
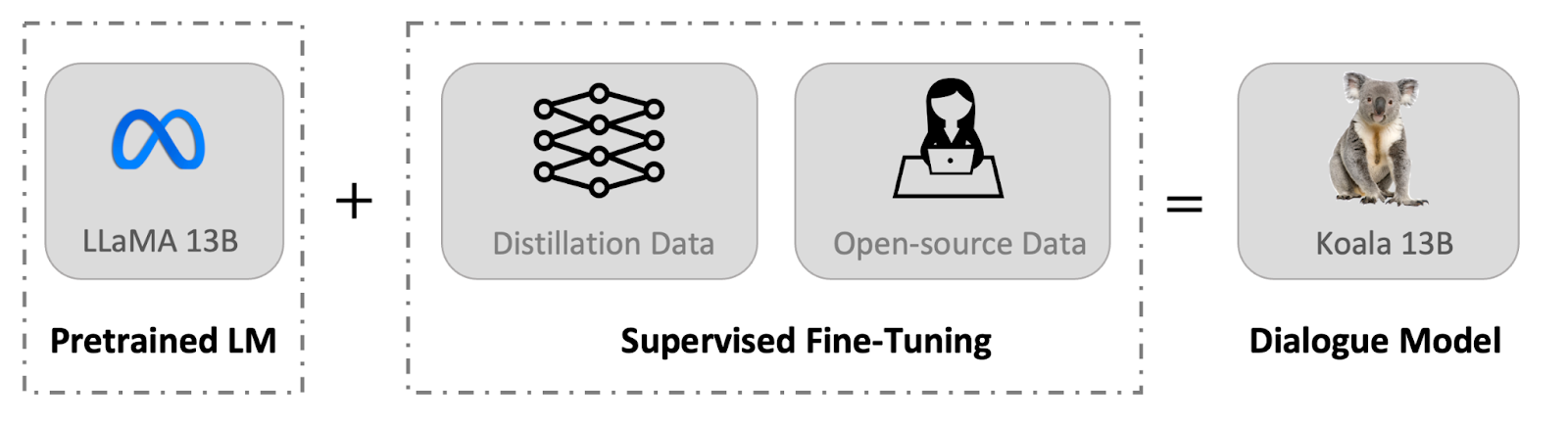
美國頂尖大學聯手打造類似GPT-4的大型語言模型Vicuna,訓練成本只有300美元,但效能媲美史丹佛大學的Alpaca,產出的答案更詳細也更結構化。
螢幕截圖
重點新聞(0331~0406)
GPT-4 Vicuna 大型語言模型
美頂尖大學聯手用300美元訓練出類GPT-4的大型模型Vicuna
在史丹佛大學用600美元打造ChatGPT複製版的模型Alpaca後,包含CMU、加州大學柏克萊分校、史丹佛大學和加州大學聖地牙哥分校在內的幾間美國頂尖大學,共同打造並開源一款類GPT-4的大型語言模型Vicuna,具130億參數,產出的回答可達等同ChatGPT九成的品質,且比Meta的LLaMA和史丹佛大學的Alpaca還要好,但訓練成本才300美元左右。
Vicuna的訓練資料來自微調後的LLaMA,以及從ShareGPT收集的對話。ShareGPT是一個讓使用者分享自己與ChatGPT對話的網站,團隊在該網站收集了7萬多個對話,並強化了Alpaca產出的訓練腳本,來加強模型對多輪對話和長序列文字的能力。他們在1天內,以8個A100 GPU和PyTorch FSDP完成Vicuna的訓練,後來,團隊也設置80個多元的問題,讓不同模型來回答問題,並以GPT-4來評估這些模型的回答,包括Vicuna、Alpaca、ChatGPT和LLaMA。其中,Vicuna的總分是ChatGPT的92%,且生成的答案比Alpaca還要詳細、更有結構。但團隊指出,Vicuna在程式碼生成和基本數學問題的表現仍有待加強,且安全性也需進一步強化。(詳全文)


UC Berkeley Koala 大型語言模型
UC Berkeley打造研究查詢專用對話模型,打下LLM私有化基礎
加州大學柏克萊分校(UC Berkeley)最近發表一款對話式大型語言模型Koala,可回答研究相關的查詢問題,甚至模型產出的多數答案,比史丹佛大學的Alpaca模型要好,且至少一半的答案品質與ChatGPT相當。
進一步來說,團隊先是收集網路上的對話資料,包括來自公開資料集和高品質的生成式AI對話,如ChatGPT/ShareGPT、Alpaca等,來微調Meta的LLaMA模型,並以此來訓練Koala模型。他們從ShareGPT收集的對話有6萬個示例,後來精簡為可用的3萬個,並採用HC3英語語料庫中人類與ChatGPT的問答共8萬7千多例,來訓練Koala。不只如此,他們也從Alpaca、開放式資料集OIG、OpenAI WebGPT等處收集高品質的訓練資料,並打造70億參數和130億參數版本的Koala。
後來,團隊透過Amazon Mechanical Turk群眾外包平臺來評估Koala和Alpaca的效能,也就是讓100位使用者評比哪種回答較好,發現近一半的回答評為比Alpaca好,近70%則與Alpaca相當或比它好。團隊指出,雖然Koala的安全性和一致性仍有很大的進步空間,但與其他LLM相比,這種採用少量高品質資料訓練而成的模型,效能與千億參數的LLM相當,等於提供一種LLM私有化的發展基礎,也就是能自行訓練出等同於科技巨頭的大型語言模型。(詳全文)
Google ViT-22B 機器人
Google將ViT擴大到220億參數,還結合LLM來執行機器人任務
Google在3月底發表一篇部落格文章,說明團隊如何將Transformer電腦視覺模型ViT擴展至220億個參數,也就是ViT-22B,比之前同類型最大模型ViT-e大了5.5倍(原40億參數)。早在2月,團隊就已發表ViT-22B論文,這次則說明模型擴展方法,也就是結合了如PaLM模型採用的擴展方法,同時運用QK正規化來改善訓練穩定度,以及非同步平行線性操作來改善訓練效率。
也由於ViT-22B有新架構和更有效率的分片配方,所以能在硬體利用率高的Cloud TPU訓練。此外,ViT-22B也因為使用凍結表示(Frozen representation)或全微調,因而在許多電腦視覺任務上都達到SOTA等級。特別的是,ViT-22B還能整合到擴展版的大型語言模型PaLM-e中,成功執行電腦視覺和自然語言任務,大幅提高機器人任務能力。(詳全文)
OpenAI GPT-4 安全性
等了6個月才發表GPT-4,OpenAI揭露AI安全性作法
儘管生成式AI帶來各種可能,也隱含不少安全風險。OpenAI近日公開AI安全性做法,他們指出,在發表任何新系統前,團隊都會進行一系列嚴謹的測試,並請外部專家提供回饋,藉由這種人工回饋強化學習技術來優化模型表現,同時打造監控系統,來觀測模型使用狀況。
OpenAI透露,正因此,他們訓練完GPT-4後,額外花了6個多月來評估模型,確保模型的安全性和一致性,並有強大的監控系統,來防範濫用情況,比如使用者試圖上傳兒童性虐相關素材時,該系統會阻止該行為並通報美國受虐兒童中心。此外,OpenAI也與非營利組織Khan Academy合作,共同開發符合安全規範的AI助手,來作為學生的虛擬老師,也是老師的課堂助手。OpenAI同時也正開發輸出設定功能,要讓開發者用來調整模型輸出,能更嚴格控管輸出內容。
同時,OpenAI也主張從實際應用來改善AI安全性。因為,僅在實驗室中評估,無法預測人們所有的運用方式。於是,OpenAI透過API提供模型技術,讓開發者將模型嵌入自己的應用程式,這種方法,讓OpenAI可掌握濫用行為並有所作為,也能從現實經驗中來制定更細緻的政策,來預防濫用風險。雖然現在只有ChatGPT Plus的訂閱用戶可使用GPT-4,OpenAI表示,他們希望以後能讓更多民眾使用。(詳全文)
Meta 圖像分割 訓練資料集
Meta開源圖像分割AI模型和訓練資料集
Meta最近開源圖像分割AI模型和訓練資料集,也就是Segment Anything Model(SAM)和Segment Anything 1-Billion(SA-1B)。圖像分割(Image segmentation)是電腦視覺的重要技術之一,它能辨識特定物件的像素,並將這些像素遮罩起來,就像是替特定物件著色一樣。圖像分割可用於多種領域,如相片編輯,但要建立準確的圖像分割模型,得要有大量標註的資料,以及模型基礎架構。
於是,Meta發起Segment Anything專案,要打造圖像分割底層模型,來降低建模、打造基礎架構和資料標註的門檻。他們訓練的SAM模型經多元資料和不同任務訓練,可像NLP模型一樣按照提示執行,而且SAM可為圖像和影片中任何物件產生遮罩,包含訓練時未遇過的物件和圖像類型,涵蓋多種應用情境,甚至是水底相片或細胞顯微影像等新型應用領域。Meta指出,SAM還能作為大型AI系統的一部分,或整合提示工程來發展多模態應用,如理解網頁影像和文字內容,或用於AR/VR系統中,來根據使用者視線選擇物件,再將這個物件升級為3D物件。(詳全文)

VS Code 程式碼 Copilot Chat
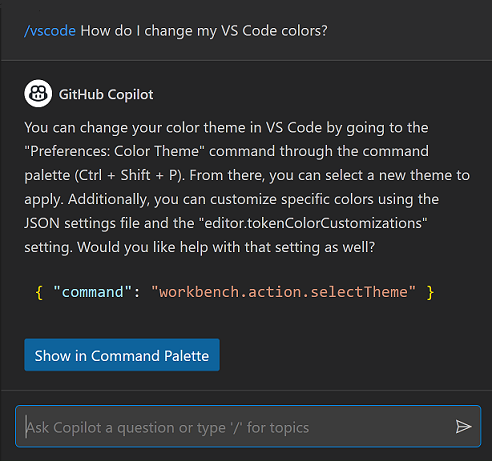
VS Code 1.77新預覽功能,開發者在程式碼行內就能與AI對話
微軟最近推出新版開發環境VS Code 1.77,新版本加強了GitHub連結,還提供TypeScript/JavaScript的switch陳述式自動完成功能,開發者也能使用最新的Copilot Chat整合功能,在編輯器內直接向AI提問、得到程式碼建議。
進一步來說,VS Code 1.77與Copilot Chat更深度整合,Copilot會在開發者處理程式碼時,直接在程式碼行內顯示建議,開發者也可隨時在程式碼編輯器中向Copilot提問,並要求Copilot尋找程式碼內的臭蟲或解釋程式碼的意義,甚至是建立測試。Copilot的對話框現在會出現程式碼的下方,供用戶輸入指令。開發者要使用這項深度整合功能,除了需要獲得Copilot Chat存取權限外,還要安裝GitHub Copilot Nightly版本擴充套件,以及Insiders版本VS Code。(詳全文)
Databricks 製造業 資料湖倉
Databricks推出製造業資料湖倉,加速資料分析和AI開發
Databricks近日推出製造業資料湖倉平臺(Lakehouse for Manufacturing),在自家原有的核心資料湖倉平臺上,開發出適合製造業的資料分析解決方案和預建加速器,來支援數位雙生、物料預測、設備效率分析等應用。
Databricks資料湖倉是一種新型資料架構,整合了資料湖和資料倉儲,可同時處理結構化和非結構化資料,且支援即時的資料處理與分析。此前,Databricks就已針對醫療業和金融業等產業推出專用資料湖倉解決方案,現在進一步發展出製造業專用平臺,單一平臺就能處理製造業因龐大資料量而產生的儲存和倉儲連結問題,並統合結構化與非結構化資料分析作業,改善過去分析碎片化問題。此外,使用者還還能採用,支援各種工業資料應用的內建解決方案加速器,來加速數位雙生、物料預測、設備效率分析、電腦視覺和預測性維護等應用的開發。(詳全文)
Meta 生成式AI 廣告
Meta預計下半年用AI生成廣告
Meta技術長安德魯.博斯沃思(Andrew Bosworth)日前透露,Meta要在廣告業務中,大量使用AI來替企業客戶生成廣告,預計今年下半年開始。博斯沃思接受日經亞洲採訪時,說明Meta將以AI來改善核心業務,旗下產品Facebook、WhatsApp和Instagram會先開發由AI生成的廣告給受眾。
他指出,Meta幾個月前剛成立生成式AI團隊,是他與執行長祖克柏和產品長Chris Cox投資最多時間和精力的專案。而該團隊的目標,就是要用AI來優化文字訊息(應用於WhatsApp和Messenger)與圖像生成(如Instagram濾鏡和廣告),透過AI生成廣告也是目標之一,甚至未來,Meta希望透過大型語言模型來建立3D模型,進而推動虛擬世界和元宇宙業務發展。(詳全文)
圖片來源/CMU、UC Berkeley、Google、Meta、微軟
AI近期新聞
1. 華為打造參數破兆的大型語言模型盤古-Σ
資料來源:iThome整理,2023年4月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-12


2026-02-10

2026-02-06