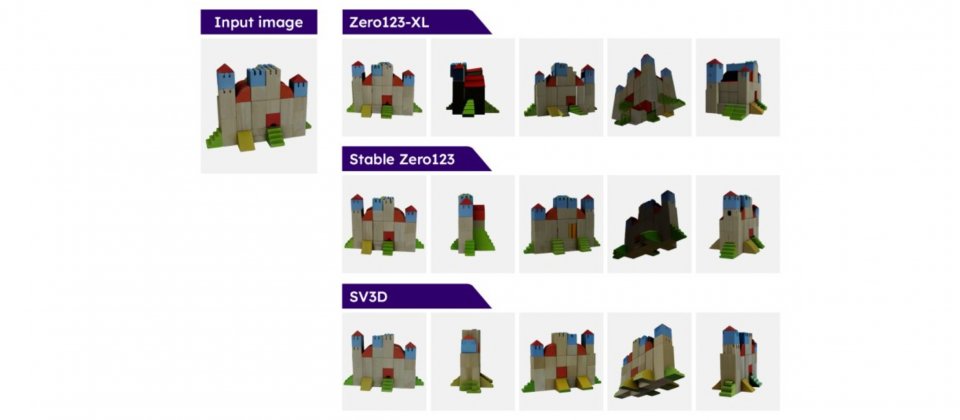
Stability AI以Stable Video Diffusion模型為基礎,創建了Stable Video 3D(SV3D)模型,SV3D可生成高品質的3D多視角影片,官方提到,相較之前所發布的Stable Zero123模型,SV3D生成的影片品質以及多視角表現都更好,效能也優於Zero123-XL。
Stable Video 3D模型有兩個變體,分別是SV3D_u和SV3D_p。SV3D_u能夠利用單一圖像,不需要使用者設定攝影機參數,即可生成環繞物體的連續視角(Orbital Views)影片,而SV3D_p則是在SV3D_u基礎上,不僅支援從單一圖像生成影片,還能根據環繞物體的影片,生成指定攝影機路徑的3D影片。
Stability AI調整原有的Stable Video Diffusion圖像轉影片模型,增加攝影機路徑設定功能,使Stable Video 3D模型能夠生成從不同角度觀看物體的影片。與Stable Zero123所使用的擴散模型相比,Stable Video 3D在生成影片方面擁有更好的泛化能力以及視角一致性,因此所生成的影片,從不同視角看起來更加自然且連貫。
Stable Video 3D還採用了解耦光照最佳化(Disentangled Illumination Optimization)技術,使得模型可單獨調整照明效果,不影響場景其他元素表現,以及透過遮罩分數蒸餾採樣損失函式(Masked Score Distillation Sampling Loss),來維持生成物體的品質和一致性。
官方指出,Stable Video 3D在3D影片生成有重大進步,因為先前的方法在視角通常受限制,且輸出有物體不一致的問題。而Stable Video 3D卻可從任意指定視角,輸出連貫的視圖,不僅強化姿勢可控性,也確保可在多個視圖中保持物體外觀一致。
Stable Video 3D現在推出,Stability AI會員可將其用於商業目的,針對非商業用途,開發者可以在Hugging Face下載模型權重,並參照Stability AI的研究論文。
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10