Datadog
資料監控廠商Datadog的更新步調很積極,今年積極推出雲端容器監控服務,大力支援AWS、Azure的Kubernetes服務,還有Prometheus等容器應用。而在近日該廠商又宣布,Datadog監控平臺要推出新功能Watchdog,使用者不需要設定警報觸發條件,系統就會自動監測平臺是否出現效能異常的事件。
原先Datadog平臺就已經有異常事件偵測、離群值偵測、系統預報,以及整合式警報等功能,不過Datadog認為,萬一用戶的系統延遲性突然飆高,或者錯誤率開始大增,而系統管理員也未預先設定這些警報條件時,「此時Watchdog就可以派上用場了」,這次推出的新功能,號稱開發者不需要手動設定,使用Datadog在正式環境反覆測試過的機器學習演算法,Watchdog可以自動偵測系統服務的延遲性是否驟升、系統錯誤率上升,甚至公有雲廠商的網路是否出現異常。
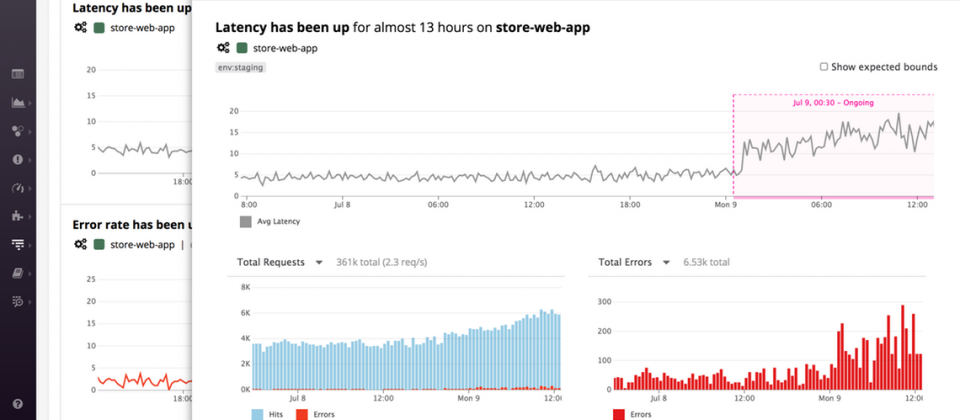
在實際功能面上,Watchdog會全面偵測IT環境出現的異常事件,並且將這些事件記錄成不同的Story。而在每一個Story文件中,Watchdog列出該事件事發的時間軸,以及折線圖、長條圖等視覺化圖表,再搭配簡短總結,描述該事件所發生的區域、造成影響,以及總共維持多久時間等資訊。
而使用者想要更進一步瞭解問題,Story文件也可以提供更多細節資料,列出發生異常的服務、位在哪個可用區域等訊息。同時,系統也會使用過去蒐集的歷史資料進行統計運算,預測正常情況下平臺應有的表現,並且畫出趨勢圖表,讓使用者以這些預測資料為基準點,判別異常事件的嚴重程度。
而IT環境發生異常的原因,有時盤根錯節,必須個別討論,有時也可能肇因於單一因素,進而讓影響擴散至其他區域。而Datadog表示,Watchdog比對各個異常事件後,可以將類似行為表現的事件整理出來,「這些問題可能都是源於同一原因」,系統管理員就可以觀察,是否整體環境,或者只有特定應用程式遭受影響。
除了監控內部環境可能的影響因子,Watchdog也可以監控外部環境因素,像是外部公有雲環境網路部分區域發生異常時,使用者可以儘早將工作負載搬遷至網路環境正常運作的區域,或者利用其他雲服務商做備援。

Watchdog會將異常事件記錄成不同的Story。在每一個Story文件中,也會列出該事件事發的時間軸,以及折線圖、長條圖等視覺化圖表,再搭配簡短總結,描述該事件所發生的區域、造成影響,以及總共維持多久時間等資訊。圖片來源:Datadog

而使用者想要更進一步瞭解問題,Story文件也可以提供更多細節資料,列出出現異常的服務、位在哪個可用區域等訊息。圖片來源:Datadog

系統會使用過去蒐集的歷史資料進行統計運算,預測正常情況下平臺應有的表現,並且畫出趨勢圖表,讓使用者以這些預測資料為基準點,判別異常事件的嚴重程度。圖片來源:Datadog

Watchdog比對各個異常事件後,可以將類似行為表現的事件整理出來。系統管理員就可以觀察,是否整體環境,或者只有特定應用程式遭受影響。圖片來源:Datadog
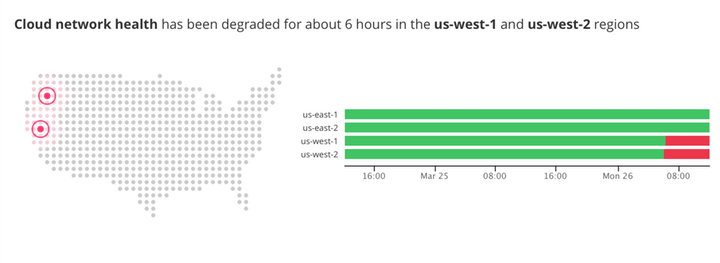
除了監控內部環境可能的影響因子,Watchdog也可以監控外部環境因素。Watchdog會列出公有雲網路的健康狀況,讓使用者判定,是否要將工作負載搬遷至網路環境正常運作的區域,或者利用其他雲服務商做備援,避免降低服務品質。圖片來源:Datadog
熱門新聞

2026-02-09

2026-02-10

2026-02-06

2026-02-09

2026-02-10

2026-02-10

2026-02-09
