微軟宣布更新語音資料收集政策,藉由徵求用戶同意,讓微軟收集用戶,跟有使用語音辨識技術服務的錄音,供開發人員在研發產品時進行人工審閱,用戶可以查看所有被收集的語音片段,以及語音片段對人工智慧系統所做的貢獻。
在新的語音片段設定中,用戶需要明確同意微軟收集語音資料,微軟才會將用戶的語音資料,用在開發人工智慧產品中,讓微軟員工以及相關人員,聽到這些收集來的語音片段,並且人工轉錄成文字。微軟期望藉由收集更多語音資料集,來提升人工智慧系統的效能。
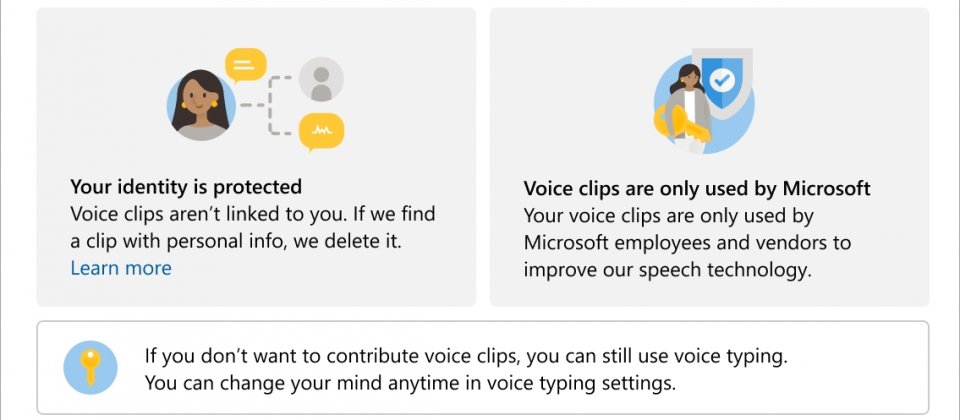
微軟員工以及承包商,僅會在用戶許可的情況,聆聽用戶貢獻的語音,而對其他用戶來說,微軟仍會繼續存取用戶語音活動的相關資料,諸如用戶與語音辨識系統互動時,所自動產生的轉錄文字。透過新的語音片段配置,能讓人們積極同意微軟員工與承包商,可以聆聽他們與服務互動的語音,並且提高用戶的意識,明確知道正在與微軟共享語音,以及了解語音片段被使用的方式。
微軟之所以要取的用戶積極同意,便是要讓語音片段的使用能夠透明化,並讓用戶了解這些語音片段,被如何用來改善語音辨識技術,微軟提到,語音片段處理過程,會消除用戶識別資料,包括識別碼、電話號碼、社會安全碼以及電子郵件信箱,因此相關訊息,不會再出現於微軟用戶的帳戶隱私資訊中心裡。另外,微軟強調,他們不會人工收聽從企業產品收集來的音訊資料。
微軟從2020年10月30日之後,就停止儲存語音辨識技術處理的語音片段,並在接下來幾個月內,會在微軟的翻譯器、SwiftKey、Windows、Cortana、HoloLens、Mixed Reality和Skype語音翻譯等產品,推出新的語音片段配置。當用戶同意讓微軟員工及其承包商,聽取語音記錄來改善人工智慧技術,微軟會保留所有語音資料兩年,如果這些語音片段還進一步供人工轉錄使用,則可能會保留兩年以上。
熱門新聞

2026-03-06


2026-03-11




2026-03-06
2026-03-10