加,而且唾手可得。
如同上述,傳統統計分析的一個弱點是必須先蒐集基本的資料。現在想要的分析結果,非得先從蒐集資料開始。資訊密集社會化的進展,所需資料很可能早就被儲存在某處。交換或交易資料的方法如果也能標準化,那麼需要的資料就可以即時得到,並立刻進行分析。這代表的是,消除了資料種類的相關限制。
● 必須蒐集需要的資料
● 對所蒐集資料進行分析,計算量有上限
上面的兩個原因,造成以往必須從有限的資料中取得分析結果。但是現在蒐集資料和使用資料的成本大幅下降,對於現存的資料無論取用多少,也不會增加太多的工作量。而且相較於所提高的分析精準度,增加的成本和工作量甚至可以忽略。
如果演算設備沒有充分的能力去處理,擁有再多的資料量也只是枉然。資料量和演算能力就像是車子的兩輪,缺了一個就無法適當地利用資料。現在已經是可以便宜得到兩者的時代了,現在的環境已經可以奢侈地去使用看似毫無關聯或意義的資料來進行分析(圖1-3)。
這樣一來就有可能發現超越過去經驗法則的規則和定律(圖1-4)。

有能力的企業經營者,也許早就有這樣的經驗了。優秀的企業經營者,往往能夠發現大家都還沒注意到的定律,也就是能夠把不相關的資訊連結起來,利用在促進自己的事業上。
相對於以往必須依靠直覺和經驗等等天賦技巧,資料採礦宣示了大家都可以運用的可能性,這一點具有革新的意義。
預測未來
可使用的資料在質與量上的大幅提升,使得資料採礦偏向預測未來,有別於傳統統計分析偏向於對既有定律的事後驗證。
來看看偏差值的例子。
偏差值是考試分數經過統計分析後的產物。考生的分數是偏差值的基本資料,不具備其他意義。
因此偏差值代表的是某個瞬間,某個分析對象在全體考生中所處的位置。(圖1-5)
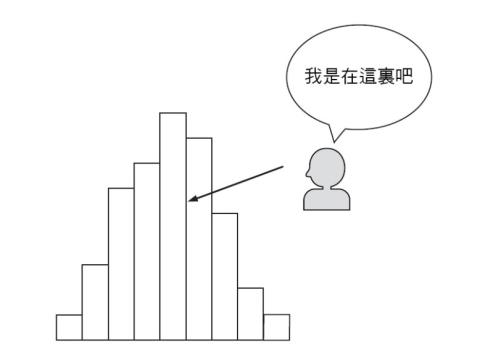
這不用說明也知道是自己考試後的分析。什麼領域比較行或不行、程度相當於所有人的什麼位置、有多少機率會上理想的學校,可以從事後的分析得到結果。
但是對於自己下次考試所得分數,偏差值卻很難進行預測。這是因為偏差值是分析過去某個時間點「自己成績如何」的方法,並不是預測下次考試可以得到幾分的方法。
當然,如果定期取得偏差值,並依照時序排列,的確可以預測下次自己考試的分數。
若進一步想要執行精準度更高的預測,就必須準備以下不同觀點的資料:
● 下個考試的計分方式?
● 出題會是以自己拿手的部分為主嗎?還是自己不拿手的部分?
● 成績現狀是處於上升階段?還是下降階段?
其他諸如:
● 自己是在練習時還是實際考試時比較容易發揮實力?
● 自己有花粉症
● 往年考試的日子花粉飛散分布的狀況如何?
這些看來和答題能力沒有直接關聯的事情,或許都和考試當天的得分會有關係(或沒有關係)。
能夠確定的是,傳統的統計分析方法並沒有預先蒐集這樣的資料;而資料採礦則納入這樣的資料,所以是比較偏向未來預測型的分析體系。
新手也能上手嗎?
說明至此可知,資料採礦不只是分析過去的現象,亦包含預測未來,可說是相當不錯的分析技巧。
相較於統計分析需要專業技能,一般認為資料採礦是使用蠻力來分析龐大的資料,只要輸入全部擁有的資料就可以了,也因此被認為新手也能上手。
但是事情並不會這麼簡單。
其中一個原因,就是資料量太龐大。
無論記憶設備的低價化如何如火如荼進行,儲存大量的資料仍需花費相當的成本。處理資料的演算設備也面臨同樣的問題。
對於企業而言,或許不會成為困擾,對於個人而言卻難以負擔這樣的成本。所以個人如果想進行資料採礦,實際執行上仍有困難。或許類似的分析可以被執行,但卻無法使用無限量的資料,資料的取捨變成是必要的,於是需要專業技巧,結果可能和傳統統計分析的方法沒有什麼差異。
發現的定律未必有用
另外就是發現的定律有無用處的問題。
如同前述,資料採礦的特徵在於使用龐大的資料量。龐大的量代表其中極有可能混雜了雜物在內。
資料採礦的用語「採礦」的意圖很明顯。可分成兩個步驟。
第一個步驟是從大量的資料中,找出隱藏在內的定律。一般都將這個步驟視為資料採礦。
第二個步驟是從發現的定律當中,找出可以使用的。很意外的是,這個步驟常被忽略。大部分的人都認為,只要找出定律就是有意義的,就可以從中煉金。其實,沒有用的定律佔了絕大多數。而這個事實卻很容易被忽略。
例如,投入了全部的資料、執行分析的結果,資料採礦系統可能找出如下的定律:
● 星期一結束後,星期二會到來
● 1之後是2
● 下雨的話,人們會撐傘
這些都是顯而易見的,全是日常生活經驗當中已經知道的事情。事到如今沒有必要再使用資料採礦系統去發現(圖1-6)。
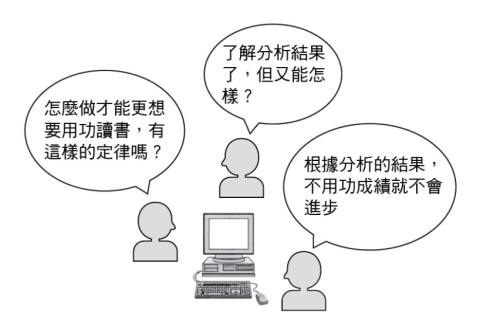
但是只要使用資料採礦系統,就無法避免類似的「發現」。採礦行為在這個階段必須有耐性。如同從廣大的礦床中淘出砂金一般,必須從龐大的垃圾定律中,找出有用的定律。
也就是這個原因,資料採礦並不是萬靈丹。
理解基本原理和構造的必要性
為了得到有意義的定律,必須從大量被導出的定律當中,踏踏實實地找出有用的定律。然而判斷有用無用,終究得靠當事者的判斷。資料採礦畢竟尚未發展成熟到沒有經驗的人也能簡單操作的程度。
但是資料採礦之所以倍受期待,是因為高度的實際性和實用性。
在古典的統計分析中,為了理論上能夠得到漂亮的結果,必須加上形形色色的各種限制,造成有些地方很難適用到現實社會。關於這點,資料採礦中主要被使用到的技巧,並不會拘泥於理論的最適性上,因此更容易活用到商業活動等等行為上。
資料採礦的工具和系統會實際執行計算的部分,群集分析、自我組織映射圖等方法,則可以將計算結果視覺化。
雖說有時難免會用錯技巧領域、或用了完全不對的資料導致得不到期待的結果,但卻可以在更柔軟、視覺化的環境下重複嘗試錯誤,從這層意義來看,資料採礦的使用門檻已降低不少。
因此在日常生活中想要活用資料採礦的話,並不需要熟記難懂的數學公式,只需理解其基本原理和構造,能夠正確運用工具和系統即可。
如果不能徹底領悟這一點,則有可能如mining(data mining)所擁有的另外一個意義般,從自己的手中埋下地雷。
定義因人而異
更進一步需要說明的是,資料採礦雖然可以發現各個情況下存在的各種定律,卻不會說明其中的原因(圖1-7)。
這也是常會被誤解的地方,令人意外的是大多數人都認為,只要執行資料採礦,就能夠得到包括事情發生原因在內的所有解答。
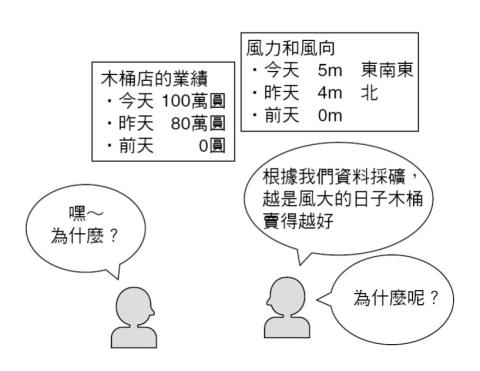
例如執行如下的資料採礦:
● 風力和風向的資料
● 木桶店的業績資料
而發現了「風越大木桶店就越賺錢」的定律。這個定律本身十分有用吧。查看氣象報告,如果預測明天可能會有強風,那麼去買木桶店的股票就可能會有賺頭,如果是自己開木桶店則可以增加銷貨量。
但是,資料採礦並不會告訴我們,為什麼風大造成木桶店賺錢的原因。因此就算經驗法則可以導引出這樣的結果,法則本身仍不會被完全理解。
假設風大與木桶店賺錢並沒有直接關聯,而是如同圖1-8的關係。
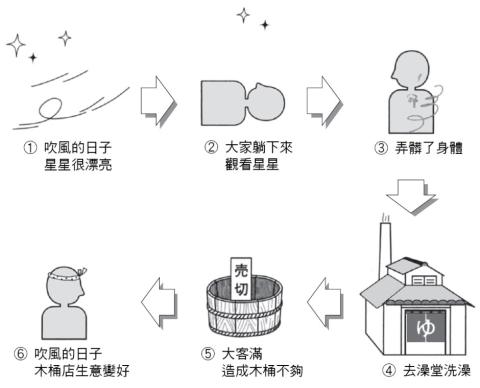
如果這樣的原因是正確的,那麼核污染造成無法看到星星的狀況下,無論風再怎麼吹木桶店還是賺不到錢。
● A發生後,B就發生(1)
實際觀察而得到的見識是有用的。除此之外,
● A發生後因為C這個原因而使得B發生(2)
也非常重要必須了解。因為如果搞不清楚原因,就無法斷言A會引發B。盲目相信經驗法則,終究會自食惡果。
饅頭和桔子和茶同時出現時,由於饅頭配茶、桔子配茶都相當搭配,因此一開始會感覺饅頭和桔子也很搭配。這稱為「疑似相關」。
有如「風越大,木桶就賣得好」這個明顯的例子般,如果只是抓住表面上的傾向,而不管其背後的原因,則很容易被疑似相關所騙,容易認定什麼東西都有關聯。結果是誤認「一起吃應該不錯」,於是就把饅頭和桔子一起放入口中,而嘗到了苦頭。
言歸正傳。資料採礦是可以發揮重大效果去探知(1)的工具,但是還無法得到(2)。截至目前為止,(2)還是只能夠依靠人的判斷。
資料採礦可以得到非常有益的結果,但卻不是萬能的工具,對它必須理解才能加以善用,要找出所獲得的定律背後的原因還是得靠人的力量,必須深切了解這一點才能好好利用資料採礦。
附帶一提的是,前面提到有名的紙尿布和啤酒的案例,被分析指出是因為媽媽家事太忙無法分身,吩咐爸爸去買紙尿布,於是爸爸順便買了啤酒犒賞自己。但是根據富比士雜誌的調查,雖然確實發現了傍晚時紙尿布和啤酒有一起被購買的傾向,但是好像沒有零售商根據這個事實來更改商品的配置。實在有點可惜。(摘錄整理自第一章)
從資料中挖金礦:找到你的獲利處方籤
岡山鳥裕史/著;李弘元/譯
經濟新潮社出版
售價:280元
《作者簡介》
岡山鳥裕史
1972年生於日本東京。中央大學總合政策研究所博士。曾任職於富士總合研究所,現擔任關東學院大學經濟學部經營學科情報部門、經濟學研究所副教授、中央大學Web Service Initiative技術部會副部會長。著作有《一星期弄懂——資安管理員的集中專題研究》(日本經濟新聞社)、《個人識別碼為什麼是四位數字?》(光文社新書)等。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10