執行,來避免在不同區域間切換所造成的延遲。(圖片來源/第一資本)")
第一資本提出一種新的微服務單元架構,將一套流程中的所有微服務隔離成一個單元,並且限定在同一個可用區域(AZ)執行,來避免在不同區域間切換所造成的延遲。(圖片來源/第一資本)
第一資本(Capital One)是美國第三大發卡銀行。1994年成立的他們,期許自己成為一家科技公司,在2012年啟動數位轉型,隔年擁抱敏捷開發、2014年推動IT現代化、2015年投身開源社群、2016年開始上雲,直到2020年關閉最後一個本地資料中心,成為美國金融業全面上雲的先行者。
上雲後的他們,如何確保系統韌性?如何保證每天70億筆的刷卡交易,都能在毫秒內完成詐欺偵測、確認餘額並成功處理?
用公雲可用區域強化可用性
第一資本信用卡架構副總Kathleen deValk在2023年一場會議中,揭露自家的網站可靠性工程(SRE)做法。首先,在人力安排上,第一資本沒有設立一個專門的SRE團隊來維護系統韌性,而是將SRE人力分散在各業務部門一起工作,比如信用卡部,根據事件經驗,改善韌性架構。
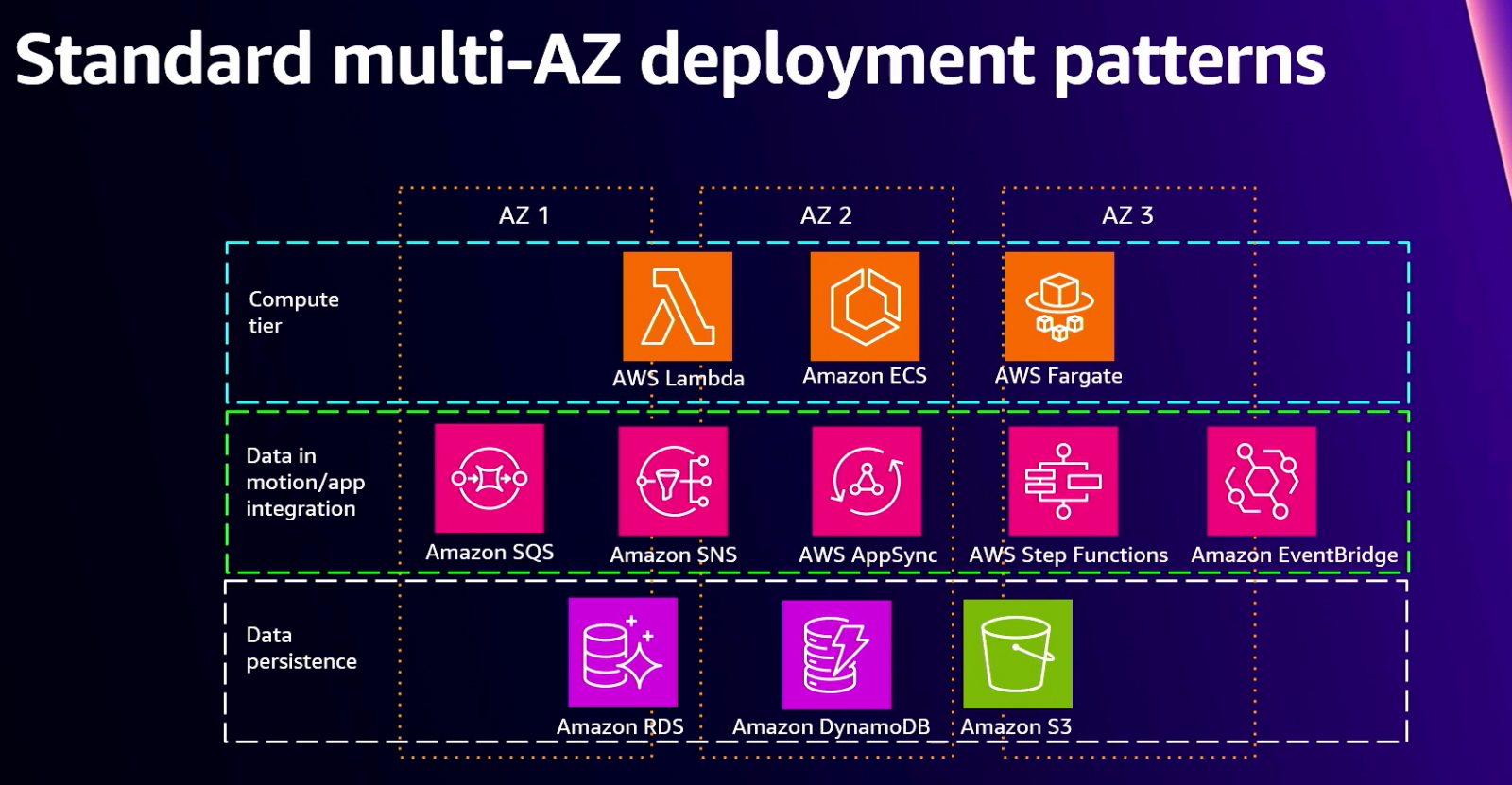
第一資本上雲採取了不同的技術架構,最基礎的是公雲業者AWS標準多可用區域(AZ)架構。這個AZ是指實體地理區域中,相互隔離但以低延遲網路連接的資料中心。由於互相隔離,就算單一AZ故障,也不會影響其他AZ,所以企業常在多個AZ中部署應用程式,來提高可用性,或因應突然爆增的流量。這也是第一資本採用的原因。
他們的多區域基礎架構中,還分為運算層、資料溝通層和永久資料層等3層,每層有各自的服務(如下圖)。比如運算層有Lambda、ECS、Fargate等AWS服務,來執行函數和容器。資料溝通層有Amazon SQS、AWS AppSync等服務,來調度資料處理工作。永久資料層有RDS、DynamoDB、S3等AWS資料庫和儲存服務,來處理資料湖、機器學習(ML)和分析等任務。為確保服務不中斷,第一資本將這3層服務,部署在3個AZ,每個AZ都能執行這3層服務,以便一個故障時,其他AZ可以接手支援。
韌性作法1:多區域故障轉移架構
有了這個基礎,第一資本進一步設置更細緻的韌性機制,其一是多區域故障轉移架構。當負載平衡器偵測到系統故障,能自動將流量轉移到另一個AZ,甚至自動觸發後續功能,例如修復系統、回收執行個體、重新連接資料庫等等。
自建監控儀表板是這項韌性機制的關鍵,可根據每支應用程式客製的健康指標,來檢測系統健康狀況。這些健康指標,有其相對應的閾值。在系統設計階段,第一資本會透過負載測試、效能測試、擴展測試和邊界測試,來找出可參考的閾值設計。
「但不能止步於此!」Kathleen deValk強調,講求韌性的網站可靠性工程是一個持續學習的過程,所以,第一資本得隨著時間演進不斷優化、微調閾值,才能更快偵測到問題、自動修復。
韌性作法2:AA多區域架構
另一個作法是採用AA多區域架構。有別於多區域故障轉移架構的AP架構、故障切換可能需要幾秒到幾分鐘,AA架構可以近乎即時切換,也更容易水平擴展。也因此,第一資本最常在講求時效的業務場景中,採用AA多區域架構的作法,比如信用卡交易。
在他們的AA架構中,依然用Lambda、ECS和Fargate等服務來執行容器、以S3和DynamoDB處理資料儲存和分析任務。由於信用卡交易涉及多個系統,每個系統的資料複製時間若為1秒,累計起來就很耗時。於是,他們採用DynamoDB的全域表功能,來盡可能縮短時間。
他們還有一項特別的作法:採取120%的過度配置。為什麼要用更高的成本,使用過多的資源,而不是剛剛好就好?
因為,不論何時發生故障,比如節點故障、EC2執行個體故障或AZ離線,他們都可以透過過度配置,來重新分配工作負載,並分擔工作量,避免影響到顧客服務。「但要記得一件事,在AA架構中過度配置,雲端成本容易暴增,」Kathleen deValk提醒,何時使用過度配置,還得視第一線業務需求而定。
韌性作法3:區域工作負載分配
不只如此,第一資本還有個區域混合方法,來兼顧韌性和處理速度。試想,民眾刷卡的當下,銀行接到交易通知,得要先偵測這筆交易是否為詐欺,通過後再確認帳戶餘額是否足夠。要是不夠,系統可能臨時決定給予額外額度、完成交易。這麼多個事件,都要在幾百毫秒內進行。
因此,系統間的通訊速度得快,更需要一致。第一資本發現,要做到這一點,就不能用不同區域的資源,來跳躍處理API呼叫鏈,因為他們曾測試發現,光用2個區域處理2次API呼叫,就耗費200毫秒!要是一個呼叫鏈有10個步驟,累加起來就是很可觀的延遲。
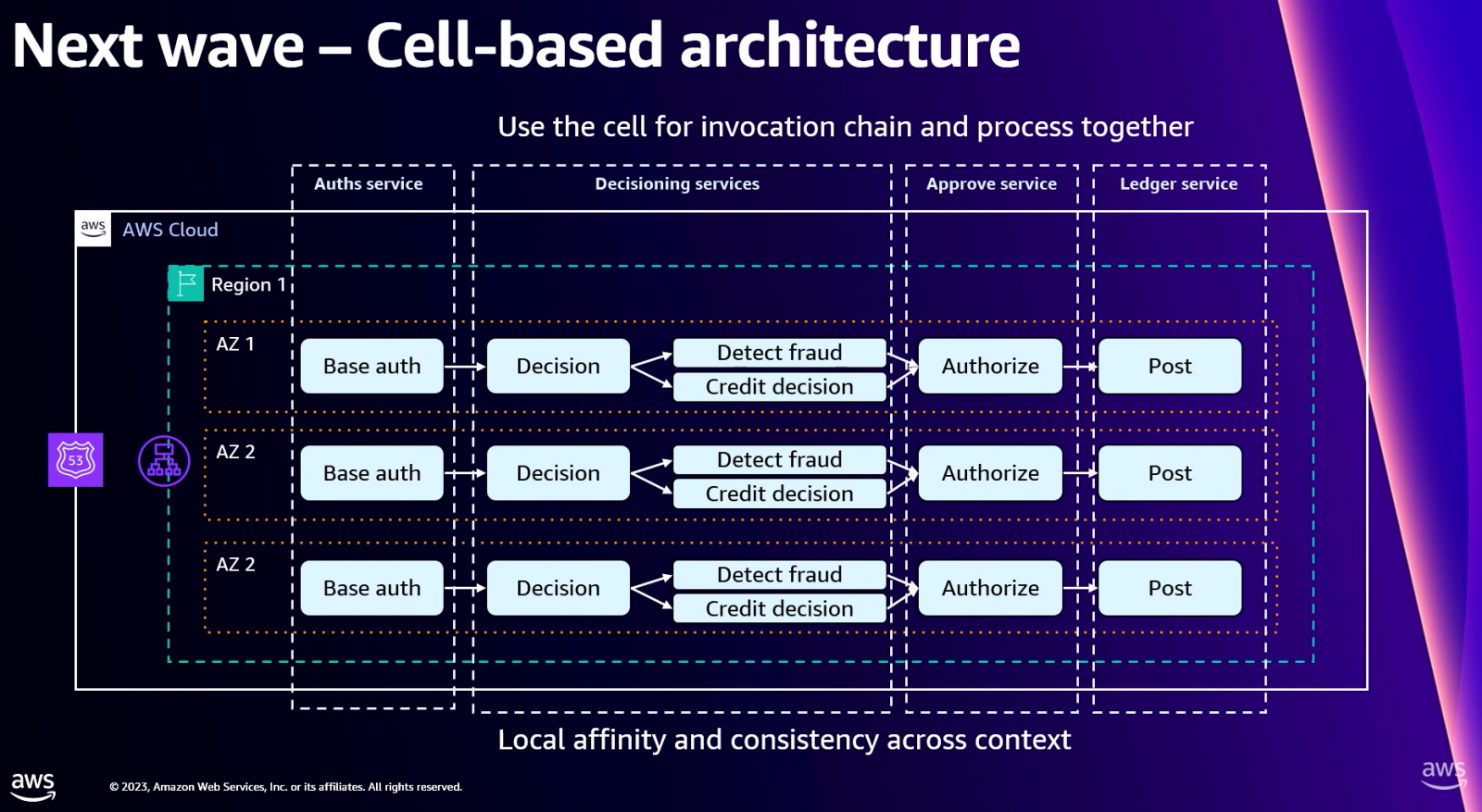
所以,他們規畫用2種技術來分配工作負載,一是採用AWS基於延遲的分配方法,來將負載自動分配到最有效率的區域,另一是在UI觸發API呼叫鏈後,改由該地的區域來執行,避免中間切換不同區域處理所衍生的延遲。
為做到這一點,第一資本還打造單元架構(Cell-based Architecture),將原本一支支微服務,按端到端流程隔離成一個單元,比如將信用卡驗證微服務、詐欺判斷微服務、授權微服務和處理微服務隔離成一個單元,並限定在同一個AZ執行。只有在故障發生時,才轉移到另一個AZ,來縮短處理延遲。(如下圖)
真實事件的反思:監控系統也要高可用
不過,2021年,第一資本遇到一場讓全公司雞飛狗跳的事件:雲端DNS網路服務AWS Route 53故障了。第一資本因此發生許多系統錯誤,經過與AWS重重溝通和根本原因分析,從中總結許多寶貴教訓。
第一是監控,「如果看不到正在發生的事,就像盲人一樣,無法做任何反應。」Kathleen deValk點出,他們發現,自家一些監控系統並沒有在多區域執行,因此受Route 53故障影響,這些監控系統失靈,看不到系統即時狀況,就算出問題,也難以解決。
第二是無法存取控制臺,導致備用的日誌起不了作用,排除故障也更困難。
第一資本根據這2個教訓,著手改善原本架構。首先是建置追蹤機制,在日誌系統中,當使用者功能被呼叫時,插入一個關聯ID,讓這個ID隨著功能處理流程傳遞下去。如此一來,技術團隊就能在故障發生時,找到故障所在之處,還能能更好地分析故障原因、設定更合適的重試和退回方案。
再來,他們也採用真實用戶監控方法,將使用者每個存取系統的動作,都記錄在日誌。這麼做,第一資本可以看到使用者與系統互動時,系統的即時狀況。綜合這些方法,他們可以打造預測性監控儀表板,進一步在日誌中尋找事件發生前的預警訊號,及早介入處理。
第一資本透過這些新方法,成功揪出潛在事件,比如偵測到一款應用程式的連接池不斷擴大,於是他們檢查基礎設施、找出問題根源並解決。
這種從事件中記取教訓、進而回頭改善IT架構設計,正是第一資本追求的「架構+SRE」最佳實踐。

熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09

2026-02-13


2026-02-10