法國新創公司Mistral AI宣布推出最新的人工智慧模型Mistral Small 3.1,根據官方公布的基準測試資料,Mistral Small 3.1的整體效能表現,尤其在視覺理解及長上下文處理方面,明顯優於Google日前釋出的Gemma 3同級模型。
Mistral Small 3.1主打適合本地端部署,與Gemma 3 27B皆屬於中型規模百億級參數的多模態人工智慧模型,具備輕量化的特性,能夠在一臺搭載單張Nvidia RTX4090顯示卡的裝置,或是32 GB記憶體的Mac電腦上運行,但Mistral Small 3.1各項技術效能指標,則已經領先Gemma 3。
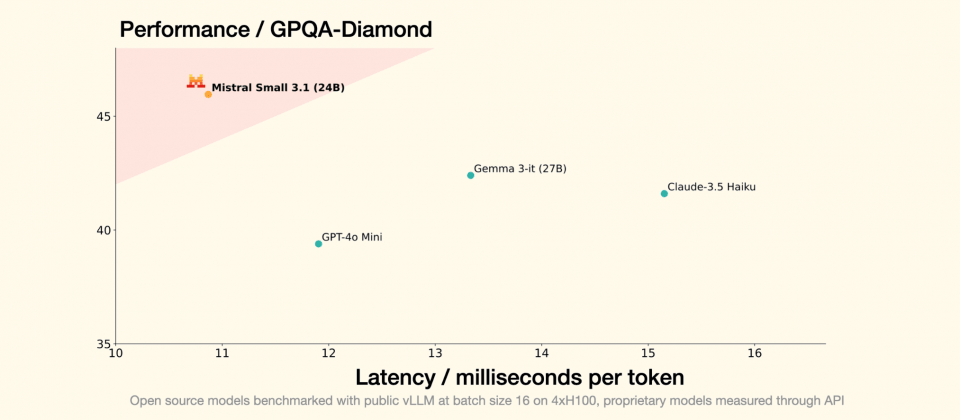
從Mistral AI公開的詳細基準測試資料來看,Mistral Small 3.1在進階的文字理解與推理任務,例如GPQA Diamond上達到45.96%,領先Gemma 3的42.40%。此外,程式撰寫能力測試人類評估HumanEval中,Mistral Small 3.1表現達88.41%,同樣略勝Gemma 3的87.80%。
視覺處理的效能差距則更為明顯,根據ChartQA圖表理解基準,Mistral Small 3.1取得86.24%的準確率,明顯優於Gemma 3的78.00%。同時在文件圖像理解測試DocVQA,Mistral Small 3.1也以94.08%的高準確率,領先Gemma 3的86.60%,這對於需要高度視覺理解能力的應用,例如自動文件分析、品質檢測等相對重要。
然而,在數學推理方面則是Gemma 3表現亮眼,在MATH測試中,其準確率達89.00%,顯著領先Mistral Small 3.1的69.30%。
另一個值得關注的是長上下文理解能力,Mistral Small 3.1可處理的上下文範圍為12.8萬Token,這使模型更適合處理大型文件或長對話場景。在專門用於評估長上下文處理能力的RULER 128K測試中,Mistral Small 3.1達到了81.20%的效能,而Gemma 3僅有66.00%。
在實際部署與硬體相容性方面,Mistral Small 3.1 24B與Gemma 3 27B針對單卡GPU裝置最佳化,因此企業或研究團隊不需要使用昂貴的叢集設備,即可實現高效推理運算,這點對於個人開發者、中小企業或需處理敏感資料且不願將資料傳輸至雲端的組織尤其重要。
熱門新聞

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13

