Amazon在電腦視覺和圖形辨識重要年度會議CVPR中,發表了三篇改善用戶線上購買衣物體驗的論文,除了改善文字搜尋商品的能力之外,也要讓系統能夠主動推薦能補充用戶已選擇商品的建議,並且還要讓系統能夠合成衣服到模特兒身上。
Amazon的第一篇論文描述了一種,能夠讓使用者透過文字描述,修正產品查詢的方法,像是用戶能以「我想要淺色的花朵圖案」,來改善產品查詢結果。研究人員訓練了一個擁有三個輸入的神經網路模型,三個輸入分別為來源圖像、文字修正描述以及與文字描述相符的目標圖像,這個主模型由位在工作管線中不同位置的三個子模型組成。
研究人員設計了一種可將文字描述表示,和圖像特徵表示融合在一起的方法,在工作管線中,來源圖像和文字描述表示,會先融合在一起,接著才與目標圖像相互關聯。
.png)
由於較低階的模型傾向表示像是材質與顏色等較低階的特徵,而較高階的模型表達袖子長短和鬆緊等較高階的特徵,因此這個新系統使用的分層配對(Hierarchical Matching)技術,有助於訓練模型,確保能在不同層次適當處理文字修正。
每種語言描述和視覺表現的融合,都由兩個獨立的元件模型執行,其中一個關注來源圖像和目標圖像需要維持相同的視覺特徵,另一個則關注要改變的特徵。經過測試,這個系統有助於提高搜尋到與文字修正相符結果的機率,較之前最佳系統提高58%。
而Amazon的第二篇論文,則是建議用戶購買能夠補充選購衣物的商品,研究人員提到,這項新系統能夠預測服裝和飾品的相容性,並在用戶選擇襯衫和夾克之後,推薦可搭配的鞋子。圖像會經過模型產生一個表示向量,向量會以遮罩處理,這個經訓練的遮罩,能夠對向量特徵進行調整,縮小部分特徵的影響以及放大部分特徵的影響。
當目錄中的每個物品都以向量表示,則要找出特定服裝的最佳搭配,就變成了向量配對的問題,研究人員提到,這個系統能以56.19%精確度推薦商品,較之前的系統表現都還好。
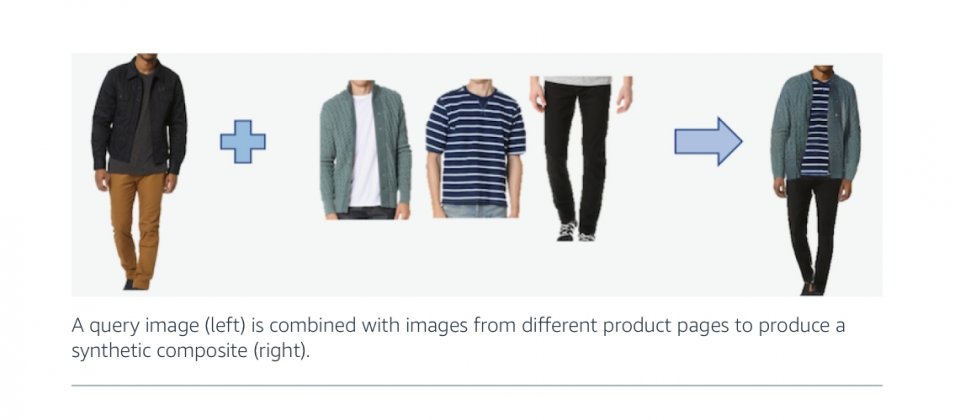
第三篇論文則是描述一個能將衣服合成到目標模特兒身上的系統Outfit-VITON,相當於虛擬試穿系統,將參考照片中人物的穿著,合成到另一張照片的模特兒身上,研究人員提到,Outfit-VITON使用對抗網路,由生成網路和判別網路的競爭產生最佳結果。
.png)
Outfit-VITON由三部分組成,形狀生成模型、外觀生成模型以及外觀修正模型,形狀生成模型會圈出要試穿的衣服形狀,並計算要試穿模特兒的身材以及動作,其輸出的形狀表示到外觀生成模型,外觀生成模型的工作和形狀生成模型相似,其會結合形狀生成模型所生成的結果,合成出模特兒穿著指定服飾的照片,接著由第三個模型進行微調,保留商標以及特殊圖案,研究人員表示,這個系統比以前的系統產生更自然的結果,能夠產生正確的分割圖,透過改變所選服裝的形狀,以符合目標人物。
熱門新聞

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13

