
HOOBOX
重點新聞(1130~1206)
英特爾 表情辨識 身障移動
只靠臉部表情,身障人士也能操控電動輪椅
美國機器應用新創HOOBOX藉助英特爾AI技術,推出Wheelie 7套件,讓嚴重身障的人士只靠臉部表情,就能操控電動輪椅。Wheelie 7套件包括3D攝影機、車載電腦、導航感測器、Wheelie軟體和其他電子配備等,該公司稱只要7分鐘就能完成安裝。而不同於其他行動輔助設備,Wheelie 7套件不使用人體感測器來偵測動作指令,靠的是英特爾RealSense深度攝影機,能即時串流演算法處理的資料,而Wheelie 7也採用英特爾處理器和其他工具組,來加快臉部表情識別軟體的推論速度。Wheelie 7目前已於美國測試,使用者可設定10個表情(比如微笑、吐舌等)來控制輪椅前進、停止或後退等。(詳全文)
AI AWS 演算法市集
演算法市集來了!AWS Marketplace新闢機器學習與AI專區
AWS日前於re:Invent 2018年大會上,宣布在AWS Marketplace上興建了機器學習(ML)和AI專區,讓用戶更容易尋找及購買能與AWS服務整合的相關軟體。目前該專區主要分為四大類別,分別是資料解決方案(Data Solutions)、機器學習解決方案(Machine Learning Solutions)、智慧解決方案(Intelligent Solutions),以及針對Amazon SageMaker所提供的機器學習模型及演算法(Algorithms & Model)。此外,所有在AWS Marketplace所購買的ML或AI解決方案的帳單都會被併入AWS帳號,而不需另外與供應商交易。(詳全文)
.JPG)
華為 StorySign 手語
華為發布StorySign App,能將故事書內容「比」給聽障小朋友看
華為日前推出一款名為StorySign的免費App,由Huawei AI驅動,只要選定App圖書庫中的任一故事書,再將手機或平板電腦鏡頭對準實體故事書,就能透過特別設計的卡通人物Star,將故事書文字轉化為手語,來「比」給聽力障礙的小朋友看。過程中,螢幕還會以顏色標註與手語對應的文字,父母也可決定顯示速度,來幫助孩子學習詞彙。StorySign由歐盟聽障協會和英國聽障協會等慈善機構支援,動作人物由Aardman Animations設計,童書則由老牌的企鵝藍燈書屋(Penguin Random House)贊助。StorySign目前支援10種語言的手語,包括英語、法語、西班牙語和德語等,中文則尚未支援。(詳全文)
Nvidia 神經網路 虛擬世界
Nvidia用神經網路學習真實世界影片,要讓建置虛擬世界更快更便宜
Nvidia研究團隊近日於2018年全球AI大會NeurIPS中,展示用AI建置3D虛擬環境的生成神經網路的研究成果。首先,該神經網路會從真實世界的影片學習場景,包含場景中的物體、物體的邊緣等細節,由於輸出的虛擬世界是用合成方式產生,開發人員可簡單編輯場景,比如移除、修改,或是增加場景中的物體。在訓練經網路的部分,Nvidia利用Cityscapes和Apolloscapes資料集,在DGX-1用Tesla V100 GPU來訓練模型,在大會上的展示則是透過Tensor Core GPU來執行。Nvidia認為,這項研究成果將能夠降低建置虛擬環境的時間和成本。(詳全文)
Walmart BrainOS 智慧機器
Walmart將部署數百個機器清潔工
美新創Brain Corp近日宣布與Walmart合作,將提供AI服務給全球最大的零售商。目前,全美Walmart超市已採用100多臺由BrainOS平臺驅動的自動地板洗滌機,這款洗滌機能在超市員工訓練的期間,快速繪製路線圖,並透過一個按鈕就能開始自動清潔。該機器配備的感測器可掃描周遭人物和障礙物,進而避障。此外,其後端的BrainOS平臺讓機器擁有自主導航和蒐集資料的功能,並於雲端系統運行。Walmart預計,將於明年1月底財政年度結束時,所有超市部署的BrainOS洗滌機將達到360臺。(詳全文)
AI fastMRI 開源
臉書與紐約大學醫學院開源fastMRI專案AI模型和大規模MRI資料集
臉書人工智慧研究(FAIR)和紐約大學醫學院高級成像創新與研究中心(CAI²R)共同開源了用於fastMRI的工具以及資料。為解決核磁共振(MRI)掃描耗時的問題,臉書和紐約大學醫學院在8月時宣布合作研究計畫fastMRI,要以AI讓MRI的掃描速度加快10倍。而近日該專案開源,釋出新AI模型和任務基線,其中還包括全球第一大的MRI資料集,以作為未來研究的基準。此外,紐約大學醫學院計畫接下來還要發布腦和肝臟的掃描圖像和測量結果,而臉書也會使用既有的實驗基礎、資料和基線,近一步探索基於AI的重建技術。(詳全文)
Google 非監督學習 場景深度
非監督式學習如何對移動物體進行深度預測?Google找到新方法解決
Google研究團隊最近提出一項創新作法,來產生移動物體的深度評估結果,能重現移動物體正確的深度。該方法將結構導入學習框架,不直接透過神經網路來學習場景的深度,而是將場景視為包含機器人本身和移動物體的3D影像,並將個別的運動分為獨立的轉換(transformation),包含場景中用來建立3D幾何學和評估物體運動的轉換角度(rotation)和相對位移(translation)。Google用城市駕駛的資料集KITTI和 Cityscapes測試該方法,發現新方法勝過現行做法,而且新方法能正確地重現與自我運動車輛移動速度相同的車輛的深度。此外,Google也將這次的研究透過TensorFlow在GitHub中開源釋出。(詳全文)

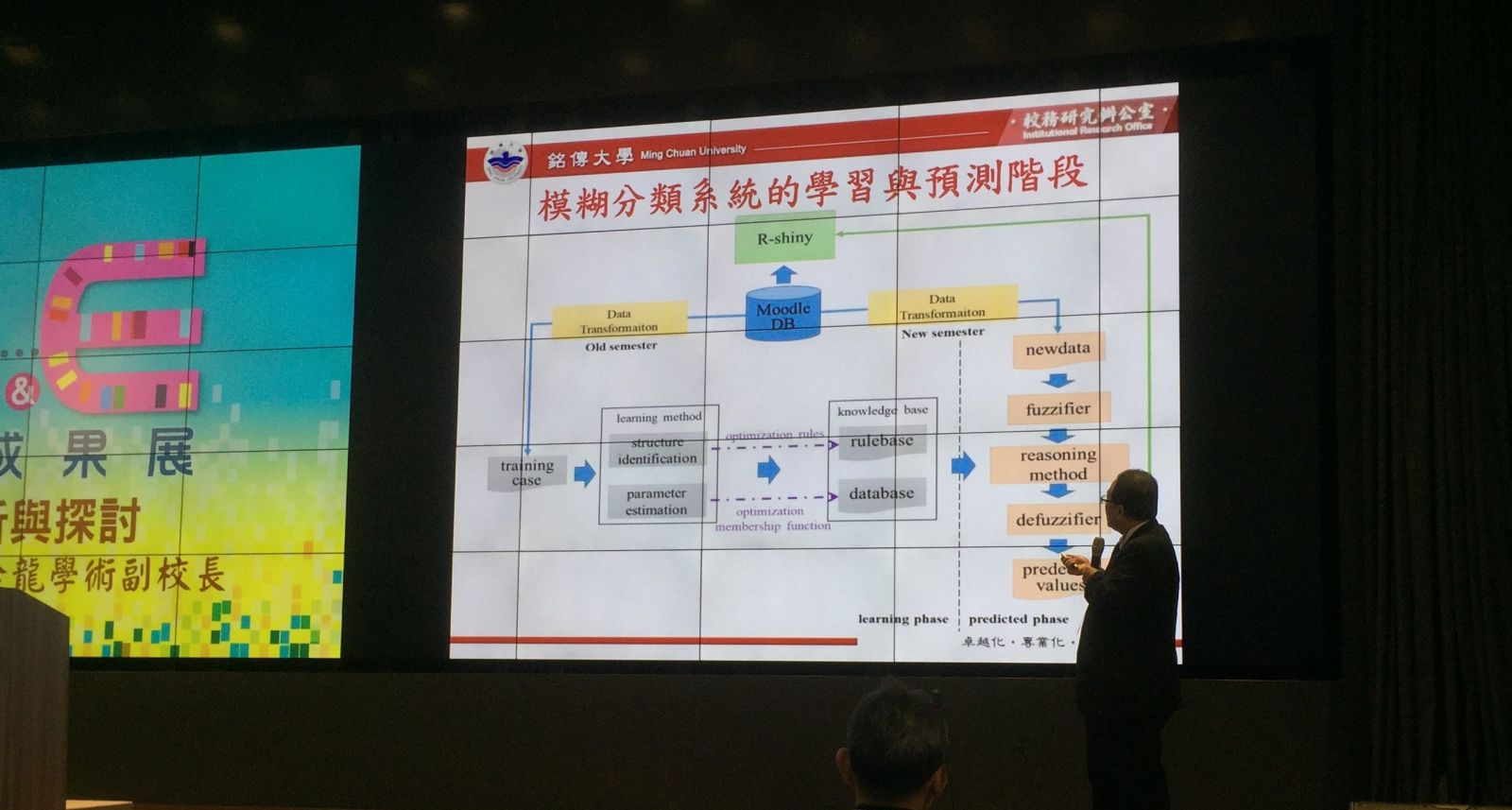
銘傳大學 模糊分類 早期預警
銘傳大學用模糊分類系統來提早學生預警
銘傳大學學術副校長王金龍日前分享校務分析心得,指出透過模糊分類系統(FRBCS),能更有效預測學生成績,比傳統的資料探勘分類法和分群法還要準確。他解釋,在訓練模型時,先將數位學習平臺Moodle資料庫中,轉換過往的學期資料,形成Training Case,再以Learning Method來產生知識庫。這時,模型學習階段告一段落,便可輸入新學期資料,經模糊化、推論等步驟,來顯示預測結果。銘傳大學以10門課程,來比對模糊分類系統和C5.0決策樹演算法,發現模糊分類法準確率平均達70%以上,比傳統方法高出36.64%。(詳全文)
英特爾 加密工具 資安
英特爾開源加密工具,訓練深度學習模型也不怕敏感資料外洩
英特爾近日公布開源釋出深度學習編譯器nGraph後端的資料加密工具HE-Transformer,保護訓練模型的敏感資料。HE-Transformer工具採用微軟研究院開源的加密運算函式庫Simple Encrypted Arithmetic Library,來實現底層的加密功能,讓資料科學家能夠用熱門的開源框架,像是TensorFlow、MXNet、PyTorch等,開發神經網路模型,且資料經過加密的處理。(詳全文)
圖片來源/華為、HOOBOX、Nvidia、Brain Corp.、王若樸、Google
AI趨勢近期新聞
1. AWS SageMaker平臺新增多項新功能,包含語義分割演算法、自動優化ML模型編譯器Neo
2. Google找來RPA軟體商Pega聯手,開始提供RPA機器人流程自動化服務
3. 準確預測照片物體深度,Google用機器學習改善人像模式景深效果
資料來源:iThome整理,2018年12月
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10