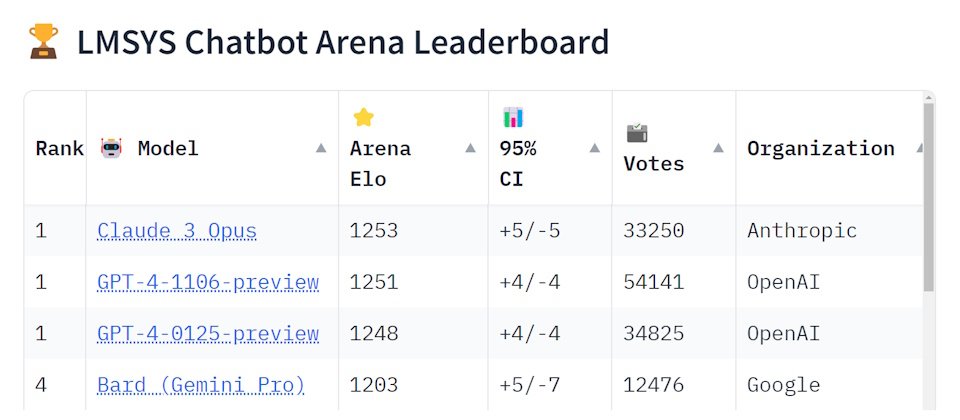
就在這幾天,專門盲測大型語言模型(LLM)能力的LMSYS Chatbot Arena排行榜出現了變化,由Anthropic所打造的Claude 3 Opus模型擠下了OpenAI的GPT-4,成為該排行榜上等級最高的LLM。
LMSYS Chatbot Arena是由研究組織Large Model Systems Organization在去年5月所發表,為一採用Elo評分系統的平臺,Elo評分系統可用來計算參與者的相對技能,最初是為了改善西洋棋的評分系統而設計,之後則被應用在足球、棒球、籃球、桌球、各種棋盤遊戲,以及最近的大型語言模型;而LMSYS Chatbot Arena則是個開放且眾包的盲測排行榜,支援75種大型語言模型,使用者可於網頁上輸入各種提示,以查看兩個隨機選擇的模型所提供的答案,系統並未揭露生成答案的模型,並由使用者評斷答案的優劣,亦可選擇平手或兩個答案都不好。
自LMSYS Chatbot Arena排行榜於去年5月上線以來,評分最高的大型語言模型一直是GPT,但Claude 3 Opus在本周擠下了GPT--4-1106-preview(去年11月釋出的GPT-4 Turbo)與GPT-4-0125-preview(今年1月釋出的GPT-4 Turbo)。
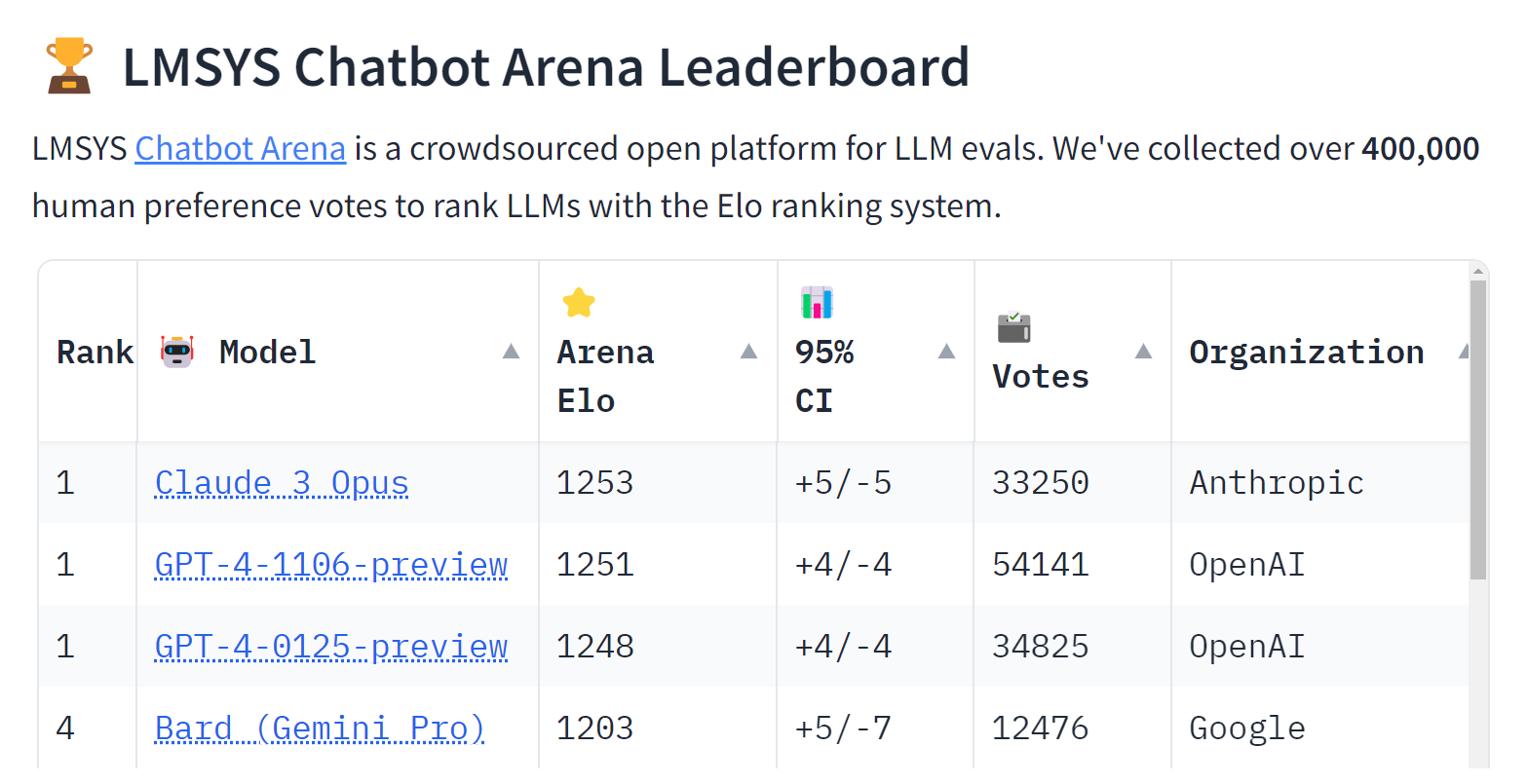
Anthropic是在今年3月發表Claude 3系列的模型家族,涵蓋最低階的Claude 3 Haiku、中階的Claude 3 Sonnet,以及最強大的Claude 3 Opus,除了Claude 3 Opus位居LMSYS Chatbot Arena排行榜冠軍之外,中階的Sonnet與低階的Haiku也都在前十名的榜單上。
由曾擔任OpenAI研究副總裁的Dario Amodei,以及其妹妹、同樣身為OpenAI資深員工的Daniela Amodei在2021年共同創立的Anthropic,被視為是OpenAI目前最強勁的對手,鎖定資料科學、機器學習與AI的內容網站KDnuggets認為,Anthropic所發表的Claude 3在所有LLM基準測試中都優於GPT-4和Gemini Ultra,已是AI領域新的領導者。
在Reddit平臺有關GPT-4 Turbo與Claude 3 Opus的討論中,多數人贊成Claude 3 Opus的寫作與處理文章的能力勝過GPT-4 Turbo,有人說GPT-4 Turbo對複雜問題的處理能力優於Claude 3 Opus,亦有人覺得Claude 3 Opus所生成的程式碼品質與GPT-4 Turbo相當,但更人性化。
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10