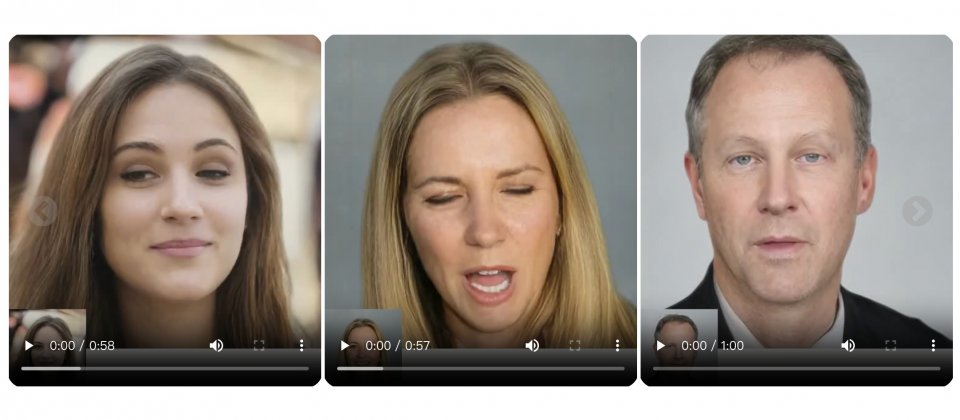
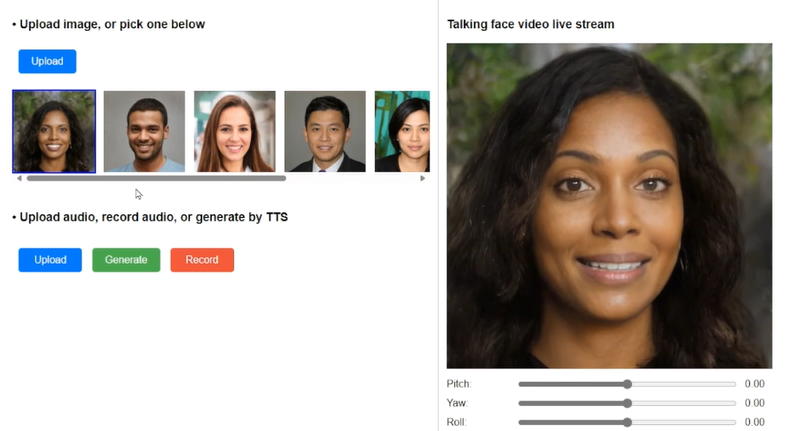
微軟公開其最新虛擬人像技術VASA-1框架,該框架只要使用一張肖像照以及一段語音音訊,就能夠產生精確逼真的人臉對嘴說話影像,影像中人物甚至可展現自然的表情和頭部動作。VASA-1框架可即時生成高達40 FPS的512×512影像,適合虛擬形象的即時互動用例。
圖片來源/微軟
以人工智慧生成能夠說話的臉孔,可使人工智慧技術更具互動性,豐富數位通訊體驗,也能強化溝通的無障礙性,在教育、醫療和社交都有許多用處。但過去的技術,距離產生真實且自然的說話臉孔還有一大段距離,不少研究聚焦在對嘴上,臉部動態行為通常被忽視,因此生成的臉部也會顯得僵硬且缺乏說服力。
除了表情之外,頭部運動在增強虛擬人像的真實感,也發揮極大的作用,但與模擬臉部表情所遭遇的問題相同,目前生成的動畫和人體運動模式之間存在相當大的差距。另外,生成效率也是該項技術的一大重點,唯有足夠低延遲,臉部生成技術才能良好地支援即時通訊等應用。
微軟VASA-1框架克服了以往虛擬人像生成技術的限制。此框架的特別之處在於,研究人員利用擴散Transformer模型,在整體臉部動態和頭部運動潛在空間進行訓練,該模型將所有可能的臉部動態,包括嘴唇動作、表情、眼睛注視和眨眼等行為,視為單一潛在變數,並統一建模其機率分布。
研究人員針對整體臉部動態建模,在加上聯合學習的頭部運動模式,最終產生各種逼真且情感豐富的說話行為。同時,微軟利用3D技術輔助表示臉部特徵,並特別設計損失函式,使得VASA-1不只能夠生成高品質臉部影像,且能有效地捕捉和重現臉部3D結構。
VASA-1不只圖像生成品質自然良好,另一大優點更是能高效運作,即時生成逼真的說話臉部,而這對於通訊的即時互動更是關鍵性的能力。研究人員在Nvidia RTX 4090 GPU桌上型電腦進行評估VASA-1,線上串流模式512×512解析度可達40 FPS,延遲時間僅有170 ms。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06