臉書
為了提升圖片搜尋及加強過濾有害及其他不當資訊,臉書(Facebook)發展了圖片中文字的辨識技術,並宣稱現在每天已經可以過濾10億則圖片。
臉書與Instagram平台上的大量相片中有各種不同文字型式,有的是層疊在表情符號上、或有的是鑲嵌在店家大門、招牌或餐廳菜單上。臉書和Instagram上的相片數量、文字型式及支援的語言種類之多,傳統光學字元辨識(OCR)只能辨識字元但不理解圖片的上下文。
為解決這個問題,臉書開發出了大規模機器學習系統Rosetta,它如今每天從超過10億幀臉書和IG的公開圖片和影片訊框中即時萃取出文字,輸入已經訓練可以同時理解文字和圖片的文字辨識模型中。
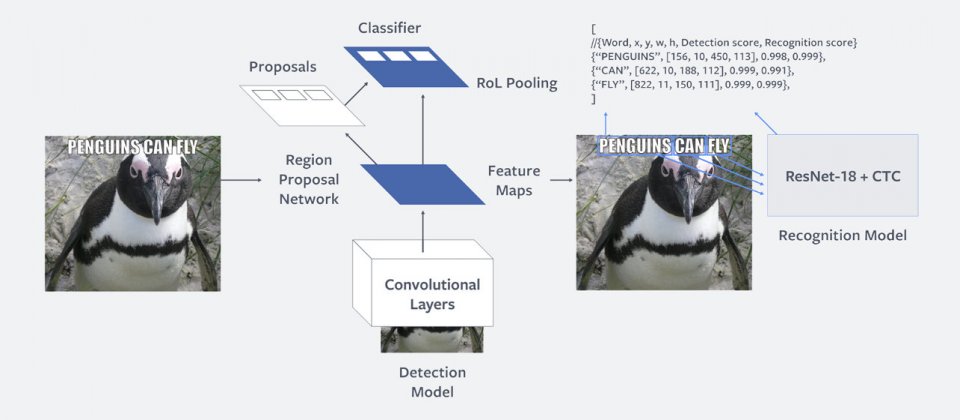
Rosetta萃取圖片中文字的過程包含二個步驟。先以Faster R-CNN偵測可能包含文字的矩形區塊,再以經過連結時間序列分類損失(Connectionist Temporal Classification loss, CTC loss)訓練過的完整卷積神經網路(Convolutional Neural Networks, CNN)來辨識及轉錄出該區塊中的文字。他們是將文字辨識視為一種解決序列預測問題的過程,輸入端是包含文字的圖片,結果就是圖像中字元排成序列,之後利用CTC loss來訓練這個序列模型,結果就能辨識出任意長度的文字,以及訓練中沒有見過的文字。
現在這個模型不只能辨識英文,目前也支援阿拉伯及印度語,克服了文字由右到左或是堆疊字元的挑戰。
現在臉書已經能有效每天辨識臉書和IG上超過10億公開的圖片,這些萃取出來的文字都被平台上的分類器用來即時糾出違反政策的仇恨、暴力內容、用於臉書的圖片搜尋功能中,或改善動態消息中的個人化內容。
臉書表示,下一步要處理的挑戰包含圖片經過旋轉、變型、模糊化、或其他扭曲方式使文字不易辨讀、照片中文字和街景混雜、平台上愈來愈多的影片內容,以及現有英文及拉丁語系文字外的更多文字支援,Rosetta現有技術對這些內容仍力有未逮。
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10