Google發表了最新的機器人研究,同時也開源一個名為DeformableRavens的模擬基準,目的是要加速操作可變形物體的研究。DeformableRavens內含12個任務,包括操作線材、編織物以及袋子,同時附有一個模型基礎架構,可供其他研究人員,藉由圖像來指示機器操縱可變形物體。
目前機器人的研究,進展到了讓機器人可以抓握各種剛體,但是針對可變形物體的研究卻相當少,而抓握可變形物體的困難之處,在於很難指定這類物體的配置,研究人員舉例,剛性立方體可以確定固定點的配置,會與物體的中心點有關,因此能夠有效地描述其3D空間,但這種演算法很難描述編織物的狀態。另外,即便能夠具體描述可變形物的狀態,但其牽涉的動態力學仍然非常複雜,因為可變形物體在執行特定操作之後,很難預測其未來的狀態。
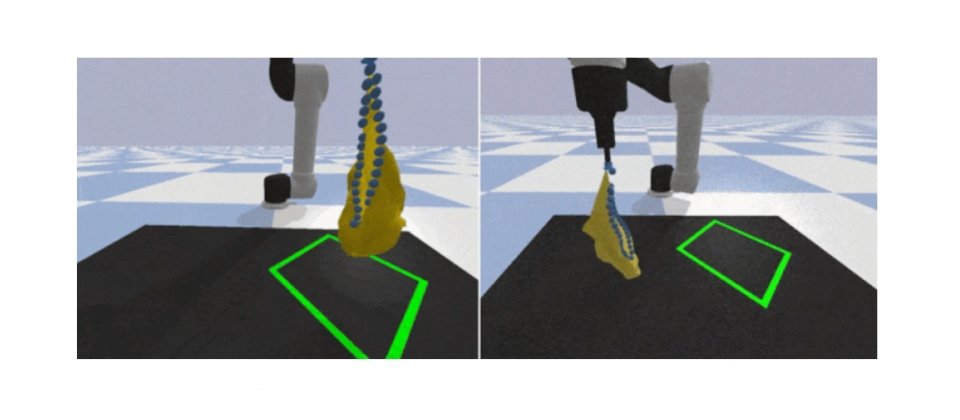
DeformableRavens專案所提供的基礎架構,能夠讓機器人重新排列線材,使其與目標形狀相符,也能把編織物平整地放到目標區域,甚至是把物體插入到背包中,研究人員提到,這是目前第一個模擬器,可以讓機器人將物品裝入袋中,這個挑戰的難處,在於機器人必須學會複雜的相對空間關係。
DeformableRavens是以Google先前在排列物體上的研究作為基礎,其12個模擬任務套件,針對1D、2D和3D的可變形結構,每個任務都包含一個模擬的UR5機器手臂,和一個抓捏的模擬抓取器,並與腳本演示程序綑綁在一起,可用來自動收集模仿學習(Imitation Learning)的資料。

對可變形物體來說,指定目標配置的操作任務可能更為有挑戰性,因為其複雜的動力學特性,和高維度配置空間,目標不如剛體的姿勢容易指定,而且像是把物品放進袋中這種任務,還涉及複雜的相對空間關係。因此除了腳本演示的任務之外,DeformableRavens基礎測試還包括以目標圖像指定的條件任務。對於有條件的任務,機器人必須操縱給定的物體,使其狀態與圖像中的物體配置相符。
研究人員提到,為了在模擬基準中補充目標條件(Goal-Conditioned)任務,他們將這些目標條件整合到了之前所發布的Transporter Network基礎架構。這個基礎架構是以動作為中心(Action-Centric)的模型基礎架構,可以透過重新安排深層特徵,從視覺輸入推測出空間位移,以便良好地操縱剛體。

該基礎架構需要將目前環境的圖像、目標圖像以及最終物體配置作為輸入,計算這兩個圖像的深度視覺特徵,藉由組合這些特徵,以操作場景中的剛體以及可變形物體。研究人員解釋,Transporter Network基礎架構的優勢在於,其保留了視覺圖像的空間結構,可以提供歸納偏置(Inductive Bias),將圖像為基礎的目標條件,重新建構成為一個更簡單的特徵配對問題,進而提高了卷積網路的學習效率。
Google的研究顯示,目標條件的Transporter Network基礎架構,能夠良好的操縱可變形物體到指定的配置,研究人員也對2D和3D變形物體測試,Transporter Network基礎架構處理變形物體的能力,比過去方法大為進步,機器人所學習到的策略,可以有效地模擬裝袋任務,研究人員透過提供目標圖像,可讓機器人自己推測需要將物體放進哪一個袋中。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-12


2026-02-10

2026-02-06