
Uber
除了減少供應端硬體成本,Uber大數據平臺省錢策略還另一個重點戰略,就是從大數據需求端下手。Uber大數據平臺資深主任工程師Zheng Shao甚至強調,從需求端下手,比降低供應端硬體成本更重要。
「Uber大數據平臺有上千位內部使用者,從深度技術專家到非技術的業務都包括在內,」Zheng Shao在官方部落格上寫道:「這麼龐大、不同性質的使用者,對大數據平臺成本效益造成負面影響,比如,Uber大數據儲存和運算資源有限,不知道該將資源優先給誰。」這個問題,就是Uber大數據平臺的多租戶難題(Multi-tenant problem)。
和許多企業一樣,Uber大數據平臺使用者橫跨多單位,不論是技術端的資料工程師、機器學習工程師、後端工程師,還是業務端的產品經理、業務分析師都算在內,每個人手上更負責不同的業務線。
這種錯綜複雜的關係,不僅造成Uber無法深入了解每項業務,再加上大數據儲存和運算資源有限,Uber無法決定該將資源優先分配給哪些使用者。也因為缺乏詳細的所有權角色劃分,Uber難以確定哪些人該為大數據資源的使用負責、付費。
這不只是Uber談大數據需求端成本效益時遇到的問題,也是許多企業發展大數據業務時,會遇到或正在經歷的挑戰。不只如此,Uber也面臨其他困境,像是當硬體資源有限時,如何決定大數據工作優先順序,來提供高品質的服務?又或是,如何確保自己擁有足夠的容量來應付需求尖峰,而且在閒置時又不產生過多成本?面對臨時作業需求,Uber能否彈性提供低成本的硬體資源?
作法1:劃分所有權,打造專屬用量管理工具
為何Uber認為,控制大數據平臺成本效益,需求端很重要?這是因為,Uber營運靠創新,大數據工作負載大多是實驗性的,內部使用者得不斷嘗試新實驗和機器學習模型。為滿足使用者不斷嘗試的需求,Uber打造一系列工具,來讓使用者管理自己的實驗需求,使用者也能同時知道,自己的實驗如何耗費大數據平臺資源,來精準調整用量。
也因此,在開發管理工具前,Uber先劃分大數據平臺儲存量、運算量和工作量的所有權角色,鎖定出關鍵資源使用者,就像是先找出債主,之後才能用來把關大數據資源用量,甚至是用來計價大數據平臺資源用量的依據。Uber在劃分所有權時,特別強調3點,首先是人員,因為組織內部人員會異動,不同組織也會隨著時間重新調整,因此得定義清楚定義所有權角色。
再來是資料族譜(Lineage),也就是涵蓋資料從上游產出、加工,再到下游運用的一系列追蹤記錄,就像是資料的血統演變。一般來說,一個完整的資料流程包含數十個步驟,每個步驟都可能由不同人或團隊負責,在多數情況下,資料所有權很難單一歸給資料生產者、資料處理者或資料使用者。Uber就利用領域知識,來把所有權一一劃分給資料處理流程中的各個負責人。
最後是所有權的顆粒度。因為一套資料集中,可能會有不同角色使用特定資料,比如,產品團隊需要某段時間的資料,過了那段時間,就希望刪除,但對法遵團隊來說,會希望這些資料儲存久一點。如何滿足不同角色對同一資料的需求,是Uber所有權顆粒度劃分的重點。
他們也根據這3大層面,自建了一系列工具來劃分所有權,比如用組織圖表和階層式所有權管理工具,來掌管資源使用者。Uber也正評估新方法,來打造所有權顆粒度工具,要讓不同團隊順利存取資料集中的特定資料。
用Databook掌握資料族譜
至於資料族譜,他們也早在2018年,就開發一套資料追蹤工具Databook,來掌握資料處理歷程資訊,特別是詮釋資料(Metadata)。當時,Uber正面臨業務快速擴增,2016年,他們新增外送服務Uber Eats、卡車貨運服務Uber Freight、單車共享服務Jump Bikes,2年後,每日出行次數超過1,500萬趟,每月活躍用戶更超過7,500萬人。
這種增長,讓資料系統和工程架構越來越複雜,比如,在他們使用的分析引擎Hive、Presto和Vertica中,已經散落著數以萬計的表格。隨著業務擴張,表格數量和詮釋資料跟著暴增,為了讓內部的業務分析跟上公司發展腳步,Uber 4年前開發出Databook,就像是一個集中站,能管理、顯示Uber內部所有的詮釋資料,讓使用者更容易探索、運用這些資料。
使用者可透過Databook了解資料的背景,像是資料的意義、品質,更讓這些關鍵訊息,不在上千次的分析中遺失。這些詮釋資料,還能讓Uber內部的工程師、資料科學家、作業團隊不再只是觀察原始資料,而是能將資料轉化為可實際動手運用的知識。
這就是Uber用來追蹤資料族譜的自動化方法。
作法2:掌握每項業務需求
前段劃分好大數據工作負載的所有權後,接下來第2步,就是根據這些所有權角色,來預測大數據資源的需求變化,並評估是否超出預期,來調整資源用量。
Uber觀察發現,大數據平臺需求增長有2種原因,一是業務事件增加,也就是Uber出行次數和UberEats訂單數一旦增加,大數據工作負載需求就會增加。另一個原因是單一業務事件增加,也就是新功能、更多實驗的出現,也可能是更多詳細的日誌出現,或是更多資料分析和機器學習模型出現,這些也會造成大數據資源需求增長。
Uber大數據成本效益團隊,每個月會檢查每個所有權小組的大數據資源使用量,是否超出預期。如超過預期量,這些小組就得自行找出原因,也得自己想辦法降低用量。但有些所有權小組太龐大,無從找出原因,因此會請Uber大數據成本效益團隊來拆解。
自建資料方塊工具,使用者輕鬆了解資源用量
為此,團隊也開發一套資源用量的資料方塊(Data Cube)工具,方便大數據平臺使用者,進一步了解不同維度資料使用大數據資源的狀況。進一步來說,有別於傳統的平面資料表,資料方塊是由一系列的維度和度量組成,原理就像立方體般,能更完整掌握資料性質。
比如,在Uber的Hadoop分散式檔案系統HDFS用量資料方塊中,光是維度,就涵蓋了區域、HDFS叢集、HDFS層、HDFS目錄、Hive資料庫、Hive表格、Hive分區等,而度量則包括檔案數、字節數、預計年度成本。
接著,使用者可從這款工具的介面,選擇不同條件、維度分類和度量等,來查看用量細節,不僅能視覺化觀察不同資料消耗的大數據平臺資源,還能幫助使用者找出原因、節省成本。
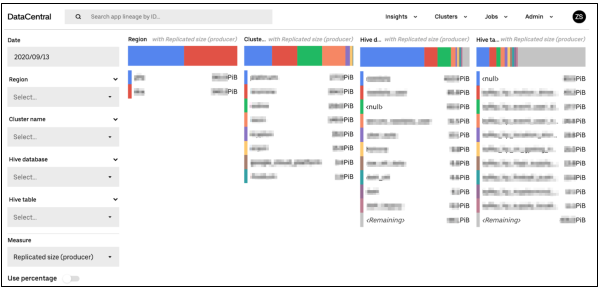
Uber大數據平臺成本效益團隊打造一套資料方塊工具,可讓大數據平臺的使用者小組,來查看自己的資料如何消耗平臺資源,並進一步找出可省錢之處。(圖片來源/Uber)
作法3:主動分析詮釋資料,找出無用資料集
除了被動的視覺化呈現大數據平臺資源需求變化,Uber也主動分析詮釋資料,來找出可再節省的資源。
在他們的觀察中,有2點是非常能節省大數據平臺成本的。其一就是管理無用的資料集,也就是在過去180天內都沒人讀寫的資料集。這些集多半是隨著應用範例而生,像是實驗或臨時的分析任務等。這些資料表的擁有者,通常只想持有這些資料一段時間,但很少人會在完成後刪除資料。
於是,Uber設計一套提醒系統,能自動生成任務,每隔90天就問使用者,是否還需要這些無用的資料集。此外,Uber也新增了表格等級和分區等級的TTL(存活時間)支援,會自動刪除資料表或表中的分區。
另一個能節省大數據需求成本的,則是孤立的工作流程,也就是在過去180天內,都沒人讀取的ETL工作流程產出的資料集。而這些資料集,也類似無用的資料集,都是擁有者可以刪除的。
作法4:下一步自動決定工作優先順序
Uber大數據平臺有著各式各樣的使用者、工作和資料表,團隊現在也正擬定一套指引,來劃分工作層級,並根據這些層級提供所需資源,使用者也得依此付費。接下來,Uber大數據成本效益團隊會與定價部門,設計一套優化演算法,來在低成本的條件下,提供最佳客戶體驗。
不只如此,Uber還聯手線上運算平臺和線上儲存平臺的同事,要將原本的大數據工作負載,轉換為線上工作負載,比如使用線上服務、線上儲存等,來降低大數據平臺的需求負擔。這正是他們未來2、3年的目標。
Uber大數據需求端省錢術
1. 劃分所有權,找出大數據平臺資源使用者
2. 自建資料族譜追蹤工具,將資料轉為知識
3. 建立資料方塊工具,掌握資源用量
4. 主動分析詮釋資料,找出無用資料集
5. 制定計價機制,使用者付費
資料來源:Uber,iThome整理,2022年2月

熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-06

2026-02-09