
Alphabet子公司DeepMind周三(10/18)宣布,已打造一個比AlphaGo更厲害的圍棋程式—AlphaGo Zero,它具備自我教學能力,已成為歷史上最強大的圍棋棋手。
之前的AlphaGo版本主要是以數千盤人類棋手的對戰進行訓練,包含業餘與專業棋手,然而AlphaGo Zero跳過了此一步驟,在完全不懂圍棋的狀況下自己跟自己對戰,由於它內建了具備強大搜尋演算能力的神經網路,因此能不斷調整與更新,以預測棋子的落點。
AlphaGo Zero透過強化學習模式讓它成為自己的老師,當中完全沒有人類的干預,也未使用歷史棋戰資料,只花了40天便成為史上最強的棋手。
一開始的AlphaGo Zero只知道圍棋的基本規則,卻在3天後就打敗了AlphaGo Lee,這是在2015年與李世乭的5盤對戰中拿下4盤的AlphaGo版本;21天後它達到與AlphaGo Master同樣的能力,此為今年於網路上與60名專業棋手對戰拿下全勝紀錄,並擊敗柯潔的AlphaGo版本,40天後它便超越了所有的AlphaGo版本。
DeepMind指出,AlphaGo Zero所使用的技術遠比之前的AlphaGo還要強大,因為它不再受限於人類的知識,而是向全球最厲害的棋手學習—AlphaGo Zero自己。
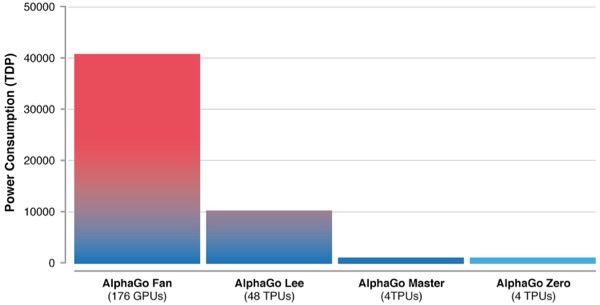
隨著演算法的進化,AlphaGo所使用的運算資源也愈少(下圖),早期的AlphaGo Fan使用176個GPU,之後便改採Google自行發展的AI處理器(Tensor Processing Unit,TPU),AlphaGo Lee使用了48個TPU,AlphaGo Master與AlphaGo Zero皆只使用4個TPU。
儘管AlphaGo Zero仍然以圍棋為開發範本,但DeepMind認為類似的技術將可被應用在其他的結構化問題上,例如蛋白質折疊、降低能源損耗,或是尋找革命性的新材料等,將有潛力對社會帶來正面的影響。
AlphaGo Zero的研究報告已於本周發表於《自然》(Nature)期刊上。
AlphaGo Zero介紹影片:
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09
")
")
2026-02-09

2026-02-09