微軟公開Project Florence的最新成果,公開預覽Florence基礎模型,該模型現在已整合至Azure Cognitive Service for Vision,提供新的電腦視覺服務。新的視覺服務提供自動圖說、智慧裁切、分類、背景移除和圖像搜尋等功能,同時該服務還提供負責任人工智慧功能,用戶可以控制追蹤活動、分析環境,並接收即時警示。
Project Florence是微軟的人工智慧認知服務研究計畫,目的是要研發先進的電腦視覺技術,開發下一代電腦視覺辨識框架。官方提到,從2012年深度學習技術有所突破以來,圖像分類的準確率,已經從50.9%上升到90.2%。
但是微軟認為,距離實際應用電腦視覺技術仍有一段路要走,通用物件偵測的精確度只有65.9%,無法實際應用在關鍵任務,況且在影片上的應用挑戰更大。因此微軟想藉由Project Florence,推進電腦視覺技術的發展。
微軟在2021年發表《Florence: A New Foundation Model for Computer Vision》論文,Florence是一個電腦視覺的基礎模型,在資料集ImageNet-1K零樣本分類中,top-1精確度達到83.74%,top-5精確度可達97.18%。微軟提到,該模型經數十億筆圖像文字資料進行訓練,現在整合至Azure Cognitive Service for Vision,提供生產用電腦視覺服務。
微軟開始在旗下的應用程式中整合新的視覺服務,包括Teams、PowerPoint、Outlook、Word、Designer、OneDrive等Microsoft 365應用程式,Teams應用新模型的圖像分割功能,而PowerPoint、Outlook和Word以模型替圖像自動產生替代文字,以提高無障礙性,Designer和OneDrive則是運用新視覺服務的圖像標記、圖像搜尋和背景生成,以簡化圖像搜尋和編輯任務。另外,Microsoft Datacenters也使用新的視覺服務,強化安全性和基礎架構可靠性。
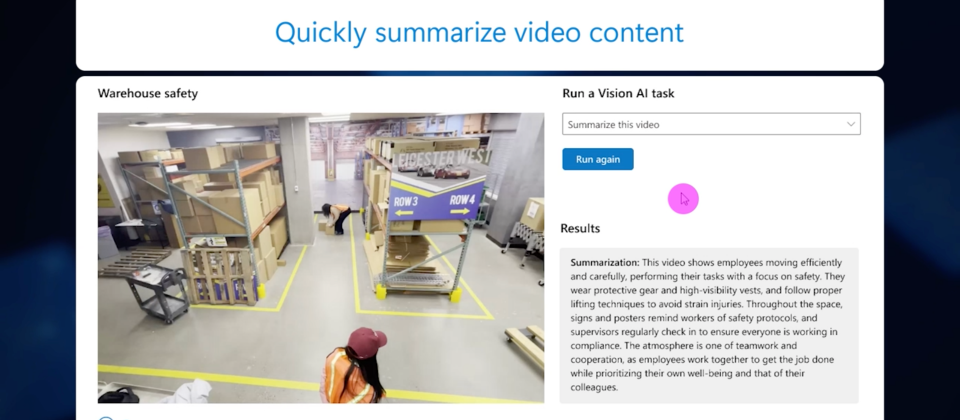
用戶現在可於Vision Studio立即試用由Florence基礎模型所加持的電腦視覺功能,諸如圖說生成、圖像搜尋、背景移除、模型自訂等功能。在Vision Studio中還能試用影片總結功能,不需要額外的後設資料,讓用戶可直覺地搜尋影片內容。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-12


2026-02-10

2026-02-06