
AI2
重點新聞(0126~0201)
AI2 開源 OLMo
號稱真正開源!AI2釋出OLMo語言模型和所有相關資料
艾倫AI研究所(AI2)最近釋出2款語言模型OLMo 7B和OLMo 1B,而且有別於常見做法、只開源模型權重和推論程式碼,AI2不只釋出OLMo模型,還包括完整的框架,也就是訓練資料、訓練程式碼和評估程式碼等,要樹立真正開源的新典範。他們希望,這個做法能推進開放研究社群的進展,並激發創新。
AI2這項研究專案主要與哈佛大學合作展開,參與者還有AMD、Lumi超級電腦、Databricks和華盛頓大學。在這項專案中,他們釋出了一系列AI模型開發的重要資料,首先是完整的預訓練資料集,這個資料集以AI2的Dolma開源資料集為基礎(供3兆個Token)打造,同時包含OLMo語言模型預訓練程式碼。再來是訓練程式碼和模型權重,包括了70億參數(7B)規格的4種版本,每種模型至少都使用2兆個Token訓練,且推論程式碼、訓練指標和訓練日誌也都一併提供。還有一個是評估工具,他們釋出了用於開發階段的評估套件和評估程式碼。Hugging Face的技術長Julien Chaumond還在LinkedIn上指出,AI2釋出的模型、權重、評估指標和訓練程式碼,是開源研究的重要進展。(詳全文)
AIOps AI原生網路平臺 Juniper Networks
Juniper發表AIOps服務
網路設備與系統廠商Juniper Networks最近新推一款AIOps服務,也就是AI原生網路平臺,要用AI來提高營運和終端使用者體驗,同時降低網路維運成本,確保裝置、使用者與應用程式的網路連接都安全可靠。
進一步來說,Juniper Networks這款平臺是款全端的閉環平臺,透過雲端託管的AIOps服務和虛擬網路助理Marvis,能處理使用者的有線和無線設備、WAN、安全和資料中心網域等管理問題,再加上該平臺提供的AI原生網路數位體驗分身Marvis Minis,能透過AI主動發現和自動修復問題。Juniper Networks表示,與傳統解決方案相比,AI原生網路平臺的營運支出可降低達85%的成本、消除90%的網路故障單,網路事件解決時間還縮短了50%。(詳全文)
Google 評估 ASPIRE
AI可自我評估輸出對錯!Google釋出新框架
Google最近揭露一款專為大型語言模型設計的ASPIRE框架,可用來強化語言模型選擇性預測(Selective Prediction)的能力,且在各種問答資料集上,表現都優於目前最先進的選擇性預測方法。ASPIRE框架的重要性,在於能增加LLM的可信度。
該框架分為3階段運作,包括特定任務調整、答案採樣和自我評估學習。特定任務調整階段是對已受基礎訓練的LLM進行進階訓練,就好比訓練學生,使其更好地解決特定問題一樣。第二階段則是指,ASPIRE使用學習到的可調參數,對每個訓練問題生成不同的答案,並建立自我評估學習的資料集,生成高可能性輸出序列。在自我評估學習階段,ASPIRE會新添加一組可調節參數,來提高模型自我評估的能力,也就是讓模型學會自己判斷答案的準確性。
後來,團隊用CoQA、TriviaQA和SQuAD等3個問答資料集,以及各種開放預訓練的Transformer模型來評估ASPIRE。經ASPIRE調整的小型OPT-2.7B模型,表現超過更大的OPT-30B模型。這項實驗結果表示,只要經過適當調整,即便是較小的語言模型,在部分情境下也能超越較大的語言模型。(詳全文)

AI資源中心 負責任AI 隱私安全
美國設立AI資源中心
美國國家科學基金會(NSF)日前發表國家AI研究資源測試(NAIRR),要實現共享研究基礎設施的願景,第一步是要強化、普及化負責任AI和創新的重大資源,預計為期2年。
NAIRR與10個美國聯邦機構,25家企業、非營利和慈善組織合作,如國家科學基金會、美國太空總署、美國國家標準與技術研究院,以及AI2、AWS、AMD、Google、Hugging Face、IBM、微軟、Nvidia等,要讓美國的研究人員和教育者能存取先進的運算、資料集、模型、軟體、訓練等支援。
NAIRR分為4個主要領域,首先是可用來存取、分配各種AI資源,並實現開放式AI研究的NAIRR Open,再來是NAIRR Secure,專門支援那些需要隱私和安全的AI研究。第三個是NAIRR Software,負責AI軟體、平臺、工具和服務的研究,最後一個是NAIRR Classroom,目的是要擴大全美的AI研究,包括藉由教育、訓練、使用者支援及外展服務來接觸更多社群。(詳全文)
Google Cloud Hugging Face Vertex AI
Google Cloud與Hugging Face宣布策略聯盟
被稱為AI界GitHub的Hugging Face最近與Google Cloud策略聯盟,讓Google Cloud成為Hugging Face的AI訓練和推論的首選服務,雙方也計畫整合彼此服務。
Hugging Face的願景是讓所有企業使用開源模型和技術,來打造自己的AI,目前已在平臺上提供將近50萬種共享模型和10萬個資料集。Hugging Face表示,此次將與Google在開放科學、開源、雲和硬體領域進行合作,比如開發者可用Google AI平臺Vertex AI來訓練、微調和部署Hugging Face的模型,並於Google Kubernetes Engine(GKE)上使用Hugging Face專用的深度學習容器。此外,這次合作和允許更多開源開發者存取Cloud TPU v5e,並支援基於Nvidia H100 Tensor Core GPU的A3 VM,也能利用Google Cloud市集替Hugging Face托管平臺進行簡單的管理與計費,包括Inference、Endpoints、Spaces與AutoTrain等。(詳全文)
文字審核 OpenAI Embedding
OpenAI推出2大新嵌入式模型
OpenAI最近再度更新旗下產品,包括GPT-4 Turbo預覽模型和文字審核模型,同時還推出了2個新的文字嵌入式模型text-embedding-3-small與text-embedding-3-large。進一步來說,GPT-4 Turbo預覽版可更徹底完成程式碼生成任務,也減少模型有時會落下任務的懶惰狀況,還修復了非英語UTF-8生成的錯誤。審核API則是一款免費工具,能用來幫助使用者辨識有害文字,不管是text-moderation-latest或text-moderation-stable都會採用最新的text-moderation-007版本。
至於新模型,則有text-embedding-3-small和text-embedding-3-large,前者的多語言檢索(MIRACL)評測比前一代模型的31.4%提高至44%,常用的英文任務評測(MTEB)則從61%增加至62.3%。而且text-embedding-3-small價格更便宜,其每1,000個標記的費用只要0.00002美元。而text-embedding-3-large最多可建立3,072個維度的嵌入向量,相較於text-embedding-3-small與text-embedding-ada-002,其MIRACL的平均分數為54.9%,每1,000個標記的費用為0.00013美元。OpenAI說明,這2個嵌入式模型能讓開發者在嵌入時,權衡效能與成本,依照實際需求並藉由維度API參數來控制嵌入大小,在不損及重要概念的前提下,減少嵌入成本。(詳全文)
微軟 Visual Studio Copilot 命令
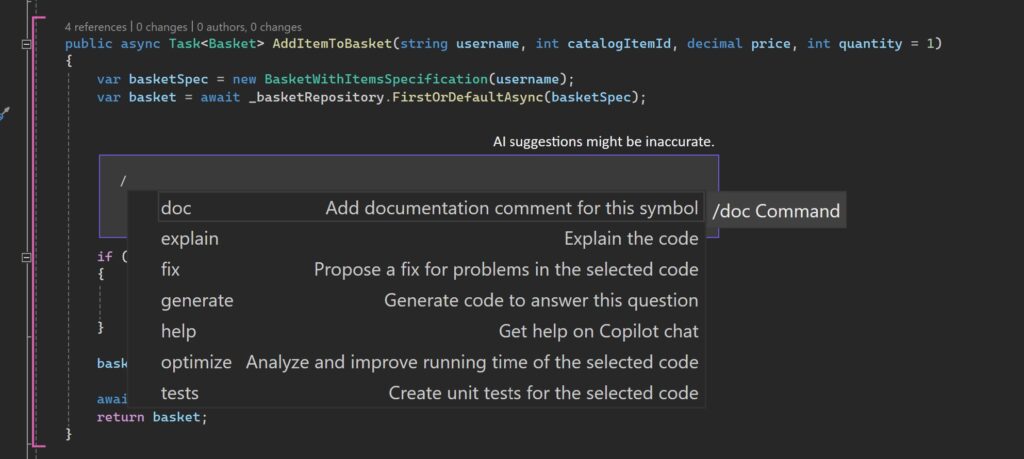
GitHub Copilot加入2大新功能
微軟更新Visual Studio Copilot聊天擴充套件,添加兩項新功能,第一項是可以指示Copilot執行特定工作的斜線命令(Slash Commands),另一項是上下文變數(Context Variables),開發者可使用符號#,在與Copilot對話中引用特定檔案。
進一步來說,斜線命令是一個特殊命令,開發者在與Copilot聊天時,可用斜線命令要求Copilot對程式碼執行特定操作,像是「/doc」新增文件註解、「/explain」則要求Copilot解釋程式碼、「/fix」是要Copilot對所選取的程式碼提出修復建議等。而上下文變數功能,可讓開發者使用符號#,將解決方案中的檔案加入到與Copilot的對話中。當開發者直接引用檔案時,Copilot可存取該檔案內容,並針對該檔案提供更具體的回答,比如開發者可以詢問「#Main.c檔案的運作方式為何?」或「#Calculator.cs檔案的目的是什麼?」Copilot就會根據該檔案提供答案。(詳全文)
Google 影片生成 時空擴散
可生成5秒高品質影片,Google揭露時空擴散模型Lumiere
Google最近發表一款影片生成模型Lumiere,是一種文字轉影片的擴散模型,可用來產生真實、多樣且動作連貫的影片。該模型使用時空U-Net(STUNet)架構,可一次生成完整的影片長度,不需經過多次處理。
因為,該架構可在空間和時間上同時對訊號降採樣(Downsample),在更緊湊的時空表示中執行大部分運算。也因此,Lumiere能生成更長時間、動作更連貫的影片,可產生長達5秒的影片。Google表示,5秒影片的長度,已經超過大多數媒體作品中平均鏡頭的時長了。
就運作流程來說,Lumiere會先由基礎模型在像素空間生成圖像草稿,再透過一系列空間超解析度(SSR)模型,來提高這些圖像的解析度和細節。同時,團隊還採用Multidiffusion方法,來解決SSR時窗不連續的問題,確保影片的一致性和連續性。(詳全文)
圖片來源/Google、微軟
AI近期新聞
2. Meta釋出700億參數的程式碼生成模型Code Llama
3. 美政府要求AI公司提交安全測試報告,雲端業者需通報外國AI客戶
資料來源:iThome整理,2024年2月
熱門新聞

2026-02-11

2026-02-09

2026-02-10
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-06

2026-02-10

2026-02-10

2026-02-10