圖片來源:
OpenAI
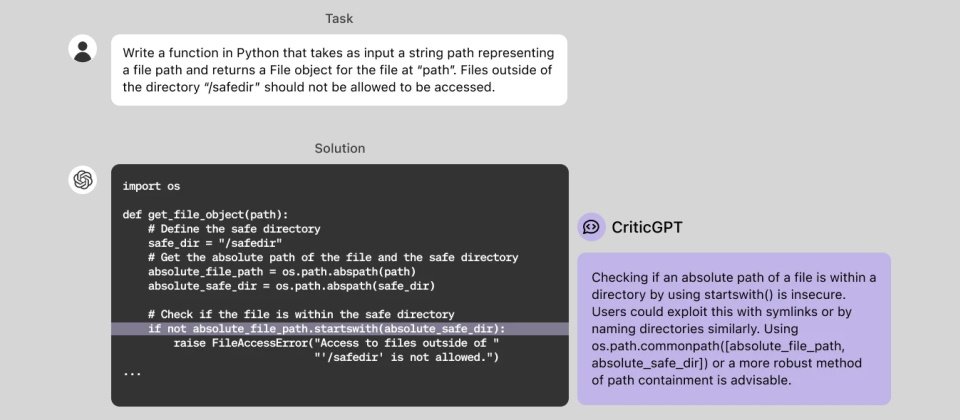
OpenAI周四(6/27)揭露一個奠基於GPT-4的新模型CriticGPT,它目前扮演人類訓練師的AI助手角色,可用來審查ChatGPT所生成的程式碼,並找出錯誤。
現階段的ChatGPT也是基於GPT-4模型,它藉由人類反饋的強化學習(Reinforcement Learning from Human Feedback,RLHF)來調整其輸出表現,亦即由人類訓練師根據模型的行動來提供反饋或意見,而CriticGPT也能用來審核ChatGPT輸出程式碼時的表現,OpenAI正在將CriticGPT整合到RLHF的標籤管道中,以替人類訓練師提供明確的AI說明。
OpenAI指出,隨著模型行為與推論的進步,ChatGPT變得更加精確,錯誤也變得更為微妙,令人類的AI訓練師更難找出其錯誤之處,並對RLHF方法造成了挑戰,使得模型的調整愈來愈困難,這使得他們訓練CriticGPT來進行評論,以突顯ChatGPT輸出的錯誤。
根據OpenAI的測試,人類訓練師在取得CriticGPT的協助之後,審核ChatGPT生成程式碼的表現在大多數時候(60%),優於沒有CriticGPT幫忙的時候。
總之,OpenAI發現,在CriticGPT的協助下,人類訓練師不僅得以發現更多的問題,而且還能藉由CriticGPT強化人類的技能,提出更全面的批評,還能減少幻覺錯誤。
只是CriticGPT現階段仍有其侷限性,例如所支援的答案很短,也還會產生幻覺,尚未能解決分散的錯誤,也還無法處理過於複雜的任務或回應。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-12


2026-02-10

2026-02-06
Advertisement