臉書開源了FLORES-101資料集,這是一個涵蓋101種語言的多對多評估資料集,可以用來測試並且改進多語言翻譯模型。
臉書最近發表了重要的語言模型M2M-100,能夠翻譯100種不同的語言,但是臉書提到,新的翻譯系統需要使用更為先進的工具進行測試。因此他們創建了FLORES-101,用來突破語言障礙,並且協助開發人員創建更多樣化的翻譯工具,臉書現正製作更加完整的FLORES-101資料集、技術報告和數個模型,供研究社群使用,以加速全球翻譯系統的發展。
之所以評估很重要,臉書解釋,這就像是烤蛋糕一樣,如果無法品嚐蛋糕,就無法知道優缺點,也就沒辦法在之後進行改進,而評估翻譯系統效能的道理相同。評估翻譯系統一直是人工智慧研究人員的挑戰,當無法良好地衡量或是比較翻譯系統的結果,就無法發展出更好的翻譯系統,臉書表示,人工智慧社群需要一個開放且易於取用的方法,來評估和測量多對多翻譯模型,並且方便地與其他模型進行比較。
過去這個工作很大程度仰賴英文翻譯,但這僅有英語使用者受益,不足以滿足需要準確翻譯區域語言的需求,像是在印度,憲法就承認了20種官方語言。為了解決這個問題,臉書創建了FLORES-101資料集,這個資料集主要針對低資源語言,像是蒙古語和烏都語等,這些語言目前都沒有可用於自然語言處理研究的大量資料集。

透過FLORES-101,研究人員首次可以利用10,100個不同語言方向,可靠地評估翻譯品質,像是從印地語到泰語或是史瓦希利語,臉書提到,他們從一開始在設計FLORES-101的時候,就考量到多對多翻譯,這個資料集包含所有語言相同的語句集,讓研究人員可以評估任何方向翻譯的效能。
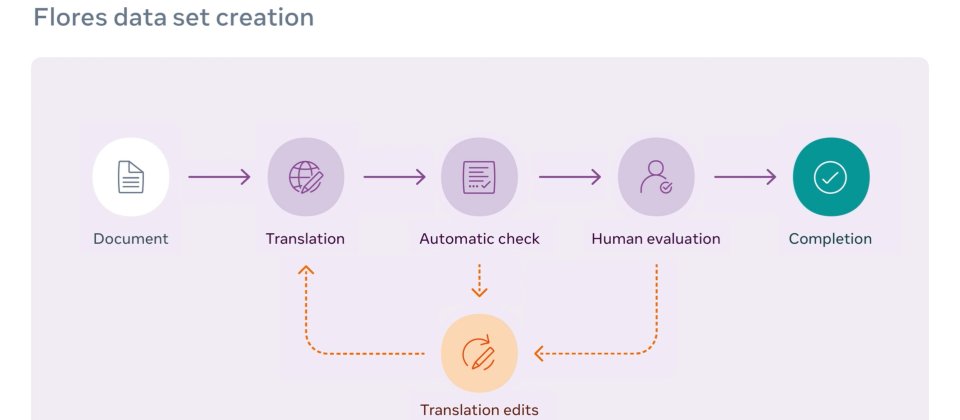
FLORES-101資料集經過許多人工步驟製作而成,每個文件都由專業翻譯人員翻譯,再以人工編輯進行驗證,臉書還找人來檢查拼寫、語法、標點和格式,以控制翻譯的品質,並使用商業引擎的翻譯進行比較。之後由另一組不同的翻譯人員進行人工評估,找出包括不自然的翻譯和語法等錯誤,根據錯誤的嚴重程度重新翻譯。
除了要求翻譯品質之外,FLORES-101的特點包括針對低資源語言設計,在FLORES-101中有80%的語言都是低資源語言,而且翻譯的文字橫跨多個領域內容,有新聞、旅遊指南和不同主題的書籍。
FLORES-101的翻譯文字都是以文件為單位,臉書提到,機器翻譯的最新研究顯示,需要文件或是超過單一句子的翻譯資料集,藉由將上下文列入考量,才會使翻譯效果更好,而FLORES-101中翻譯文件中的多個相鄰句子,可以用來評估加入上下文考量的翻譯品質。另外,FLORES-101還提供了翻譯的後設資料,包括超連結、URL、圖像和文章標題等資訊。
臉書表示,FLORES-101是一個實現多對多模型評估的資料集,並且透過這個新的資料集,可以加速包括M2M-100等多語言翻譯模型的開發工作,尤其使得低資源語言的機器翻譯,能夠獲得更多的進展。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-06

2026-02-09