
今年六月Databricks推出的開源機器學習平臺MLflow,現在釋出0.7.0版本,這個版本主打由RStudio提供的新MLflow R客戶端API,讓R語言的資料科學家也能使用MLflow,開發機器學習應用,而R語言是暨Python和Java之後,MLflow支援的第三種語言。另外,新版本還增加了實驗註釋小功能以及兩個範例供使用者參考。
由Apache Spark技術團隊所創立的Databricks,在六月時釋出開源機器學習平臺MLflow預覽版,MLflow不只是開放原始碼,同時還使用開放介面,以支援現有的機器學習函式庫、演算法和工具,幫助管理機器學習開發和生產生命週期相關的工作流程。在4個月後,Databricks在歐洲Spark + AI大會上,宣布了MLflow 0.7.0版的最新消息。
在MLflow 0.7.0中,RStudio貢獻了R客戶端追蹤API,這功能類似Python和Java客戶端追蹤API,還與RStudio程式開發環境完全整合,提供CRUD介面以存取MLflow實驗和執行狀態。R客戶端追蹤API可在本機端追蹤實驗,或是也連接到MLflow伺服器和其他人分享實驗結果,並且輸出可以在本機或遠端共享的模型。
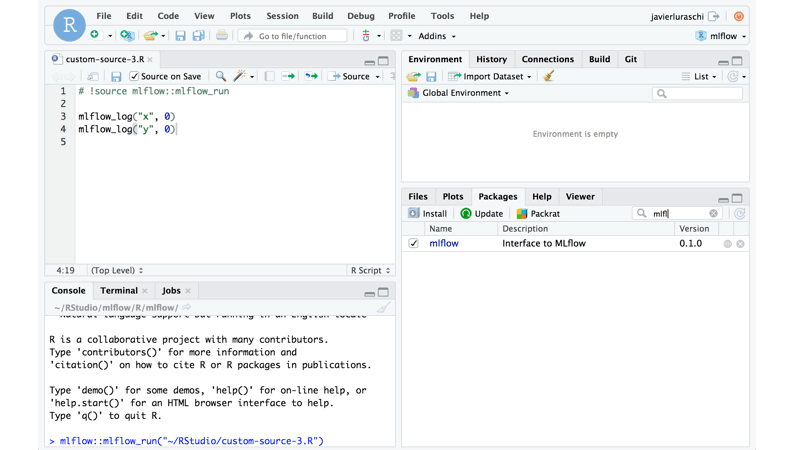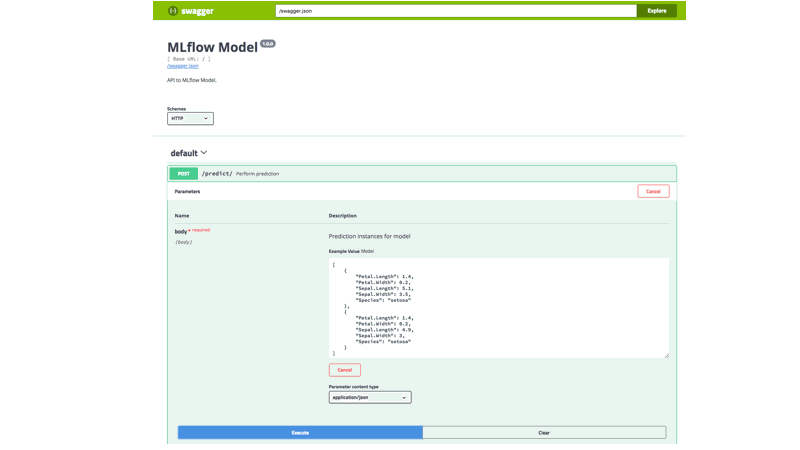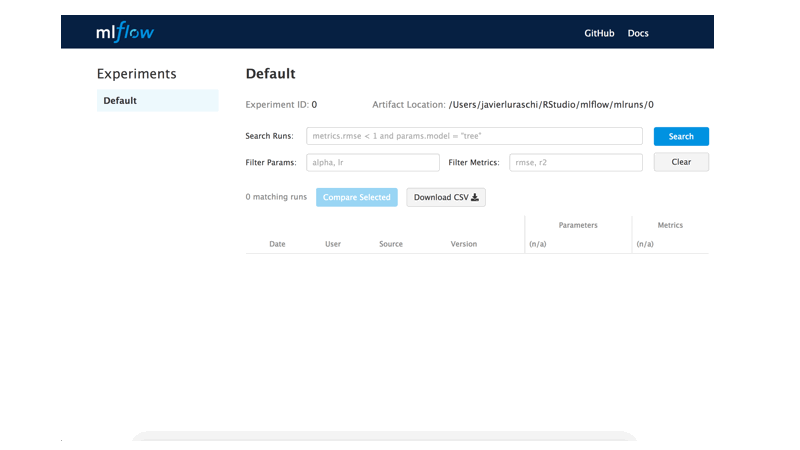
官方提到,R語言客戶端追蹤API跟Python和Java版本,在使用上沒有太大差異。MLflow R客戶端允許開發者在程式執行階段,紀錄參數、程式碼版本、指標和輸出檔案,然後以MLflow UI視覺化這些結果。
除了R語言的整合外,MLflow 0.7.0加入了由社群成員貢獻,雖然很小但卻很有用的功能,現在使用者可以在每次的執行中,在MLflow UI加入註釋,紀錄實驗的重點。
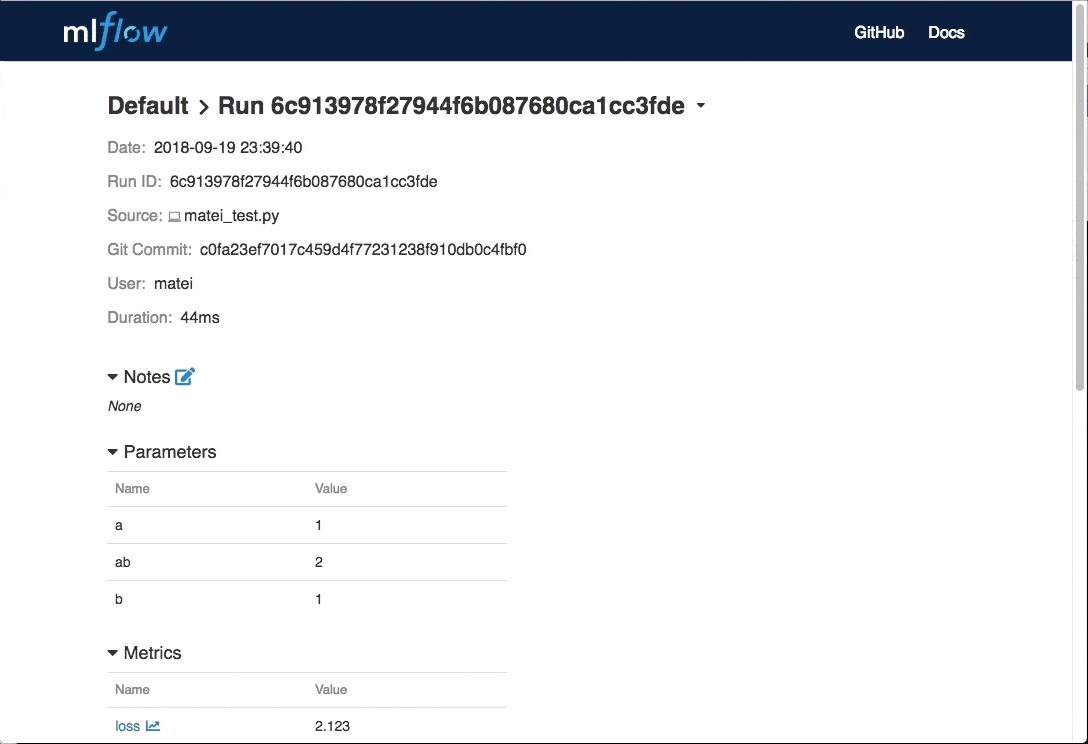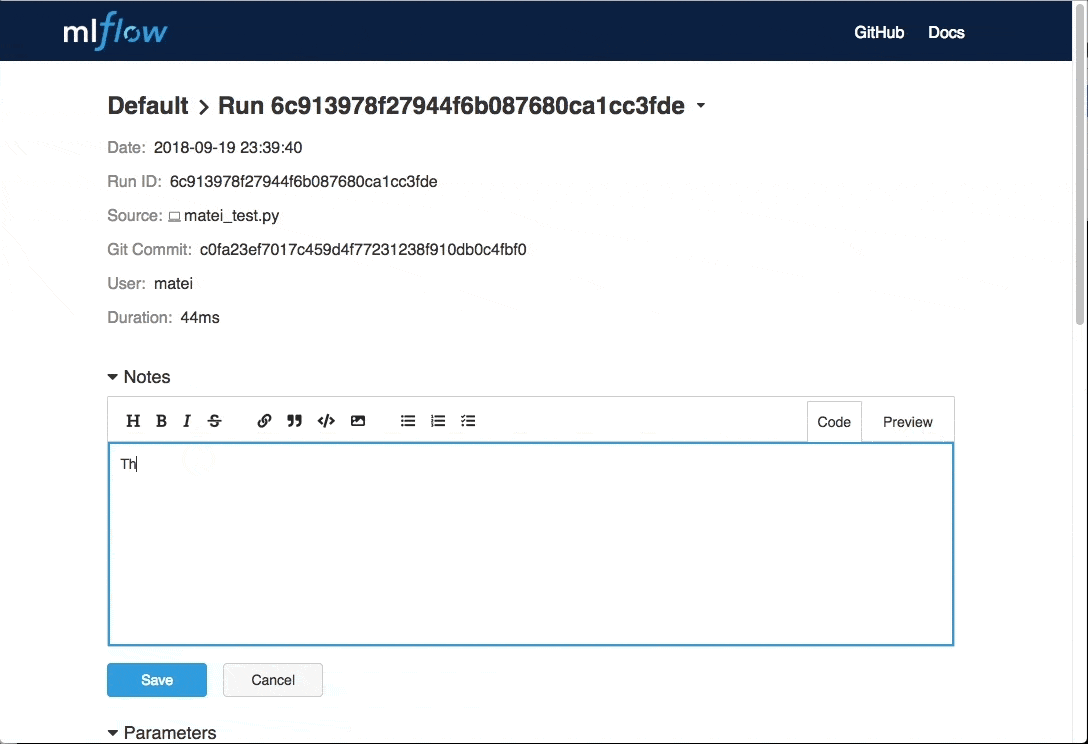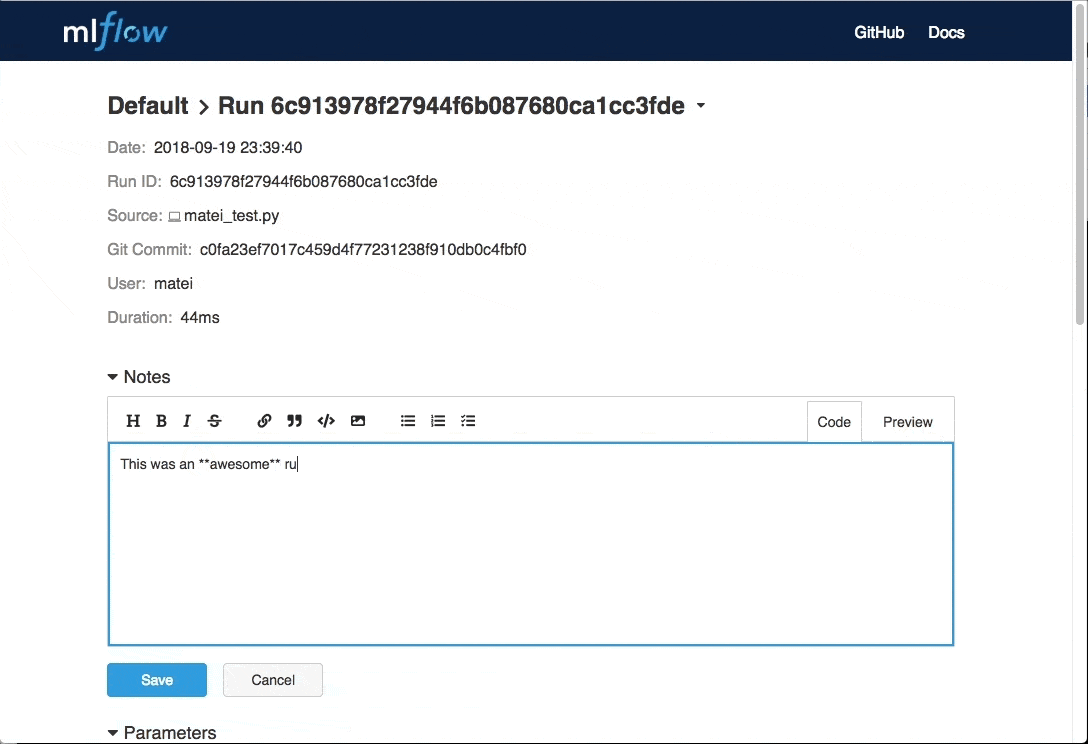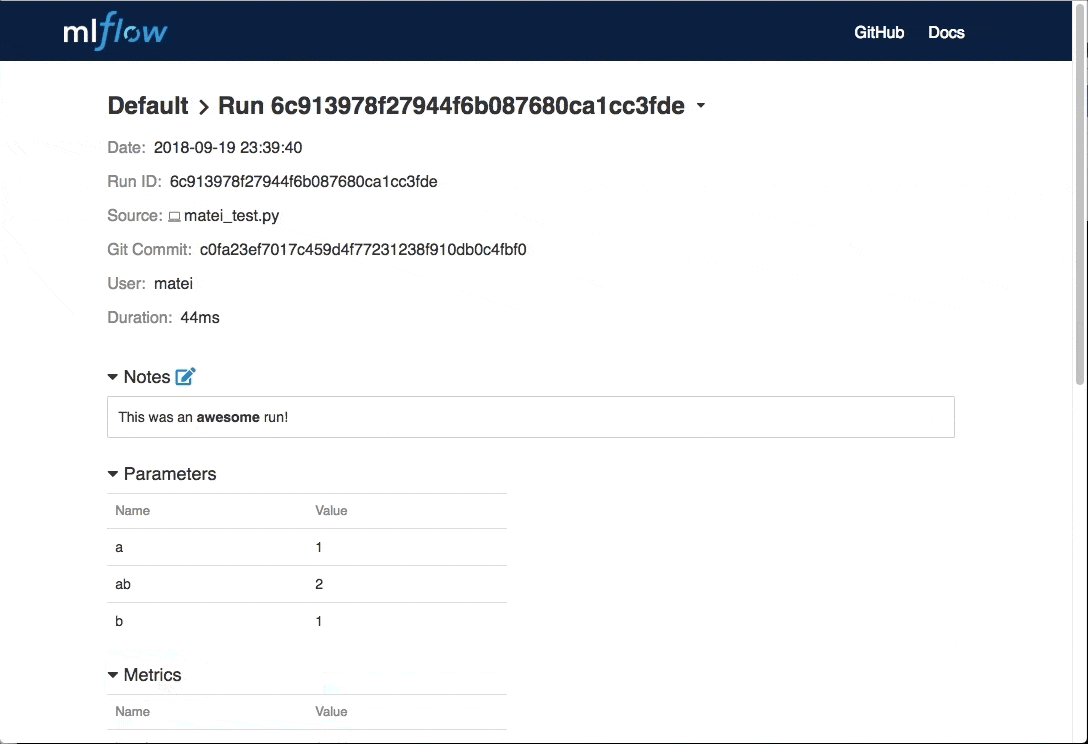
此外,Databricks也加入了兩個範例供使用者參考,分別是多重步驟工作流程和工作管線(Multistep Workflows and Pipelines)和超參數調校(Hyperparameter Tuning)。官方提到,在產生機器學習模型的生命週期中,模型訓練和部署之前通常都還要經過多個步驟,無論是從來源收集資料,或是執行ETL將資料轉換成高效能格式,接著才能在後續使用乾淨的資料,對模型進行訓練、追蹤和實驗。多重步驟工作流程和工作管線則示範了在MLflow框架中,這些程序串接的方法。
而超參數調校則會向使用者展示,使用MLflow最佳化深度學習函式庫Keras,並與熱門函式庫諸如HyperOpt或GPyOpt進行高效能的協作。這個範例中使用了紅酒品質資料集,示範最佳化Keras深度學習模型的RMSE指標。
MLflow 0.7.0現在可以在Pypi上取得,而R語言客戶端則可以從CRAN下載。
熱門新聞

2026-02-09

2026-02-06

2026-02-10

2026-02-09

2026-02-09

2026-02-10

2026-02-10
