
不讓Meta的Make-A-Video專美於前,Google也在本周發表兩款文字轉影片工具,分別是強調影片品質的Imagen Video,以及主打影片長度的Phenaki。
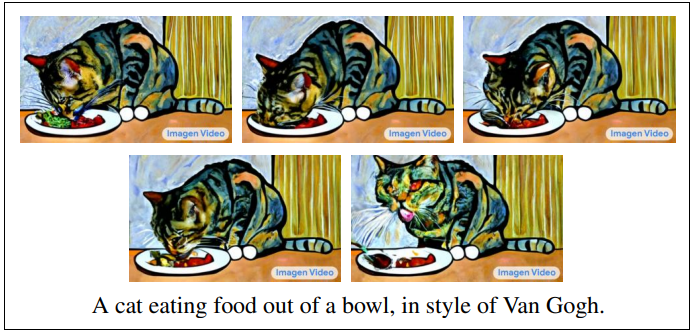
其中,Imagen Video奠基於Google的Imagen文字生成圖像人工智慧系統上,採用串連擴散模型(Cascaded Diffusion Models,CDM)來產生高解析度的影片。先透過自然語言處理預訓練模型T5嵌入使用者所輸入的文字後,由一個基本的影片擴散模型以每秒3幀的速度產生一個解度析為24x48的16幀影像,之後再利用多個Temporal Super-Resolution(TSR)與Spatial Super-Resolution (SSR)模型,最終產生每秒24幀,總長128幀且解析度高達1280x768的5.3秒影片。
Google是以公開的LAION-400M圖像/文字資料集,以及6,000萬筆圖像與文字的配對,再加上1,400萬筆影像與文字的配對來訓練Imagen Video,並宣稱Imagen Video可用來創造類似梵谷(Van Gogh)水彩畫風的影片。
至於Phenaki則可用來建立總長多達數分鐘的影片,只是影像品質不若Imagen Video。Phenaki可將一段具備一定長度的提示文字變成任意長度的影片,或許只是一段一直騎著摩托車的影像,或者是有一頭獅子奔馳在長型的辦公桌上,最後卻穿上了西裝辦公。令人驚喜的是,Phenaki所呈現的影片非常貼近文字描述,而且Google認為它不僅可用來產生描述單個概念的影片,還能可根據一系列的文字,產生有連貫性的多個影片。

圖片來源/Google
由於圖像資料集的數量遠大於影片,使得不管是Imagen Video或Phenaki都同時利用影片與圖像進行訓練,並發現它的確對產出的品質與多樣性都有所助益。
有鑑於用來訓練Imagen Video的資料中可能含有許多不適當的內容,因此Google目前並不打算釋出或開源該模型。
熱門新聞



2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13