
Hugging Face
在Build 2024開發者大會上,微軟公布Phi-3-vision模型,輕巧到可執行在行動裝置上,又具備視覺能力,可理解文字和圖片。
Phi-3-vision為4月公布的Phi-3模型家族最新成員,參數量為42億,大於Phi-3-mini(3.8B),但小於Phi-3-small(7B)。Phi-3-vision是Phi-3家族第一個多模態模型,其文字理解能力是以Phi-3-mini為基礎,也具備Phi-3-mini的輕量特色,可執行在行動裝置上。但它最大特色是整合了圖片識別能力,能理解真實世界的圖片,也能理解並擷取出圖片中的文字。
微軟說,Phi-3-vision特別為了圖表與方塊圖理解優化,可用於產出洞見與回答問題。例如用戶輸入不同世代員工使用的職場工具的圖表圖片後,要求它以產出協助決策的洞見,Phi-3-vision可以說明它看到了Z世代、千禧世代、X世代及嬰兒潮世代員工使用AI工具的比例,並能分點描述各年齡群組的數據、推論群組的行為,還能做出結論、提供企業相應建議(例如制定促進各群組使用的策略)。

圖片來源/微軟
Phi-3-vision現在已以預覽版公開於Hugging Face平臺上。
最新公布的Phi-3-vision為指令調校過的Phi-3-128K-Instruct模型,包括Phi-3-mini語言模型、圖片編碼器、連接器(connector)與投影器(projector)。其脈絡長度為128k token,訓練期間為2024年2月到4月。
資料集方面,Phi-3-vision是以500B token的多種類型圖片及文字資料來訓練,包括嚴選公開內容、高品質教育資料與程式碼、高品質的圖文整合資料、新的「教科書等級」合成資料(主要是數學、程式、常識理解、真實世界知識如科學、日常活動、心靈理論)與圖表圖片,以及高品質的監督式聊天格式資料,後者涵括多種人類偏好如遵從指令、真實、誠實、助益等主題。為了確保隱私,資料蒐集過程中已篩選掉包含個資的資料。
微軟也提供了Phi-3-vision相較於字節跳動Llama3-Llava-Next(8B)及(微軟研究院和威斯康辛大學、哥倫比亞大學合作的)LlaVA-1.6(7B)、阿里巴巴通義千問QWEN-VL-Chat模型在效能比較,顯示最新模型在多個項目上表現優異。
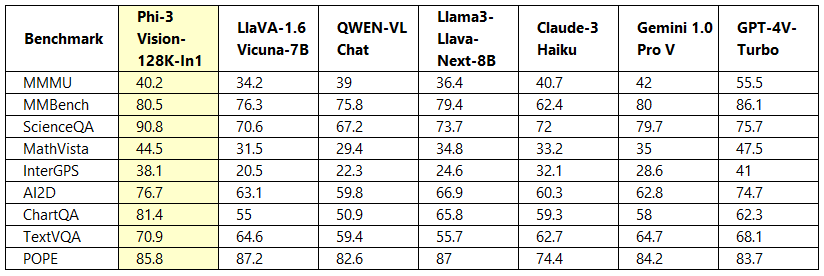
資料來源/微軟
最新宣布也讓微軟和蘋果在本地端AI競賽再加劇。在微軟公布了Phi-3系列後,蘋果也公布了OpenELM模型,最小模型只有2.7億個參數。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06