OpenAI
OpenAI周一宣布ChatGPT即將讓用戶以語音輸入指令或上傳圖片,而且終於能開口說話。
語音、圖像辨識新功能將在2周內部署給ChatGPT Plus及Enterprise用戶,不過OpenAI表示「很快」也會推向開發人員及免費版用戶。
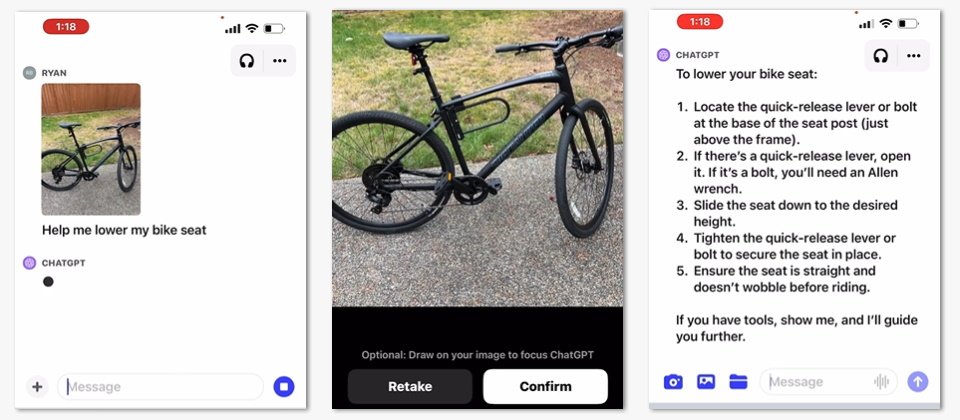
支援語音互動和圖片辨識讓ChatGPT有更多元應用。用戶可以直接說出想要ChatGPT執行的任務、聽它的答案,再和這個聊天機器人來回對話。像是要求它為家人說一個床邊故事,或是設定晚餐桌上的辯論。加上圖片辨識能力則讓使用場景更為靈活,像是在旅行途中拍下知名建物詢問有趣故事,或是拍攝冰箱照片,讓ChatGPT建議菜單,並在邊做菜時邊向它討教作法。用戶也可以拍攝數學習題上傳ChatGPT,請它分享解題技巧給大人和小孩。
OpenAI表示,最新的語音能力是在新的語音合成(text-to-speech)模型上開發,它能以數秒鐘的語音樣本及文字生成逼真的人聲。目前OpenAI提供5種人聲,每種聲音都是OpenAI和專業聲優合作開發出來。OpenAI並使用開源語音辨識系統Whisper將語音轉錄為文字。
而圖片辨識則是以多模GPT-3.5和GPT-4為底層。這些模型將語言理解能力應用在包含文字和圖片的段落、螢幕擷圖及文件上。最新功能允許用戶上傳多幀圖片,或使用其繪圖工具引導ChatGPT畫一張圖。
OpenAI強調,基於技術風險,該公司選擇逐步釋出這些進階功能,例如語音合成可能給了歹徒詐騙或Deepfake名人的機會,而視覺模型目前仍有對人臉幻覺,以及在重要領域仍仰賴模型解釋圖片的問題。為此,在語音合成上,目前OpenAI僅發展語音對話,但是該公司也在實現其他應用,例如Spotify以OpenAI技術測試podcast的語音翻譯功能。至於圖片辨識,在大規模推廣前,OpenAI已展開模型偏激性及科學能力的測試,以探詢負責任的用途。
新的視覺辨識功能提供給所有平臺,包括Windows及行動版App。語音輸入功能則只部署到iOS和Android版。要使用圖片辨識功能,需以App上的相片鍵拍攝或選擇圖片。iOS或Android手機版App上則需要先按「+」號。語音輸入功能方面,需用戶從App的「設定」區>「新功能」下加入(opt-in)啟動語音對話。之後使用者可按下ChatGPT主頁右上方的耳機按鍵,選擇喜歡的聲音完成設定。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-12

2026-02-10


2026-02-06