
Anthropic
新興的AI業者Anthropic周一(3/4)發表了全新的Claude 3系列模型,涵蓋功能最低階的Claude 3 Haiku、中階的Claude 3 Sonnet,以及最強大的Claude 3 Opus,它們的預設值皆支援20萬個Token的脈絡,並宣稱其中的Claude 3 Opus在許多基準測試上超越了OpenAI GPT-4與Google Gemini 1.0 Ultra。

Anthropic在2021年由曾擔任OpenAI研究副總裁的Dario Amodei,以及其妹妹、同樣身為OpenAI資深員工的Daniela Amodei共同創立,是OpenAI最大的競爭對手之一,而OpenAI與微軟在資金及服務上的緊密關係,使得Anthropic成為其它科技巨頭競逐的對象,包括Google在2022年注資3億美元取得10%的Anthropic股份,去年底承諾加碼投資20億美元,至於Amazon也在去年宣布將挹注40億美元至Anthropic,並換得讓AWS成為Anthropic主要雲端服務供應商的交易。
Anthropic本周所發表的Claude 3模型強化了各方面的能力,涵蓋分析、預測、細緻的內容建立、程式碼生成,以及在西班牙文、日文與法文等非英文語言的對話能力;它也擁有更複雜的視覺功能,得以處理各種不同的視覺格式,包括照片、圖表、圖像與技術圖等;還可帶來近乎即時的結果,可支援即時客戶聊天、自動完成與資料汲取任務。
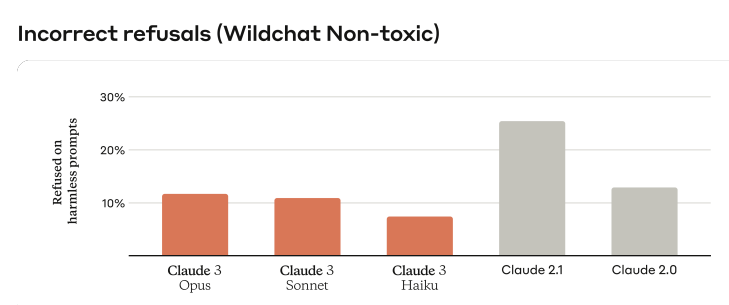
另一方面,過去的Claude模型經常作出不必要的拒絕,顯示它缺乏對語意的理解,最新的Claude 3則對提示表現出更細緻的理解能力,可辨識真正的傷害,明顯降低了拒絕回答無害提示的頻率。
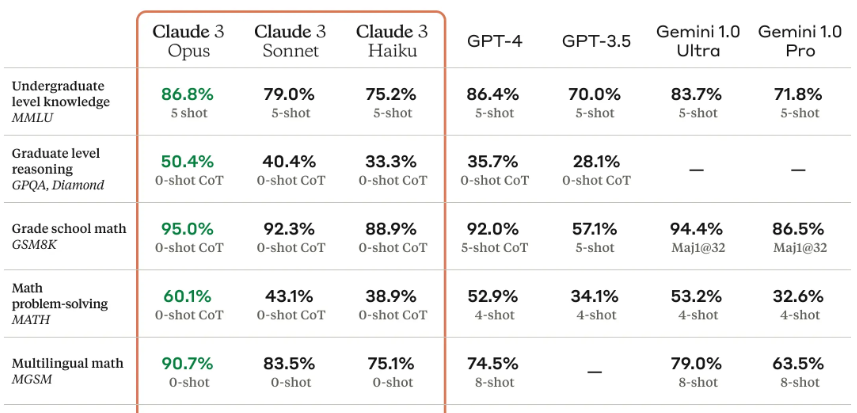
Claude 3最受矚目的是其中的Claude 3 Opus模型在許多基準測試上,超越了OpenAI GPT-4與Google Gemini 1.0 Ultra。例如在MMLU本科水平專家知識上達到86.8%,擊敗GPT-4的86.4%與Gemini 1.0 Ultra的83.7%,研究生專家推論(GPQA)以50.4%超越OpenAI GPT-4的35.7%。其它凌駕這兩大模型的基礎測試還有基礎數學(GSM8K)、程式碼生成能力HumanEval與文字推論等。
儘管Claude 3模型初期僅支援20萬個Token的脈絡,但3種型號都可接受超過100萬個Token的輸入,Anthropic將根據需求提供給需要強化處理能力的客戶。為了有效地處理冗長的上下文,這些模型需要強大的回憶能力,在評估模型記憶的「大海撈針」(Needle In A Haystack,NIAH)基準測試中,Claude 3 Opus不僅達到超過99%的準確率,在某些情況下,甚至能夠辨識出此針是否是人為插入的。
Anthropic亦標榜Claude 3模型的偏差少於先前的模型,也更擅長遵循複雜的多步驟指令,或是生成諸如JSON等格式的結構化輸出,以更輕鬆地將Claude 3模型應用在自然語言分類或情緒分析上。
Claude 3 Haiku、Claude 3 Sonnet與Claude 3 Opus各自可支援不同的應用,Claude 3 Haiku是最袖珍及最快速的模型,專為模仿人類互動的即時回應與無縫AI體驗而設計,每100萬個Token的輸入費用為0.25美元,輸出為1.25美元;Claude 3 Sonnet屬於相對均衡的模型,在智慧與速度中取得平衡,適用於企業負載及大規模的AI部署,每100萬個Token的輸入/輸出費用分別是3美元及15美元;最強大的Claude 3 Opus可處理高度複雜的任務,可帶來人類等級的理解能力,每100萬個Token的輸入/輸出費用分別是15美元與75美元。
Anthropic的API現已支援Claude 3 Sonnet與Claude 3 Opus,使用者亦可透過claude.ai、Amazon Bedrock與Google Cloud的Vertex AI Model Garden使用Claude 3 Sonnet,Claude 3 Opus目前則僅開放Claude Pro訂閱用戶使用。至於Claude 3 Haiku也會在近期上市。
圖片來源_Anthropic
熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09

2026-02-13


2026-02-10