圖片來源:
微軟
微軟周二(3/21)宣布,已於新版Bing及Edge上提供基於最新DALL-E模型的Bing Image Creator,讓使用者只要輸入文字敘述就能自動產生圖像。DALL-E為OpenAI所開發的文字轉圖像AI模型,去年9月即開放外界試用。
微軟表示,研究顯示人腦處理視覺資訊的速度是處理文字的6萬倍,代表視覺工具為人們搜尋、建立及取得理解的重要工具,此外,影像也是人們最常搜尋的類別,僅次於網頁搜尋,過去的搜尋侷限在網路上的既有影像,而現在則幾無限制。
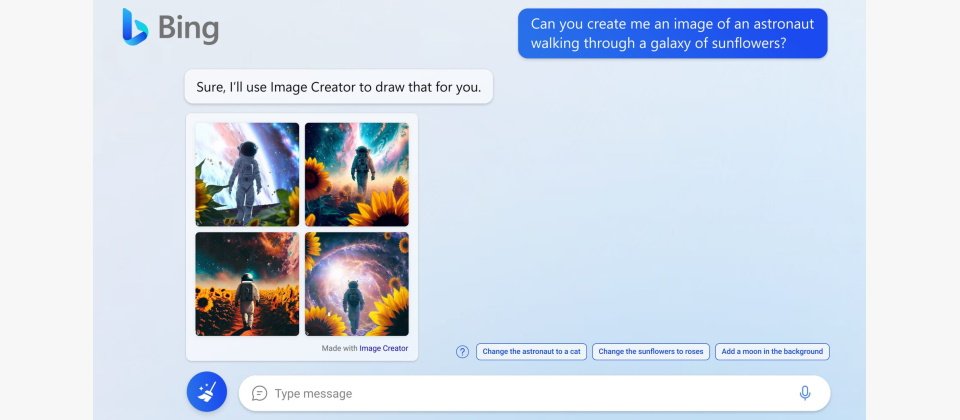
微軟已將Bing Image Creator整合在基於ChatGPT的Bing聊天功能上,初期僅出現於創意(Creative)模式,只要輸入「create an image」等文字提示,就能呼叫圖像生成功能;也將它整合在Microsoft Edge上,可透過側邊欄的Bing Image Creator圖示進入;或是可直接造訪bing.com/create來試用Bing Image Creator。
在Bing Image Creator中,使用者可輸入影像的文字描述,甫以諸如地點或活動的其它脈絡,再選擇藝術風格,系統就會自動產生使用者想像中的圖像。
為了避免遭到濫用,微軟亦與OpenAI合作以共同捍衛Bing Image Creator的安全性,例如在偵測到有害的影像描述時,即會封鎖並跳出警告,也會在由Bing Image Creator產生的圖像上註明出處。
目前Bing Image Creator僅支援英文,微軟已計畫讓它支援更多的語言。
熱門新聞

2026-02-16




2026-02-13

2026-02-16

2026-02-16

2026-02-17
Advertisement