Adobe
繼於去年3月發表Firefly圖像生成AI模型之後,Adobe將在年底前開始測試Firefly影像生成AI模型,允許使用者輸入文字敘述或靜態的參考圖像,並將它們轉成影像。
Adobe指出,市場對於短影音的需求不斷成長,意味著編輯、電影製作人或內容創作者必須在更短的時間內做更多的事情,常見的編輯任務包括處理影片中的間隙、從場景中刪除不必要的物件、平滑切換,或是尋找完美的B捲等,雖然Adobe已提供Frame.io影片製作/後製平臺,但生成式AI則可讓編輯人員及動畫設計師更輕鬆且更快地創作。
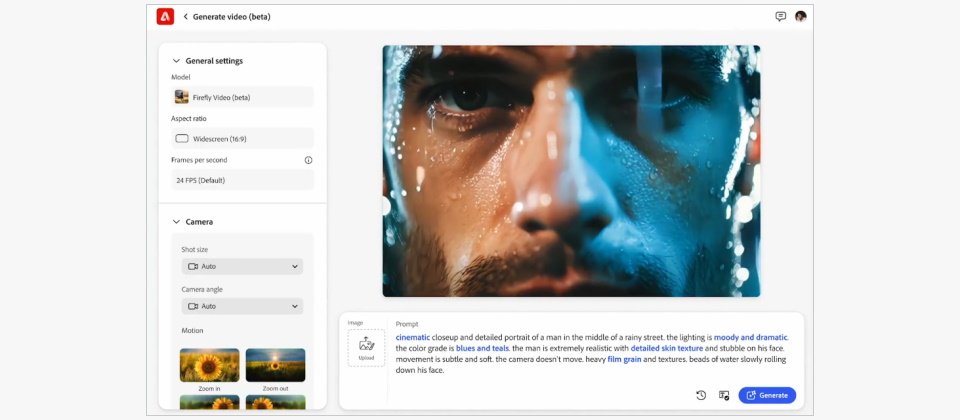
Firefly影像模型將支援文字生成影像,使用者可透過文字描述、各種攝影機控制,以及參考圖像來生成能夠完美填補空缺的B捲,而且在兩分鐘內就能完成。
該模型可用來生成自然世界的影片,不管是風景、植物或動物等;或是藉由影像中的圖片來生成可填補空缺的B捲;還是利用攝影機的角度、運動及縮放等控制功能來建立完美視角;它還能生成各種效果,再將它們整合至既有的影像上。
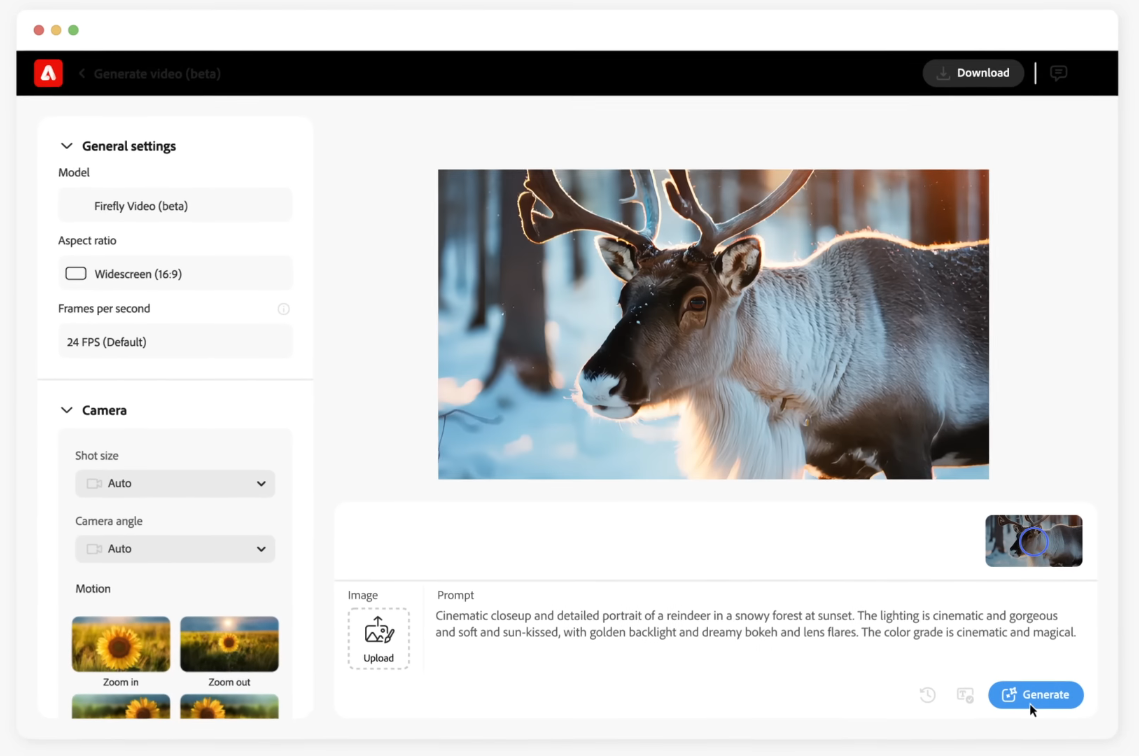
圖片來源/Adobe
身為全球知名的創意解決方案供應商,Adobe重視旗下產品在商業應用上的安全性,強調所有模型只針對該公司有權使用的內容進行訓練,並不會以用戶內容進行訓練。
此外,儘管Adobe已提供了各種影像工具,但AI依然讓創作者趨之若鶩,去年發表的Adobe Firefly圖像生成AI模型已支援Photoshop中的生成式填充,Lightroom的生成式刪除,Illustrator的生成式形狀填充,以及Express的文字生成範本,這一年多來Adobe社群透過該模型所生成的圖像及向量圖形已超過120億張。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-06

2026-02-09