
從8月20日開始,在中央研究院展開為期4天的2015年資料科學愛好者年會,相較2014年第一屆活動,今年不只多了2天,而且增加了更多做中學的工作坊,第一天打頭陣的工作坊,分別是Hadoop/Spark快速體驗營、R語言資料分析上手課程以及地圖資料視覺化課程。
其中Hadoop/Spark快速體驗營,是要參與者做中學,直接在現場實作,學習利用Hadoop分析資料。東森信息科技大數據顧問的趙國仁表示,他看到中國在大資料技術發展已有一定的成熟度。應用的範疇不僅是軟體面,還整合了硬體以及系統面,學界以及業界在人才與研究成果有良好的接軌。中國開源社群也很積極,甚至提交的大資料Kylin提案被Apache基金會接受為正式專案,而這也是臺灣沒有的紀錄。因此, 趙國仁想透過舉辦工作坊的形式,從最基本大資料教育做起,傳遞相關的技術知識。
中華郵政專員許勝淵說,要處理大資料的問題,最困難的階段就是入門,因為有太多相關的工具需要了解。像是這次有用到Hadoop、Hive、Hue、Impala等都是企業要做大資料分析時,可能會使用到的工具,不過要搞懂這些Hadoop Family之間的關係以及各自的功能就要花一番心力。
Hadoop相關工具非常多,中華郵政專員許勝淵說,要運用Hadoop來處理大資料,最困難的是入門,因為得花不少時間才能了解這些工具間的關係和各自功能。
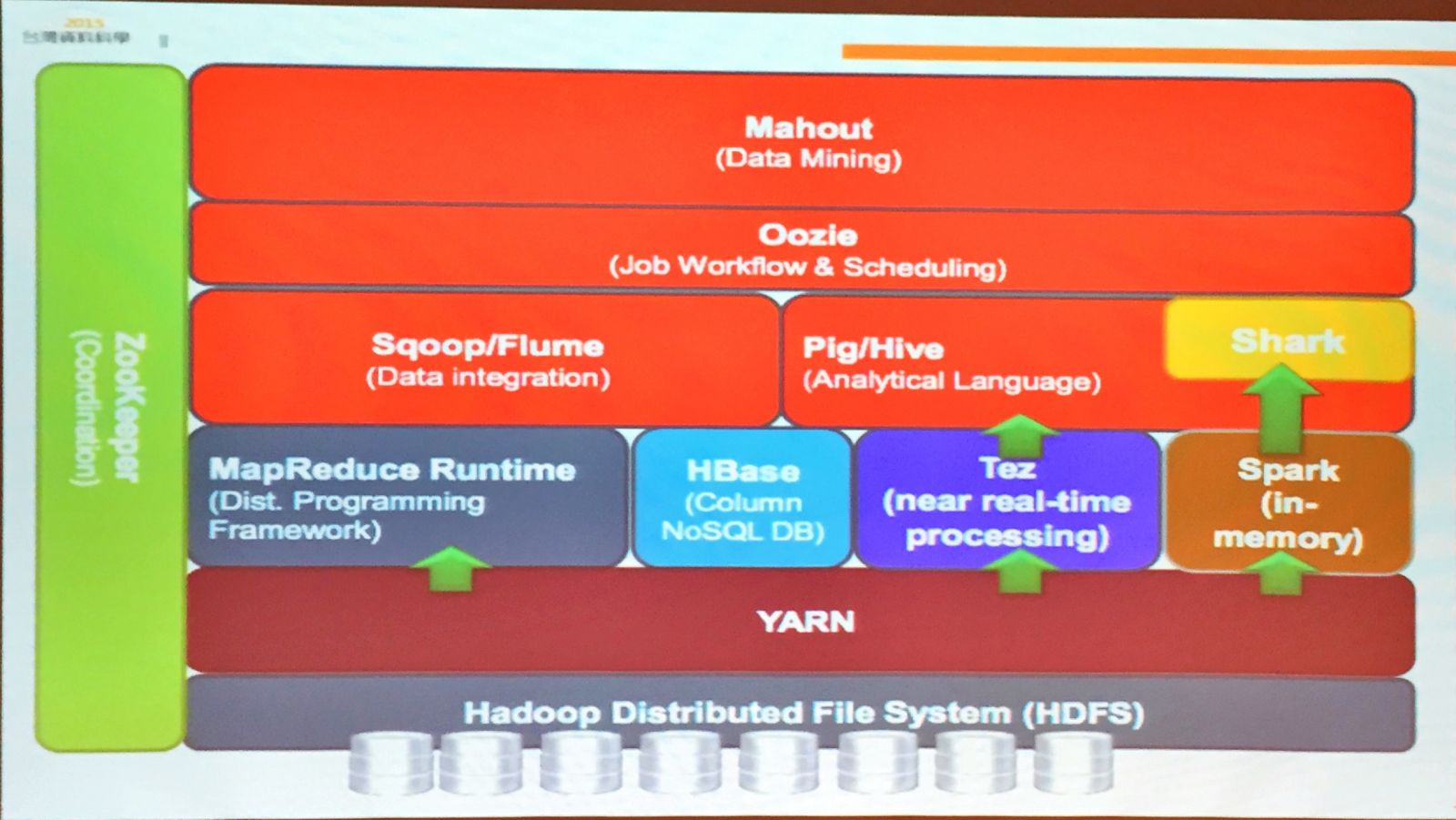
這次工作坊教學結束後有一個小測驗,要參加者分組實作一天所學,分析MovieLens的電影資料集,算出每個職業最愛的電影前5名,結束後發結業證書。而學員主要實機練習的工具,是用微軟Azure的Hortonworks與AWS EC2的Hadoop。Hadoop/Spark快速體驗營的參加者,除了工程師外,還有許多非技術人參與,因此講師也仔細講解,從開啟虛擬機器匯入資料到分析,每個指令ㄧ步一步說明和練習。
熱門新聞

2026-02-11

2026-02-09

2026-02-10
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-06

2026-02-10

2026-02-10

2026-02-10