在揭露電腦視覺服務Amazon Lookout for Vision和設備偵測服務Amazon Lookout for Equipment之後,AWS現在還發布了一個新的機器學習服務Amazon Lookout for Metrics,可自動監控指標,協助企業達到提升速度和精確度等目的,或者診斷異常現象,快速掌握像是收入意外大幅降低,或大量付款失敗等事件。
資料中突如其來的模式改變,可能代表著異常事件發生,除了網站技術故障,但也或許是尚未開發的商機,AWS提到,隨著企業收集越來越多的資料,需要具備偵測資料的變化,並能及時做出反應的能力,但是要偵測這些資料變化並不是一件簡單的事情。而AWS所推出的Lookout for Metrics服務,可以讓企業更容易地使用機器學習技術來監控指標,以提高對事件的反應能力。
Look for Metrics不僅能用於簡單的異常檢測,其提供開發人員與Amazon內部使用相同的技術來監控指標,只要透過點擊操作,就可以開始監控重要的指標,用戶不需要對機器學習有任何使用經驗與知識,就可以監控異常並發現造成異常的原因。
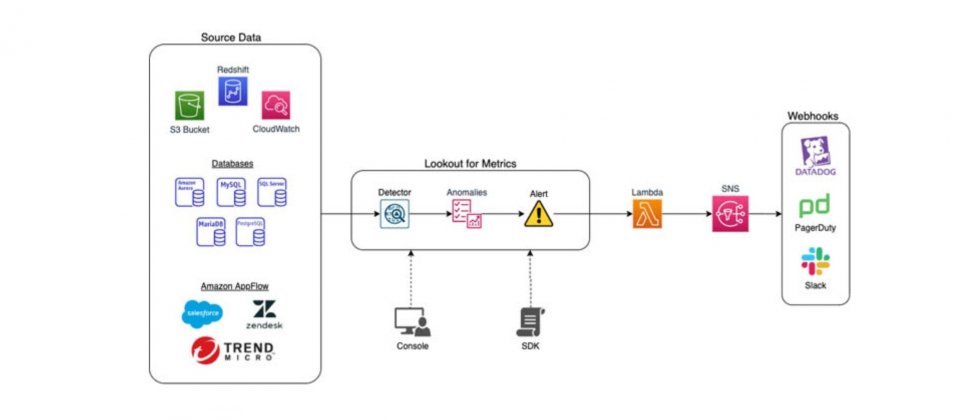
為了要理解用戶的資料,Look for Metrics利用偵測器對資料進行學習,用戶可以創建偵測器,並且選擇5分鐘就是1天等不同的時間區間,決定偵測器匯入資料的頻率,根據用戶選擇的時間間隔,偵測器要能偵測異常,需花費數小時或是數天來學習資料,不過,用戶也能透過提供歷史資料,來加速學習歷程。
該服務可以連接到19個資料來源,包括Amazon的服務S3、CloudWatch和RDS等,還有Salesforce、Marketo和Zendesk等應用程式,以持續監控業務上的指標,Lookout for Metrics能夠自動檢視和準備資料使用機器學習技術偵測異常,當有多個指標受到異常事件影響,相關的指標會被匯總在一起,並總結出造成異常的根本原因,另外,AWS提到,該服務還會按嚴重性對異常進行排名,讓用戶可以確認需要優先解決的問題。
Lookout for Metrics也能被連接到通知和事件服務,諸如Amazon SNS、Slack、Pager Duty和AWS Lambda,進而使用戶可以創建自定義警示或是操作,自動產生錯誤報告,或是從產品目錄中刪除價格不正確的產品。當Lookout for Metrics服務開始回傳結果時,用戶可以在控制臺和API,取得異常相關性的回饋,而服務精確度也會隨著時間提高。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10