
在2022年4月,AMD宣布併購資料處理器新創廠商Pensando,5月完成合併,後續他們持續號召更多企業採用,像是:HPE Aruba Networking宣傳CX 10000系列交換器,我們曾在2021年底報導;2022年8月底AMD與VMware宣布,AMD Pensando DPU(Pensando Distributed Services Card)是vSphere 8第一批支援的資料處理器;2023年6月AMD透露,IBM Cloud、微軟Azure、Oracle Cloud Infrastructure等公有雲業者部署Pensando DPU,IT服務廠商DXC也採用Pensando DPU。
到了今年,我們看到AMD展示資料中心解決方案時,在智慧型網路卡與資料處理器的產品線中,將Pensando與Alveo系列FPGA加速卡並列。


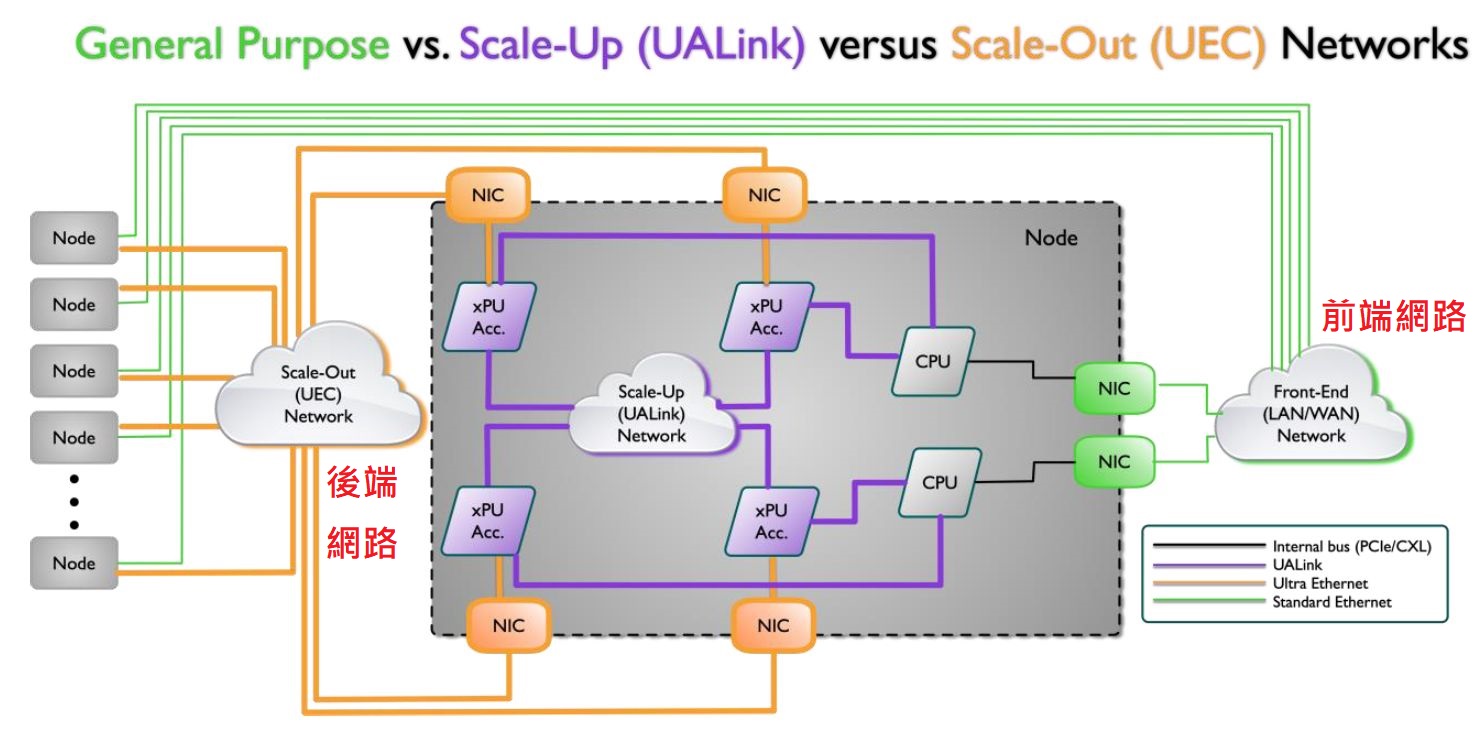
而且,在10月11日,AMD發表伺服器處理器第5代 EPYC、GPU加速器Instinct MI325X,以及企業級AI PC處理器Ryzen AI PRO 300,不過,出乎大家意外的是,他們也為了強化AI伺服器網路效能,推出兩個解決方案,一個是Pensando Salina DPU對應伺服器前端的網路連接,負責將資料與資訊傳遞至AI叢集,另一個是Pensando Pollara 400對應伺服器後端的網路連接,負責管理AI加速器與叢集之間的資料傳輸。


AMD當時預告,將於第四季開始提供這兩個解決方案的樣品,2025年上半供貨。

對照當前市場上的同類型解決方案,AMD的Pensando Pollara與Pensando Salina,分別主攻智慧型網路卡(SmartNIC)與資料處理器,而且支援400Gb乙太網路規格,不禁讓人聯想到競爭對手Nvidia旗下的Connect-X系列網路卡與BlueField系列資料處理器,而且,前幾年已推出支援400 Gb乙太網路與InfiniBand的Connect-X7與BlueField-3,現在AMD總算端出能與之抗衡的網路產品。
不過,Nvidia資料中心網路技術的布局稍早就已邁出下一步!例如,今年3月GTC大會他們發表Connect-X8 SuperNIC,支援800 Gb網路規格,6月預告Connect-X8 SuperNIC對應Blackwell架構GPU平臺,下一代智慧型網路卡產品Connect-X9 SuperNIC,將支援1600 Gb網路規格,並對應下一代Rubin架構GPU平臺。
運用可程式化引擎,率先支援超乙太網路聯盟的傳輸標準
AMD最新推出的AI網路卡Pollara 400,是針對2023年7月新成立的超乙太網路聯盟(UEC)倡議的高效能網路標準而來,而且是市面上第一款提供充分支援的AI網路介面晶片(UEC-ready AI NIC),可用於搭配新一代RDMA軟體使用,背後將由開放的網路生態系統提供支持。

值得注意的是,此處所提到的,應該是超乙太網路傳輸(Ultra Ethernet Transport,UET),2023年超乙太網路聯盟公開UET,今年3月揭露UET 1.0規格,而在10月舉行的2024 OCP高峰會期間,超乙太網路聯盟成員預告UET 1.0將於2025年第一季正式發布。

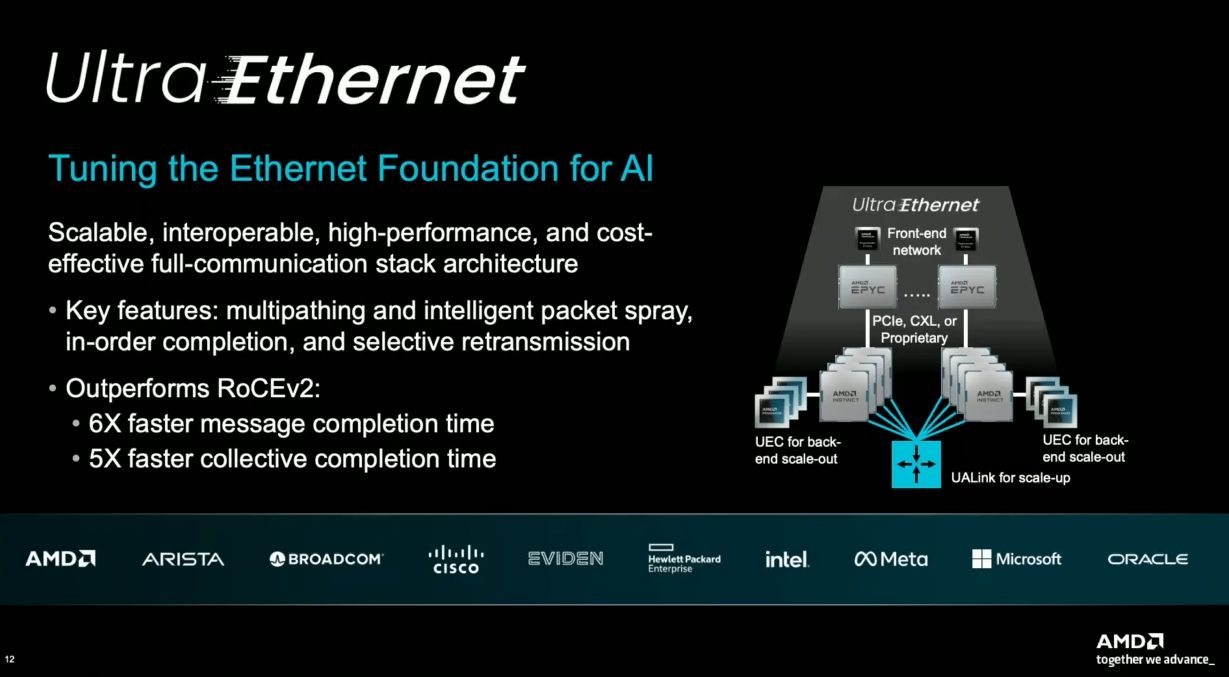
AMD同時也強調,對於伺服器後端網路的AI加速器對接通訊應用,Pollara 400這款AI網路介面的採用,能帶來存取效能、規模延展性、執行效率等多種層面的提升。例如,若以標準的RoCEv2存取為比較基準,Pollara 400由於支援UEC-ready RDMA,完成整個訊息傳輸的時間僅需1/6,而用於AI工作負載與多個GPU彼此溝通的集合通訊(Collective Communication),完成傳輸的時間則是減至1/5。

事實上,Pollara 400本身配備AMD發展的第三代P4語言執行引擎,內建232個比對處理器(Match Processing Unit,MPU),以及58個資料表引擎(Table Engine),用於資料層(Data Plane)與多種服務的加速處理,能針對多個同時在單一裝置(Pensando Pollara 400)執行的服務,提供400GbE網路線速的吞吐量。

AMD資深副總裁暨網路技術解決方案事業群總經理 Soni Jiandani表示,有了這樣的技術,使得AMD能夠適應乙太網路的持續進化,並且符合AI工作負載所需,而成為業界唯一擁有P4引擎,並以此驅動前端的GPU互連網路,以及後端的Pensando Pollara產品的互連網路,也因為具備完整的可程式化能力,促使他們的解決方案面臨AI系統規模擴張之際,仍然能夠經得起時間考驗、涵蓋整個網路環境不同層面的使用,進而提供更周延的產品搭配。

Pensando Pollara 400是在AMD Advancing AI發表會推出的其中一項解決方案,AMD資深副總裁暨網路技術解決方案事業群總經理 Soni Jiandani對參加AMD Advancing AI發表會的分析師,展出實際的產品
提供多種強化網路效能的技術
Pollara 400除了透過P4提供完整可程式化的RDMA傳輸能力、相容於RoCEv2標準,強化後端網路運作效率,並且支援UEC這類正在快速發展的業界標準技術,這款產品還提供多種改善網路效能的功能,包含:智慧型封包濺散處理(Intelligent Packet Spray)、訊息依序傳遞至GPU(In-Order-Delivery)、有選擇能力的網路重新傳輸(Selective Retransmission)、具有路徑感知能力的網路壅塞預防(Path Aware Congestion Avoidance)。
根據AMD對這款產品發布的常見問答集文件指出,上述網路堵塞控管功能也是有別於其他競爭產品的部分,超乙太網路聯盟與AMD在2024 OCP高峰會在推廣UET網路標準時,也描述當中想要解決的網路傳輸問題,AMD也透過一篇「用Pollara 400進行AI網路轉型」的部落格文章,細部闡述這些功能。
所謂的智慧型封包濺散處理,是指Pollara 400能夠橫跨多個路徑,聰明地將佇列配對(Queue Pair,QP)的封包進行分發處理,可完整利用所有能夠存取的網路頻寬,尤其是將這款產品用於CLOS交織網路架構時,可縮短訊息完成傳輸的時間與尾部延遲(tail latency),降低AI網路過於集中與流量堵塞的可能性,確保網路傳輸效能的品質,因此,AMD也稱其為進階的自我適應封包濺散處理技術,能有效因應AI模型的網路大量頻寬佔用,以及低延遲存取的要求。
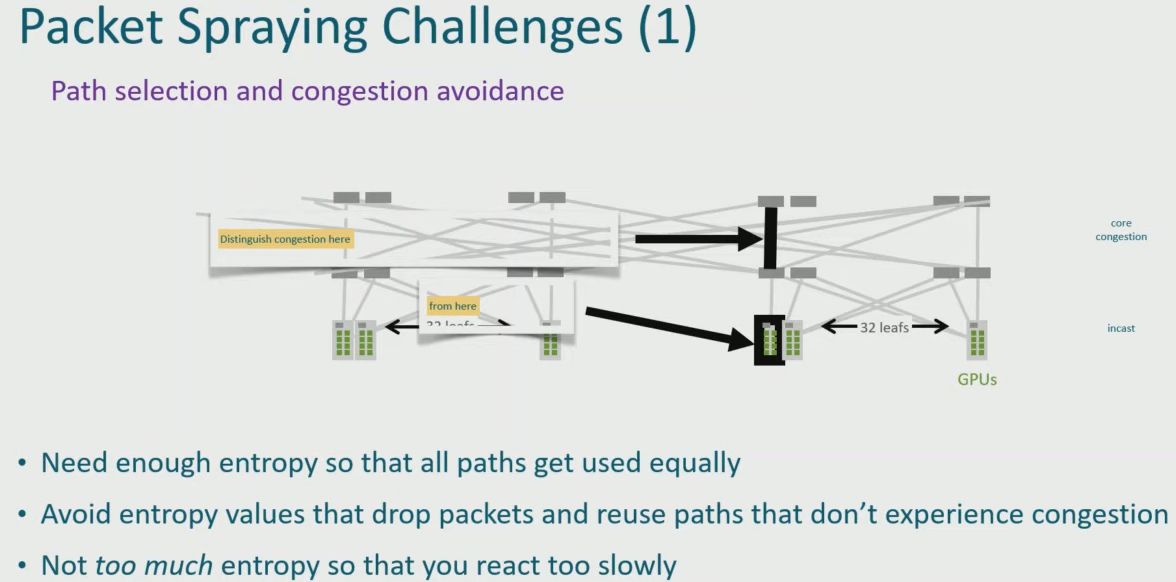
另一個內建的訊息依序傳遞功能,主要是為了因應多路徑傳輸(multipathing)與封包濺散技術的採用之後,經常會發生脫序的封包送抵狀況,Pollara 400可提供的解決之道在於,網路卡能以更有效率的方式處理資料封包的接收,當資料封包以異於原始傳送的順序抵達目標端時,會毫不遲疑地將這些內容直接放置到GPU記憶體。由於是從網路卡的層級管理網路傳送的複雜狀況,因此,系統可維持高效能與資料完整性,不會造成GPU的負擔,進而降低延遲、改善系統整體運作效率。

關於具有選擇能力的網路重新傳送技術,是指Pollara 400可經由上述的訊息依序傳遞,以及有選擇的確認(Selective Acknowledgment,SACK),強化網路效能,能在封包丟失復原的處理過程中,盡量避免非必要的封包重新傳送作業,進而提升網路頻寬的使用率、降低延遲。
AMD表示,SACK能協助Pollara 400辨識遺失或壞掉的封包,而且只需重新傳送這些封包。相較之下,RoCEv2採用的Go-back-N作法,一旦遇到單點故障就會重新傳送全部封包。而在結合訊息依序傳遞與SACK運用後,Pollara 400能促使資料傳遞更為順暢,提高網路資源的使用率,進而縮短工作完成時間與尾部延遲,更能因應要求嚴苛的AI網路環境,以及大規模機器學習處理程序的運作。
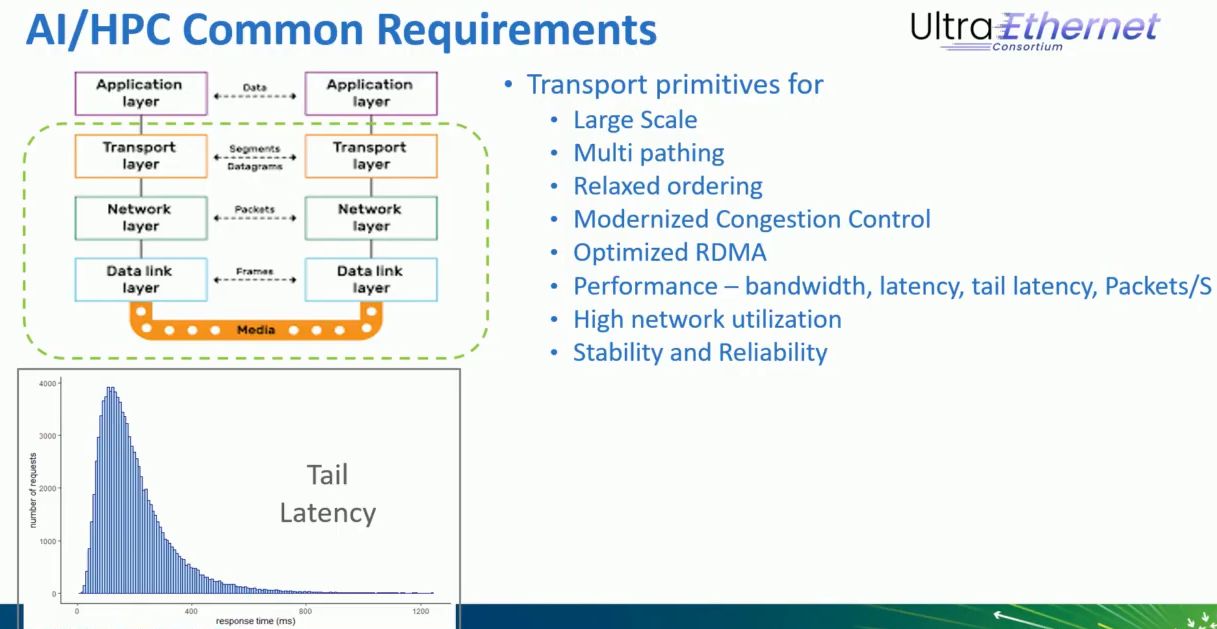
接下來是具有路徑感知能力的網路壅塞控制功能,Pollara 400可運用即時遙測與能夠了解網路傳送的演算法,有效管理眾多流量傳入(incast)這類網路堵塞狀況。
一般而言,若在高可靠、不丟失任何封包的網路環境(lossless network),使用RoCEv2傳送資料,需仰賴基於優先程度的流量控制(PFC),以及明確壅塞感知(ECN)這兩種機制;透過UEC Ready RDMA傳輸,可搭配多種作法,像是:維持每個路徑的壅塞狀態,運用自我調適的封包濺散處理而能動態繞過壅塞路徑;在暫時壅塞期間,維持近乎線速的網路效能;橫跨多個路徑傳送,可在不用PFC的狀況下,提升封包遞送效率;實作每個傳輸流程的壅塞控制,預防不同資料傳輸處理之間的干擾。
AMD表示,基於上述這些機制,可簡化設定、減少作業負擔,並且避免常見的壅塞現象擴散、流量鎖死(deadlock)、網路傳送佇列阻塞(head-of-line blocking)等問題,對於大型AI處理相當重要,因為能藉此提供明確、可預測的網路效能,加快AI資料中心的部署。
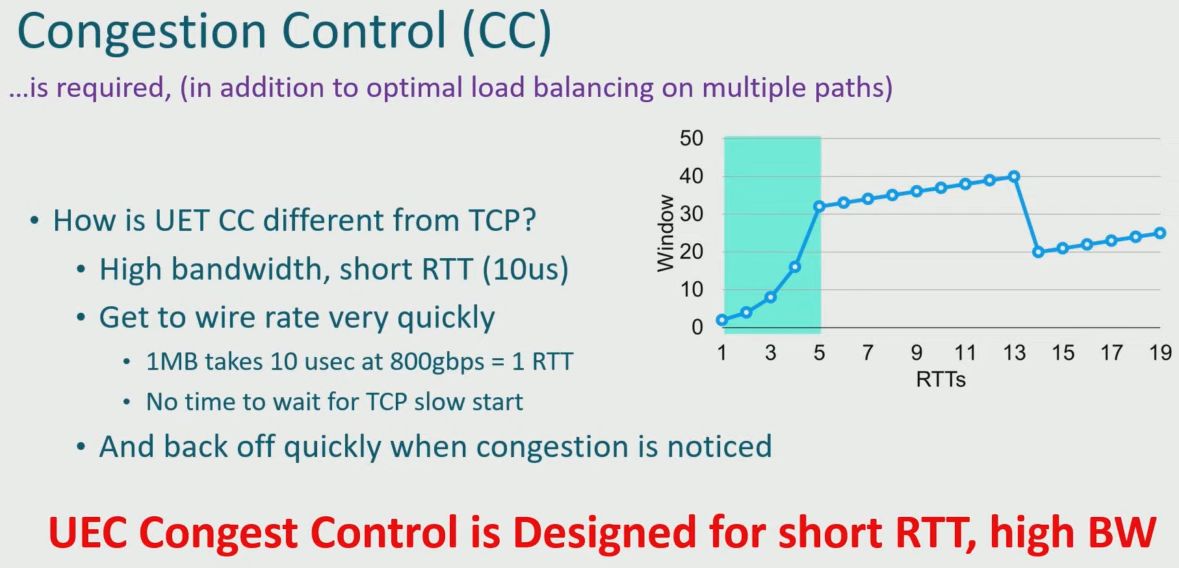
為了確保AI系統的網路運作效率,Pollara 400也提供快速偵測錯誤技術(Rapid Fault Detection)維持最佳效能。AMD表示,對於AI應用程式而言,標準協定的逾時處理機制,運作速度太慢,此時需要積極的錯誤偵測功能,將重要環節標示出來,像是能夠減少GPU閒置時間的任務,以及增進AI訓練與推論吞吐量的任務,以便大大縮減整個工作完成的時間。

這方面功能有三種,首先是基於傳送端的確認監控(Sender-Based ACK Monitoring),可運用傳送端的能力,橫跨多個網路路徑追蹤相關的確認處理機制;第二是基於接收端的封包監控(Receiver-Based Packet Monitoring),能監督連入的封包傳輸流程,接收端可針對個別網路路徑,追蹤封包接收狀況,能發現潛在問題,例如封包未在指定期間抵達某個路徑位置;第三是基於探針的驗證(Probe-Based Verification),當企業導入前兩種做法而觸發疑似故障狀況時,可啟用這項機制,過程中,Pollara 400可將一個探針封包傳到可能故障的路徑上,如果在指定期間探針沒有收到任何回應,該路徑就會被確認為無法使用。透過這個額外的步驟,能協助企業區別是否為暫時發生的網路問題,或是實際的路徑不通。
產品資訊
AMD Pensando Pollara 400
●原廠:AMD
●建議售價:廠商未提供
●外形:半長半高
●網路介面:1個400GbE埠(QSFP112),最大頻寬400 Gbps,可分接2個200GbE埠或4個100GbE埠、50GbE埠、25GbE埠
●I/O介面:PCIe 5.0 x16
●儲存加速應用:RDMA、RoCEv2、UEC Ready RDMA
●支援管理應用:MCTP/SMBus、SPDM over MCTP、MCTP over PCIe VDM、PLDM firmware
●支援的軟體開發套件:Pensando DPDK、Pensando SSDK
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-09

2026-02-10

2026-02-06

2026-02-09

2026-02-10

2026-02-10

2026-02-10

2026-02-09