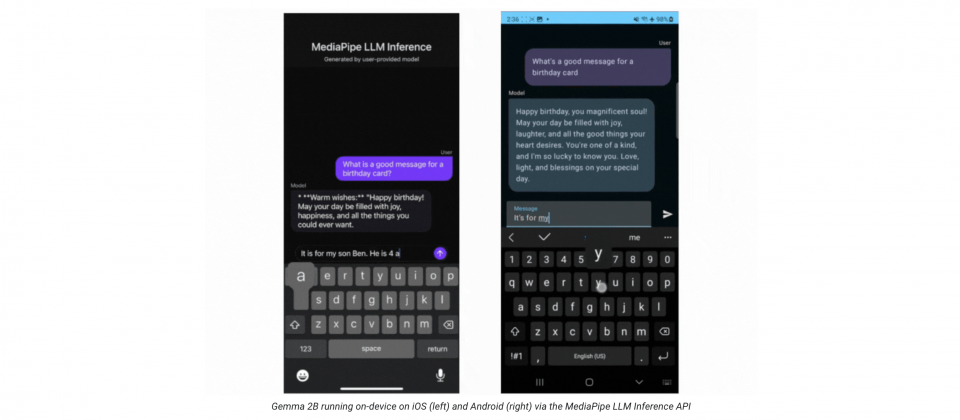
Google發布MediaPipe LLM Inference API,讓開發者可以完全在裝置上執行大型語言模型,支援文字生成、自然語言資訊檢索,以及總結文件等任務。該API支援包括Falcon 1B、Gemma 2B、Phi-2與StableLM-3B等模型,目前僅接受文字輸入與輸出。
這項新功能的重要性在於讓大型語言模型能夠在裝置上運作,而且達到跨平臺相容。Google提到,因為大型語言模型的記憶體和運算需求是傳統裝置上模型的100多倍,因此這可說是一項變革性的新功能。而之所以大型語言模型可以開始在裝置上運作,牽涉到新的操作、量化、快取和權重共享等技術堆疊的進展。
開發者現在可以使用網頁、Android或iOS SDK,經過幾個步驟,就能夠在應用程式中使用實驗性MediaPipe LLM Inference API。首先選擇支援的模型架構與權重,接著使用MediaPipe Python套件將模型權重轉換成TensorFlow Lite Flatbuffer格式,並在應用程式中匯入LLM Inference SDK,將TensorFlow Lite Flatbuffer與應用程式一起託管,開發者就可以開始編寫程式,透過LLM Inference API傳入文字提示詞,並獲得模型的回應。
目前LLM Inference API只能使用較為輕量的大型語言模型,在初始版本中,Google支援Falcon 1B、 Gemma 2B、Phi 2與Stable LM 3B四種模型架構,而這些模型架構相容的模型權重選擇,無論是基本模型權重、社群微調版本或是開發者自己微調的權重都可以使用。
為了讓大型語言模型可以在行動裝置上運作,Google對MediaPipe、TensorFlow Lite、XNNPack進行大量的最佳化,官方提到,這些最佳化功能主要落在CPU與GPU上。而在特定的高階手機中,Android AICore還可運用專門的硬體神經網路加速器,來加速大型語言模型的運算。
Google主要使用預填速度(Prefill Speed)和解碼速度(Decode Speed),來衡量裝置上大型語言模型的運作效能。預填速度(圖一)是指大型語言模型處理提示詞的速度,而解碼速度(圖二)則是大型語言模型產生回應的速度。
.png)
(圖一)
.png)
(圖二)
四種模型在WebGPU和Android GPU上都能順暢運作,不過Google提到,受iPhone記憶體的限制,目前只有Gemma 2B(int4)能夠在iOS運作。在GPU上,Falcon 1B和Phi 2使用浮點數fp32,而Gemma和StableLM 3B則可以使用浮點數fp16就好,官方表示,Gemma和StableLM 3B即便使用較低精度的浮點數,仍可以保持一定的效能和強健性。
Google提到,他們仍會繼續這項研究,並擴展支援更多平臺和模型,提供廣泛的轉換工具、裝置上元件。現在開發者已經可以在GitHub上查看官方範例,以便深入理解API的使用方式。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-12


2026-02-10

2026-02-06