去年11月15日微軟在年度IT專業人員大會Ignite期間,突然宣布推出自行設計的Arm架構處理器Azure Cobalt,第一代產品Cobalt 100將內建128顆核心,展現Arm架構具有能源使用效益的設計之餘,相較於現行Azure雲端服務所搭配的Arm處理器,新的晶片運算效能領先幅度可達到40%,而且,正用於支撐Microsoft Teams、Azure SQL等服務。微軟表示,坐落在美國華盛頓州昆西市的Azure資料中心,已率先建置多臺採用Azure Cobalt 100的伺服器。
在此之前,微軟Azure在2022年4月宣布將推出Arm架構執行個體服務,也就是Dpsv5系列、Dplsv5系列、Epsv5系列,當中搭配的處理器是Ampere Computing公司的Altra系列,而且是基於Arm Neoverse N1矽智財平臺而成的,同年9月,這批雲端服務正式上線。
經過一年多之後,微軟後續發表自有品牌的Arm處理器Azure Cobalt 100,外界都在好奇這家長期發展軟體與雲端服務的公司,憑什麼具有設計這類產品的能力。事實上,在2015到2018年之間,他們與伺服器處理器與FPGA大廠英特爾合作,打造兩代SmartNIC加速網路環境,到了2023年初,微軟突然宣布併購資料處理器(DPU)新創公司Fungible,但這些舉動並不足以回答上述問題。

去年11月,全球雲端服務大廠微軟突然宣布推出自有品牌的Arm架構處理器,名為Azure Cobalt 100,這款產品正是基於Arm Neoverse CSS而成,向市場昭告開發特製晶片的設計門檻將大幅降低,可望吸引更多公司投入發展。
答案在Arm發布的新聞稿揭曉!Arm 資深副總裁暨基礎設施事業部總經理 Mohamed Awad表示,Azure Cobalt 100是充分運用Neoverse CSS平臺而成,繼續享有基於Arm架構發展的強大軟體生態的同時,在這樣的設計方式之下,微軟可以省下更多時間與開發心力,專心拓展更多獨特的技術創新與最佳化調校方式。
他強調,對於微軟這樣的大型雲端業者而言,透過Neoverse CSS的提供,可協助他們組建與部署自行設計的矽晶片,而且能善用Arm持續發展、可廣泛支援多種應用領域的技術平臺,重新思考運算的樣態,採取更有戰略優勢的決策,促使整個產業更容易推動各種創新。
今年2月下半Arm發表基於新一代Neoverse矽智財的Neoverse CSS之際,更進一步說明雙方的合作概況。
Arm基礎設施事業部產品解決方案副總經理 Dermot O'Driscoll表示,他們之所以建立Neoverse CSS這樣的計畫,目的是提供用戶對於矽晶片技術堆疊的控制能力,就如同他們目前能夠控制軟體與系統的技術堆疊;同時,CSS本身是一種密切的協同運作關係,合作廠商強烈希望Arm將晶片設計方式提升到新的層次,而微軟Azure Cobalt的推出,正好呈現了這樣的關係:Arm開發Neoverse CSS N2,並與微軟共同合作設計,而成果就是Azure Cobalt 100處理器。

他強調,Neoverse CSS N2的組建,主要是著眼於雲端橫向擴展規模類型的市場需求,當中需滿足多種應用情境,而採用這種技術的系統可部署為高效能的公有雲環境,或調整為服務用戶內部環境的超大型工作負載;而對於其他用戶而言,也能善用這個新的抽象化設計層級,促使矽晶片更快推出。
因此,他認為從超大型業者到新創公司,CSS將成為大家都能夠倚重的作法,可將技術應用創新推升到新的高度,基於這樣的理由,Arm決定進一步擴充這類型的產品線,宣布推出新的CSS平臺:Neoverse CSS N3系列、Neoverse CSS V3系列。
CSS N2初試啼聲,Arm發表第一代運算子系統
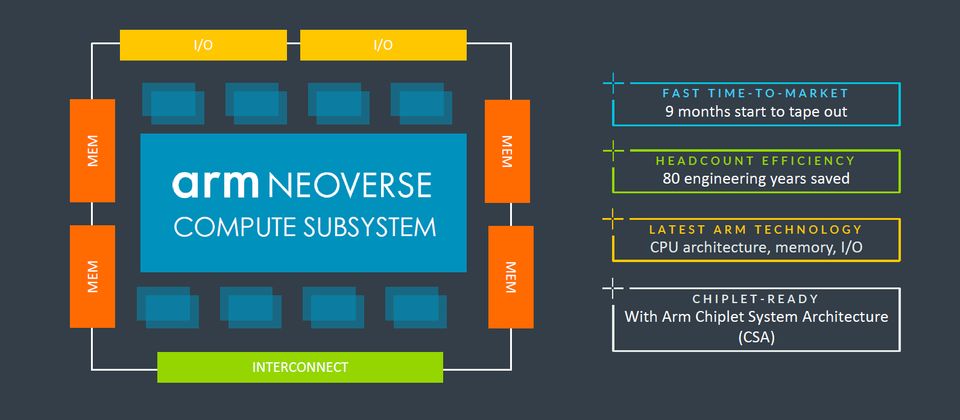
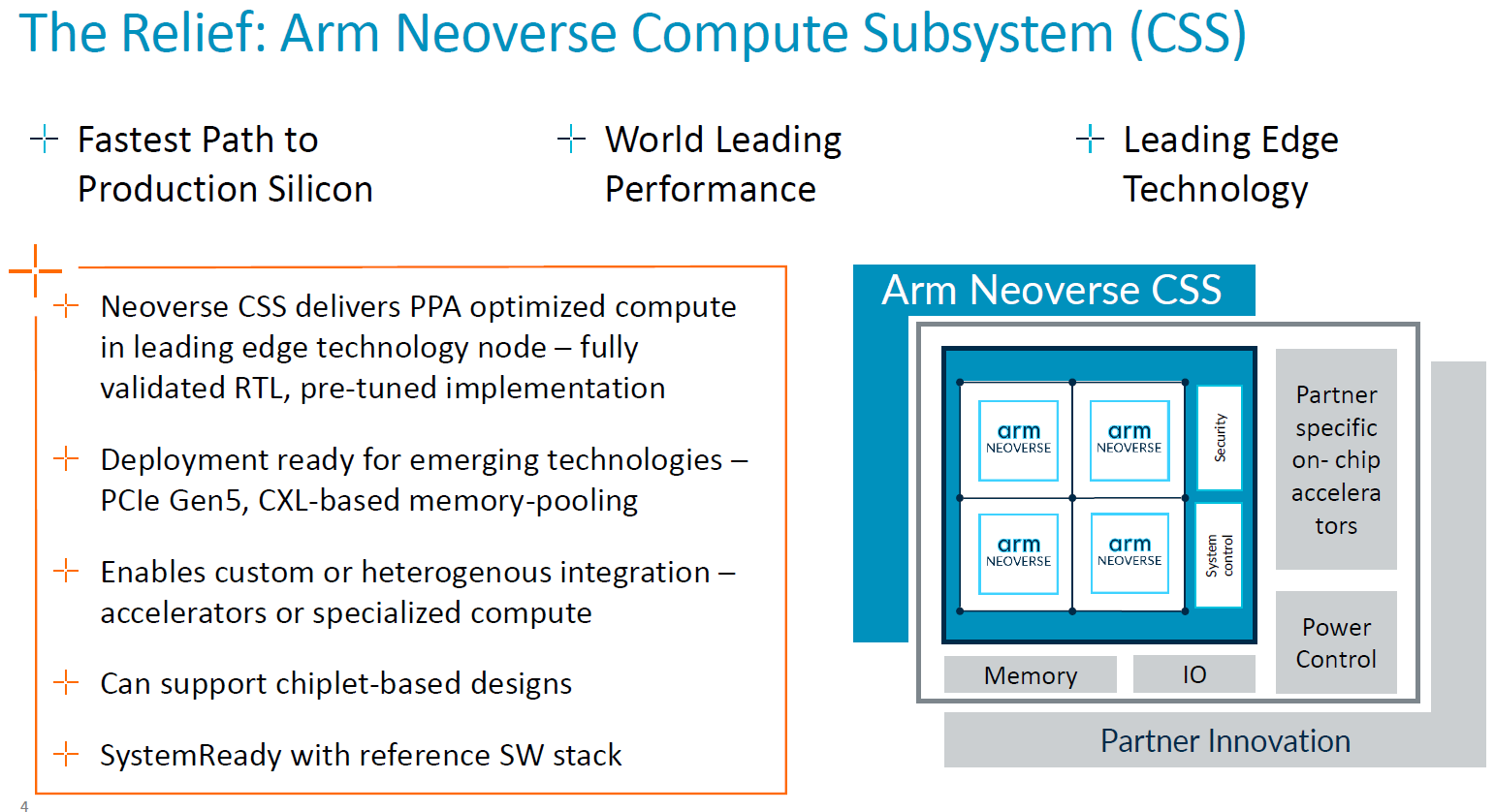
何謂Neoverse CSS?全名為Neoverse運算子系統(Neoverse Compute Subsystems),是在2023年8月Hot Chips年度大會發表的新型態矽智財平臺,而且以「CSS-Genesis」稱呼第一款產品Neoverse CSS N2,象徵這系列解決方案的發展,將對於整個市場帶來重大而深遠的影響,並強調Neoverse CSS N2可用於特製矽晶片的組建設計,提供所有運算子系統元件。
簡而言之,Neoverse CSS是Arm針對Neoverse晶片架構的設計,提供預先整合與通過驗證的組態,目的是減少開發成本、縮短上市時間。有了運算子系統這類型的設計方案,對於與Arm合作的公司與組織而言,不僅有能力自行組建各種特製的矽晶片,享有頂尖的能源使用效率、延展性、多核心運算,以及強大的軟體生態,比起搭配個別的矽智財,導入CSS可獲得許多效益,像是耗費的成本更低、面臨的設計失敗風險更小、上市時間更短,使Arm發揮所長,相對地,用戶能夠將自身的資源與心力集中在關鍵差異,以便突顯優勢。
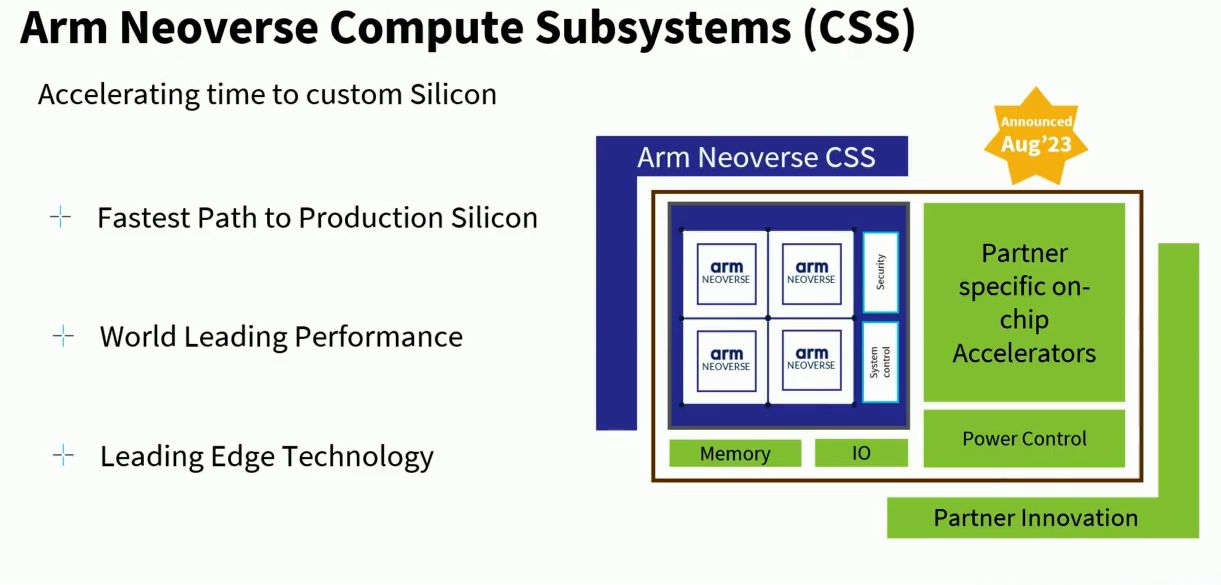
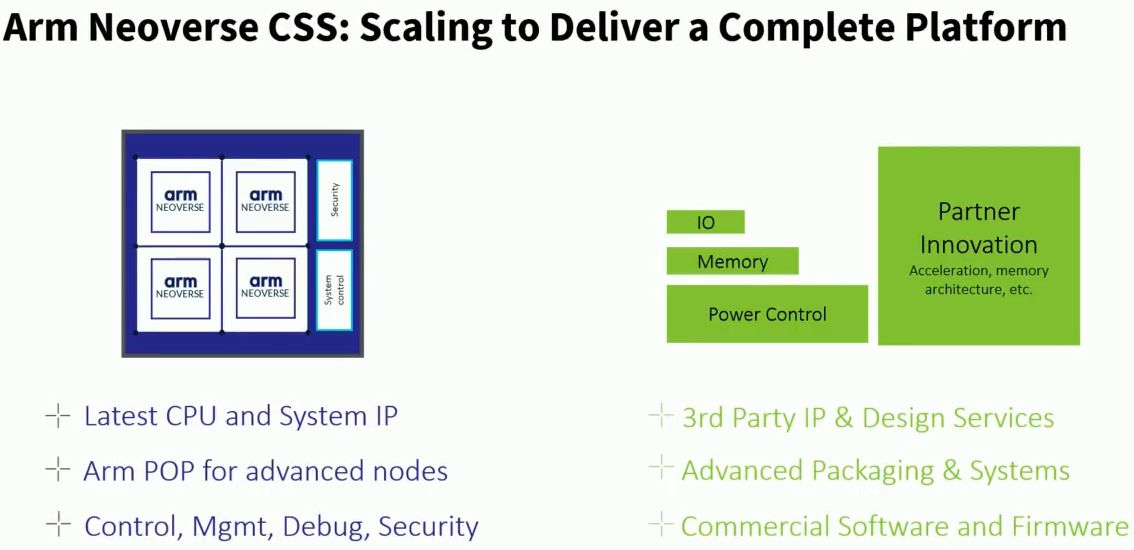
而在今年2月Arm發表更多運算子系統,也針對這個產品概念提出更多詮釋。Arm基礎架構事業部行銷副總裁Eddie Ramirez 表示,CSS整合Arm旗下多種矽智財,是針對耗電量、效能與外形尺寸調校之後的最佳組態,而且這樣的設計能夠非常容易用於先進製程,所以Arm在此提供的是用於特製系統單晶片的基本組建模塊,可透過頂尖的效能與技術實現這樣的設計。
但Eddie Ramirez也強調,CSS並非用來組建最終版本的矽晶片,因為,這當中仍需要搭配第三方的矽智財,提供記憶體與I/O的選擇,同時,也需要與EDA工具廠商合作,以便將CSS設計流程調校至最佳狀態,所以必須與整個業界保持緊密合作關係。
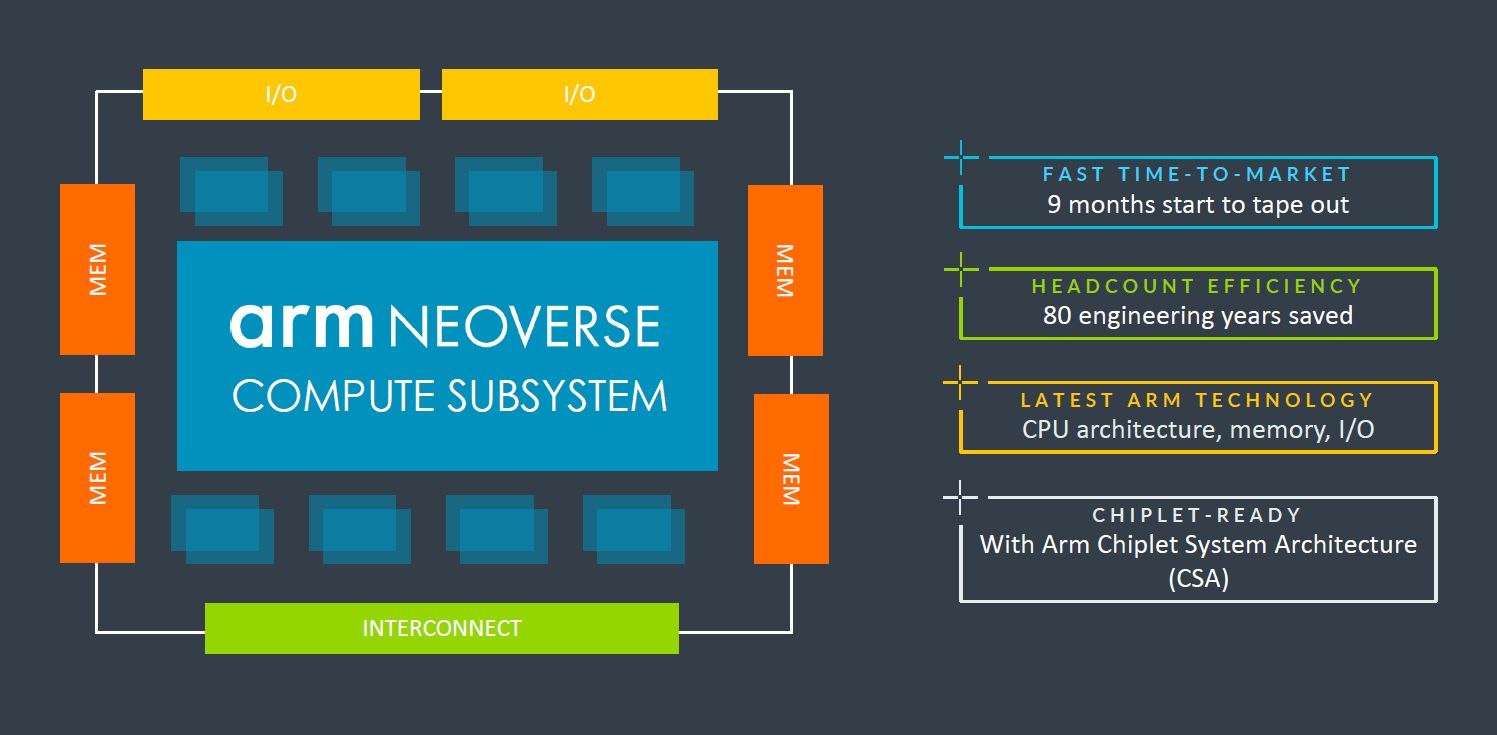
Arm Neoverse CSS的推出,目的是促使特製矽晶片的設計與組建過程能夠更快、更容易進行,與Arm合作的廠商可將心力聚焦在系統層級工作負載差異化,例如軟體調校、自定加速機制,用戶也將得到多種效益,例如,更快推出產品、降低工程成本,並且善用頂尖的處理器技術。
因此,基於CSS這樣的產品,Arm可提供完整平臺,並藉由整個系統單晶片設計生態系的幫助,而能使業者與用戶得以整合所有最先進的技術,包括第三方矽智財、小晶片技術、商業軟體與韌體。目前Arm正在發展可涵蓋各個層面的設計流程,以強化整個生態系的力量,進而將這些解決方案供應市場。
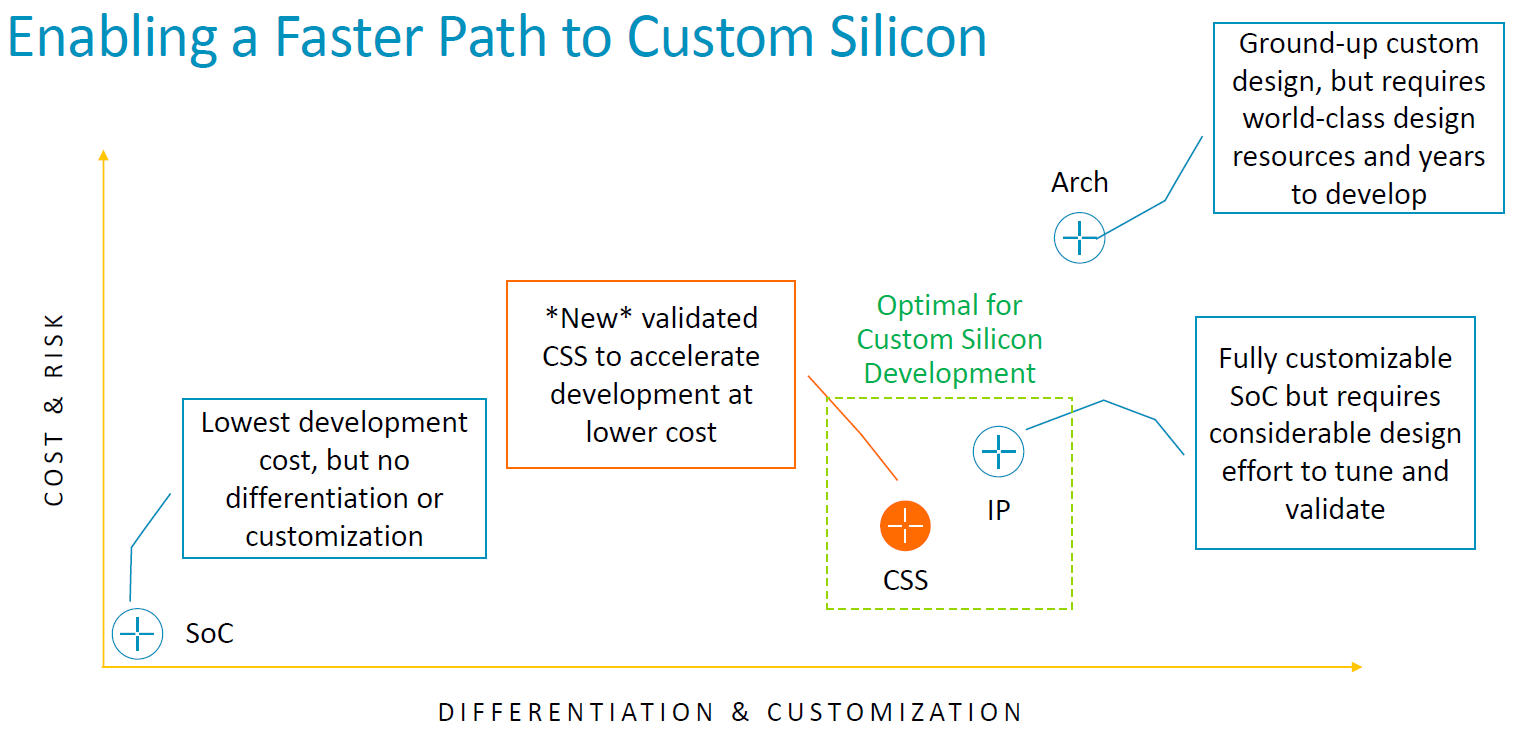
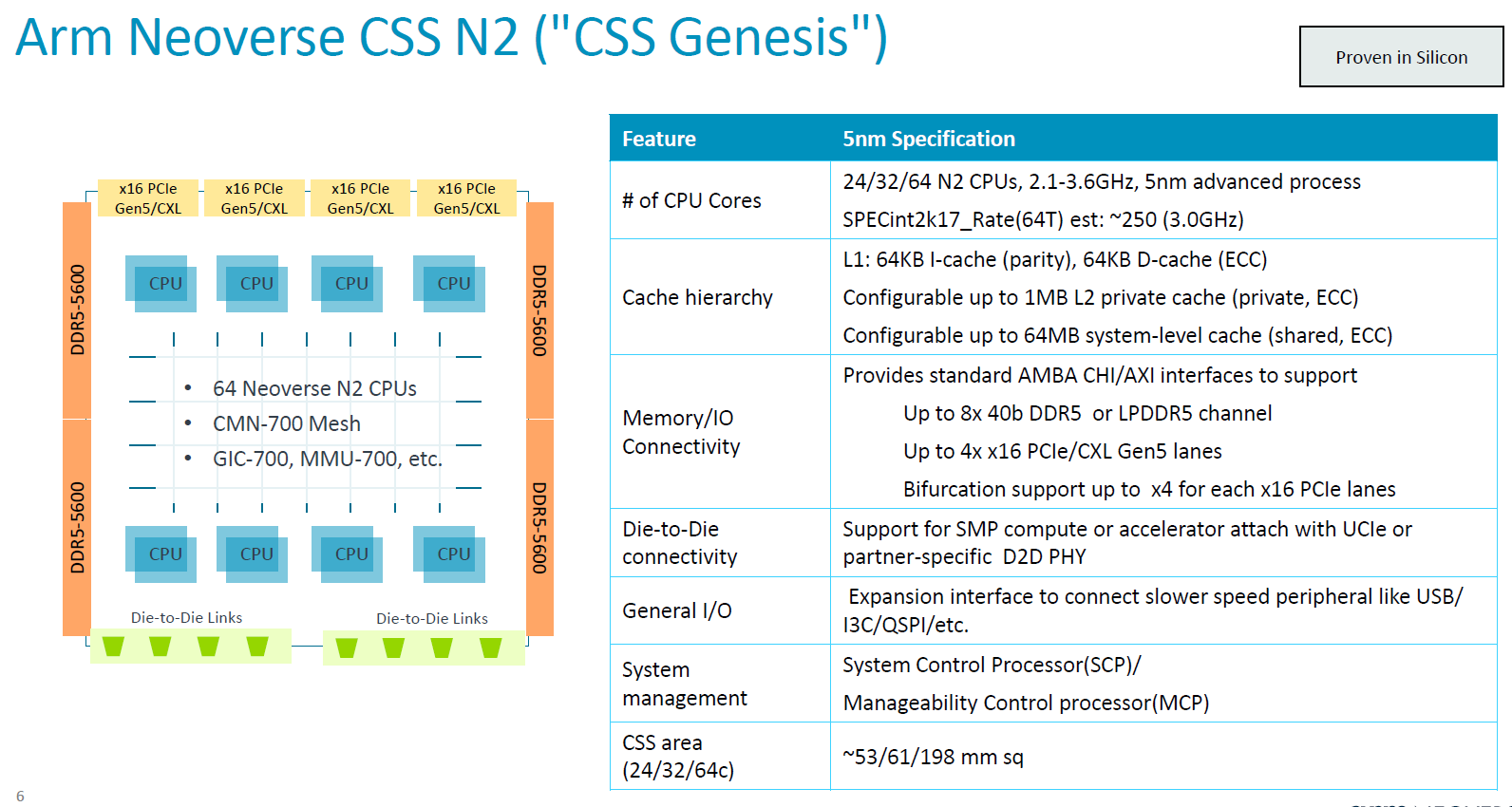
檢視Arm推出的第一代運算子系統產品是Neoverse CSS N2,顧名思義,當中將提供組態預先整合與驗證的Neoverse N2平臺,而且功耗、性能及晶片面積(PPA)皆導入最佳設計,使Neoverse N2兼具每瓦效能、快速上市、已針對5奈米先進製程調校的特色,從而以「自定運算子系統(customizable compute subsystem)」的形式交付至合作廠商。Arm表示,這些業者可在記憶體、I/O、加速運算、實體拓樸等領域,進行不同的變化,建立產品差異,並且充分因應針對不同工作負載進行最佳化調校的晶片設計需求。
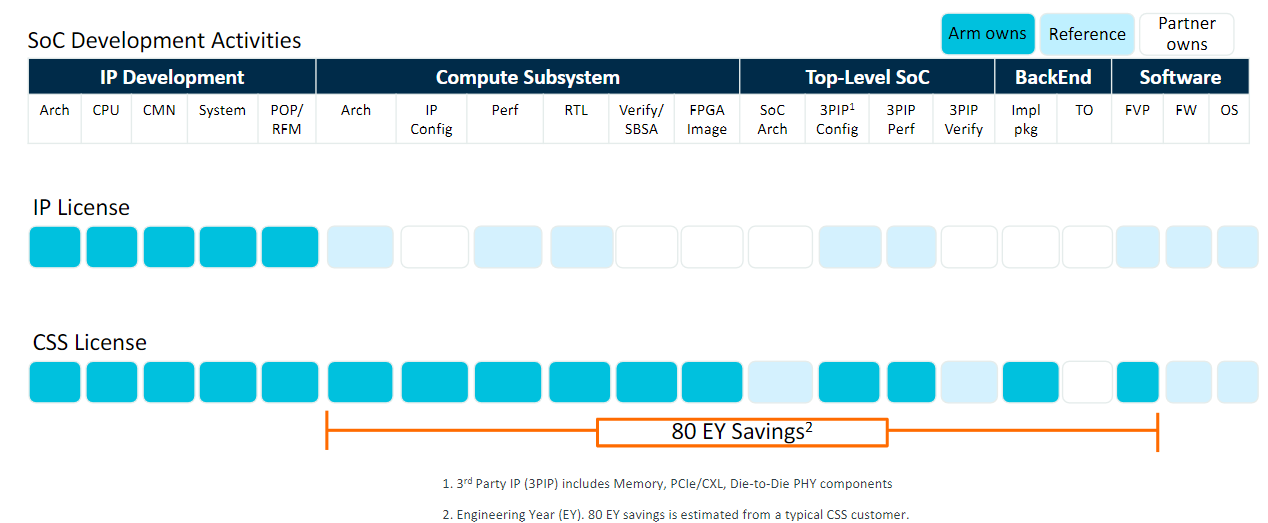
關於設計負擔的減輕,Arm表示,若採用Neoverse CSS N2,合作廠商的工程資源可聚焦在系統單晶片(SoC),以及系統層級的創新。而在實際應用的成效上,他們提到兩個案例,一家廠商開發內建超過1百顆核心的晶片,僅耗費13個月,此運算平臺就達到能以Linux作業系統開機啟動的地步,另一家廠商表示,採用CSS授權更划算,比起購買少量智財授權,再自行設計與組建運算子系統、建構系統單晶片、實作晶片封裝,到開發軟體,可節省80個工程人年(engineering years)的開支。
至於現今所有產業密切關注如何支援AI這類特定領域的加速運算應用,期盼所用的晶片具有領先市場的每瓦效能表現,並能因應雲端原生應用類型的工作負載,對此,Arm認為Neoverse CSS N2證明其設計足以承擔重任。
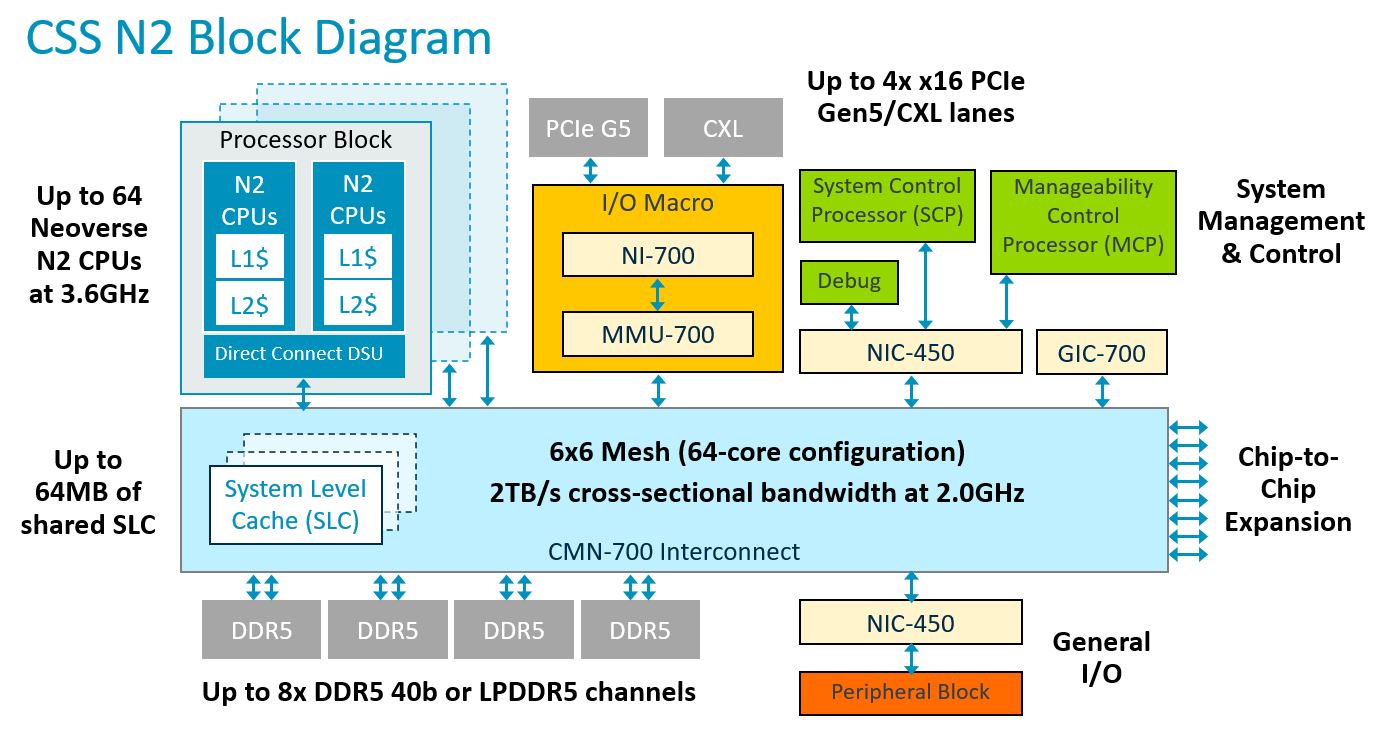
就具體規格而言,Neoverse CSS N2提供哪些配備 ?以處理器核心而言,導入5奈米製程,運作時脈介於2.1 GHz至3.6 GHz之間,可設置24顆、32顆到64顆Neoverse N2核心,支援Armv9世代的運算架構指令,可用於向量處理、機器學習、強化的密碼學處理、記憶體的分割與監控,以及進階的電源管理。基於上述特色,這套運算子系統可涵蓋5G網路通訊、資料處理器、雲端運算,以及AI等應用領域。
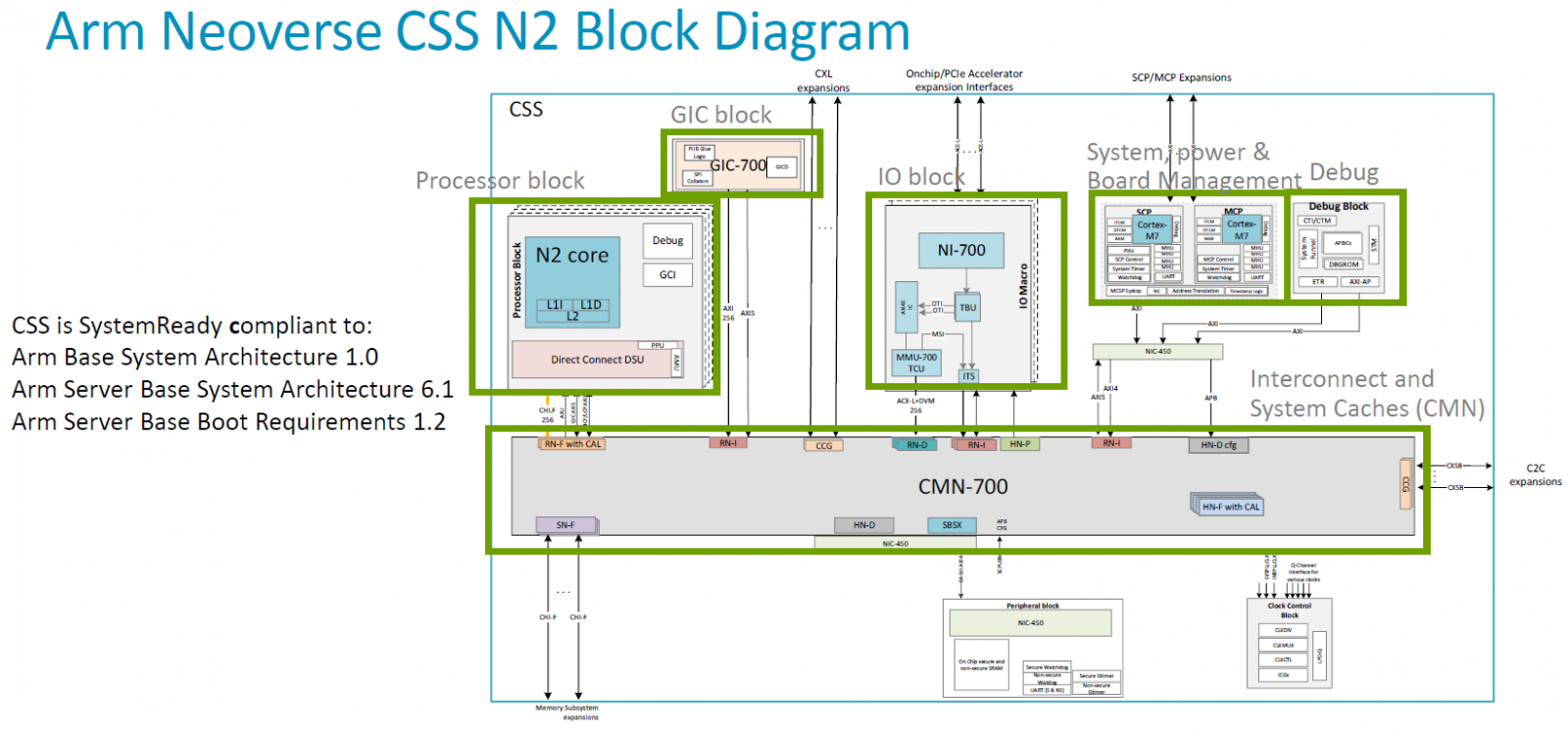
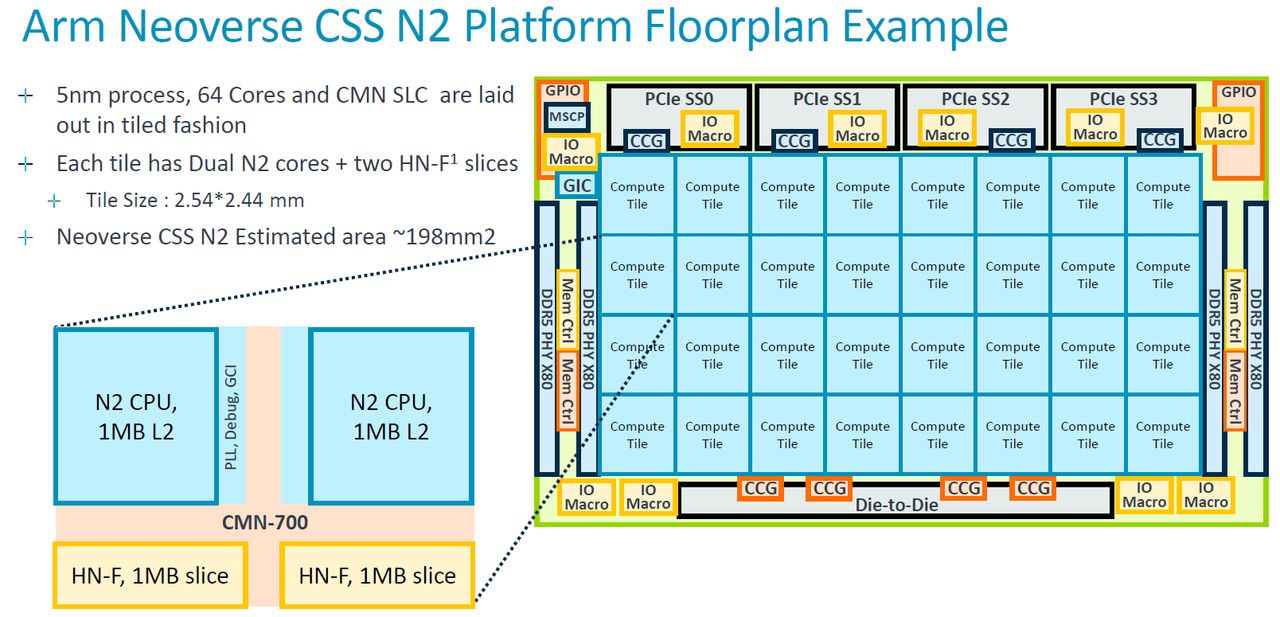
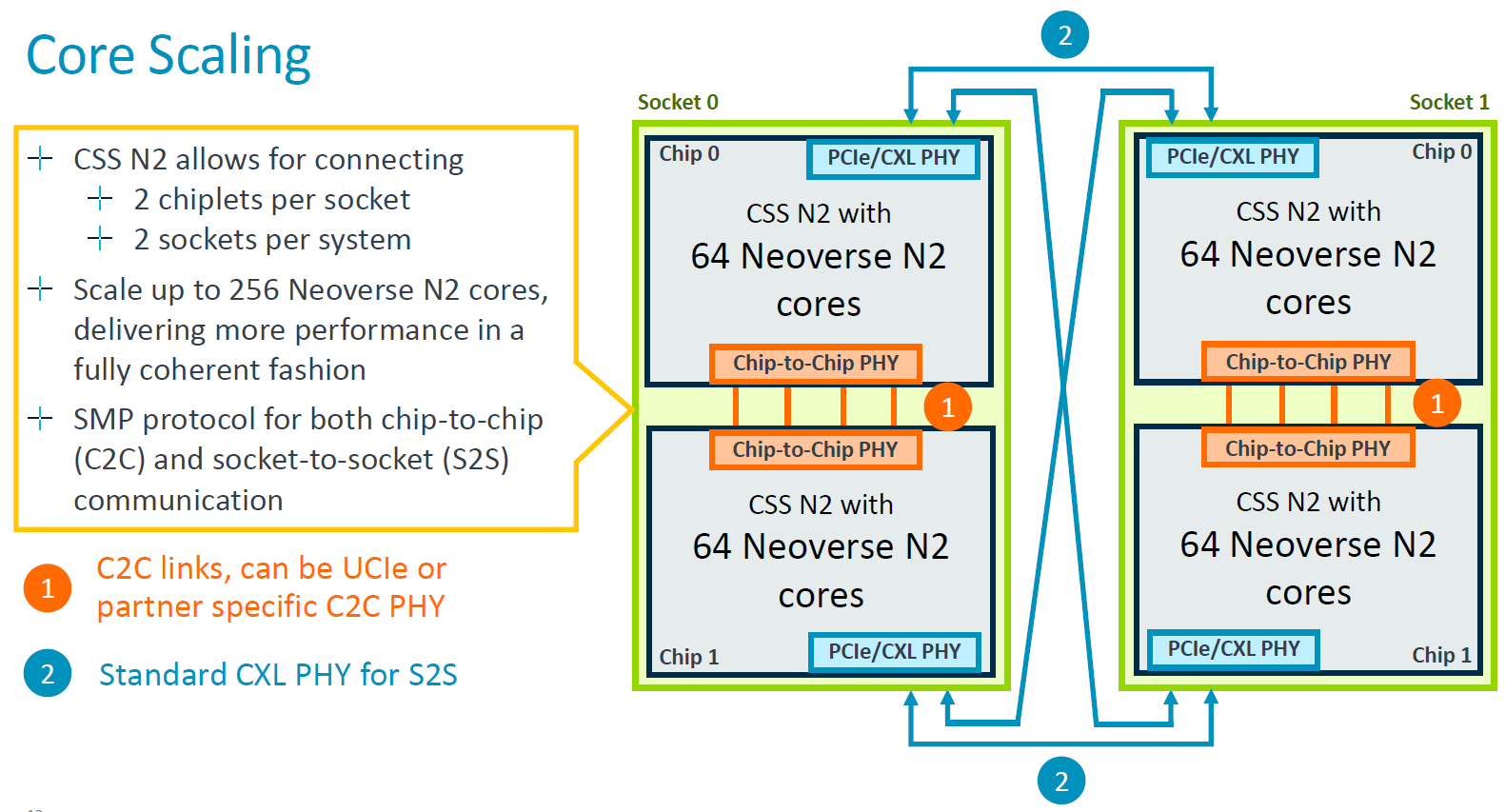
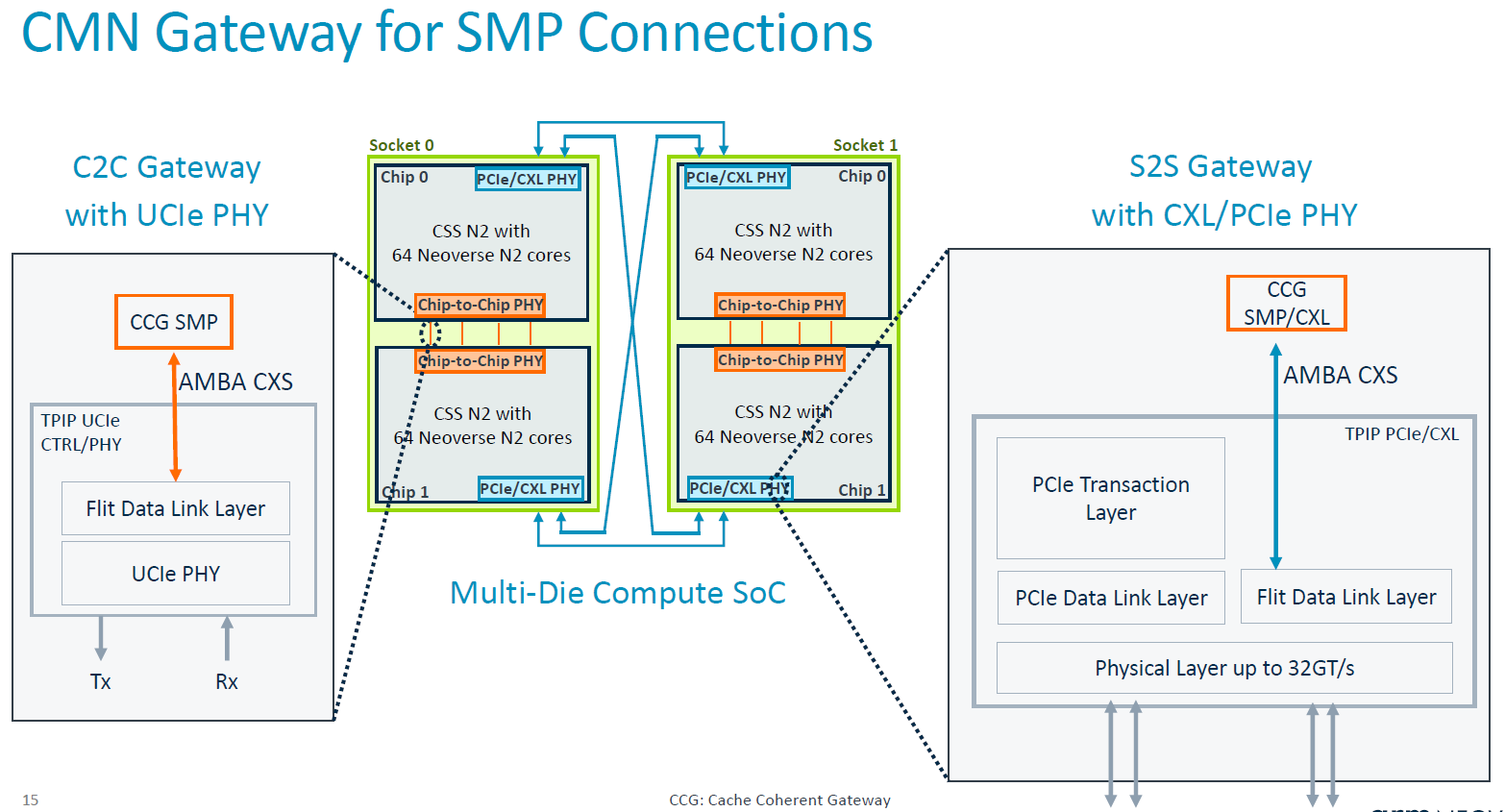
Neoverse CSS N2同時可支援兩顆處理器、最大256顆核心的擴展,而且,在這套運算子系統的設計當中,處理器之間的連結,可運用UCIe或其他合作廠商的實體層技術。基本上,每顆處理器最多可連結128顆核心,兩顆處理器可運用CXL實體層與SMP協定連結,而在這兩種應用案例當中,可透過AMBA CXS協定橋接UCIe/CXL的實體與資料連結層,連入AMBA CHI協定的CMN-700互連交織網路。
在記憶體方面,若導入Neoverse CSS N2設計,用戶可針對每顆晶粒(未經封裝的裸晶片,Die)實作8個40位元的DDR5記憶體通道,以及5600 MT/s的記憶體存取速度;至於I/O的部分, Neoverse CSS N2可支援4條x16 PCIe 5.0/CXL通道,並結合實體層(PHY)與控制器,而且,每一組元件可搭配4向分支,提供4條x4通道。
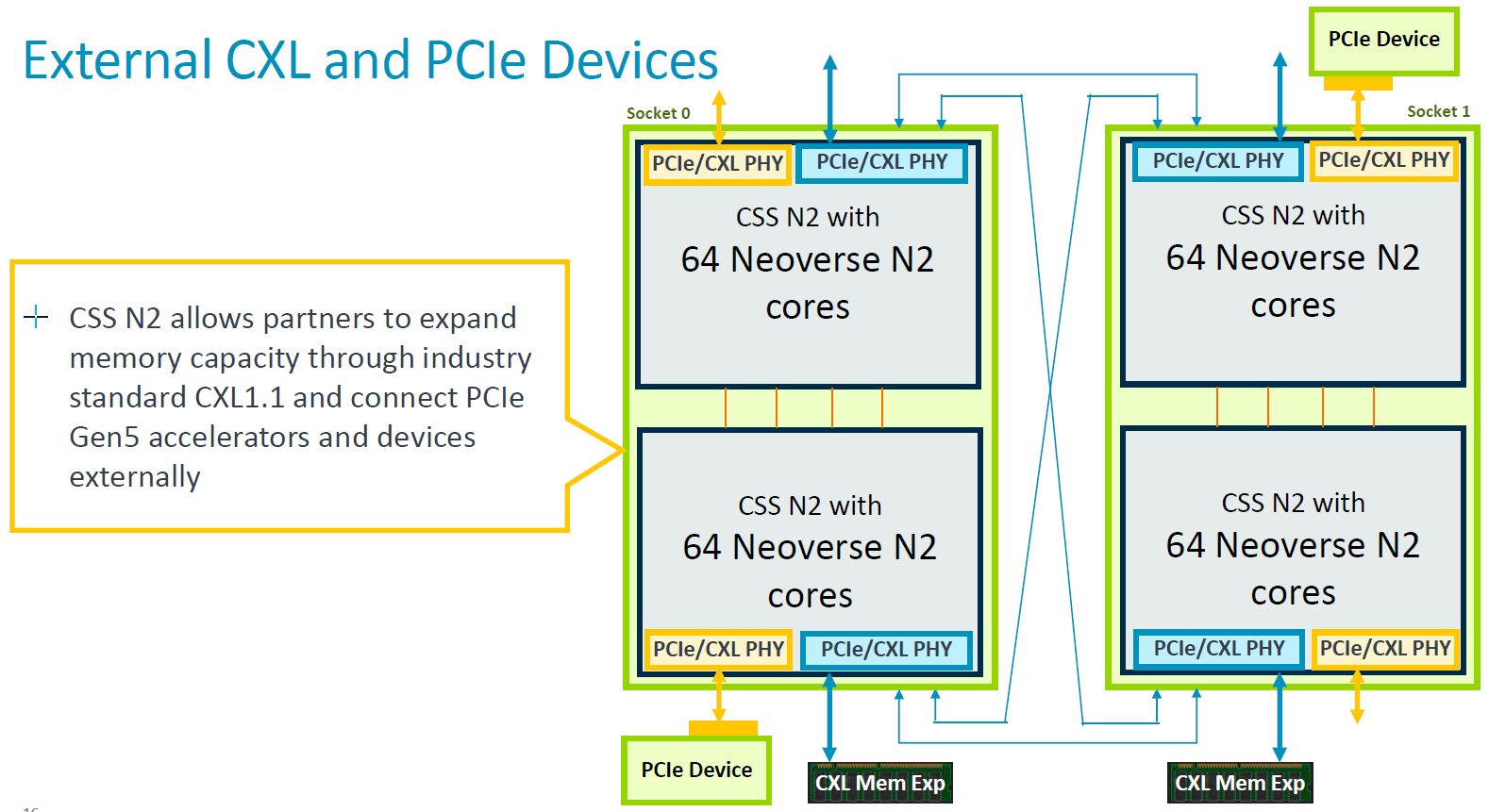
而在連接加速器與外部裝置的能力上,Neoverse CSS N2可選用晶粒層級的內部連接,或以外部方式連接加速器等其他裝置,支援特製型矽晶片與異質運算應用需求。以前者而言,可透過Arm的網路單晶片元件Corelink NI-700互連,藉此獲得中斷處理與位址轉譯支援,對於後者的應用,Neoverse CSS N2提供 PCIe 5.0/CXL1.1實體層技術,可連接GPU、TPU、DPU,以及其他高速存取的裝置,當中也支援CXL Type3連接,可用於記憶體的擴展、資源共用,以及分層存取。
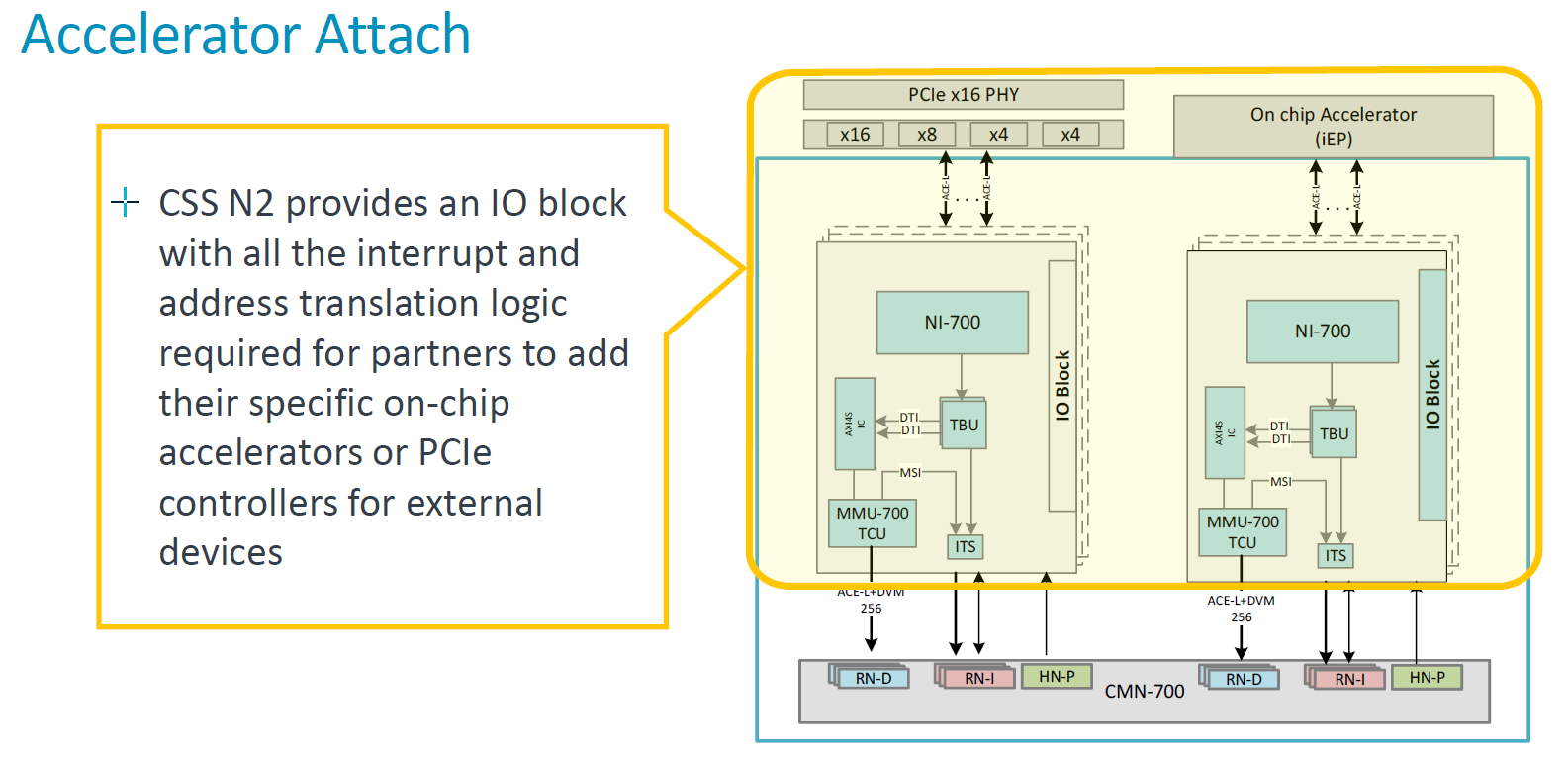
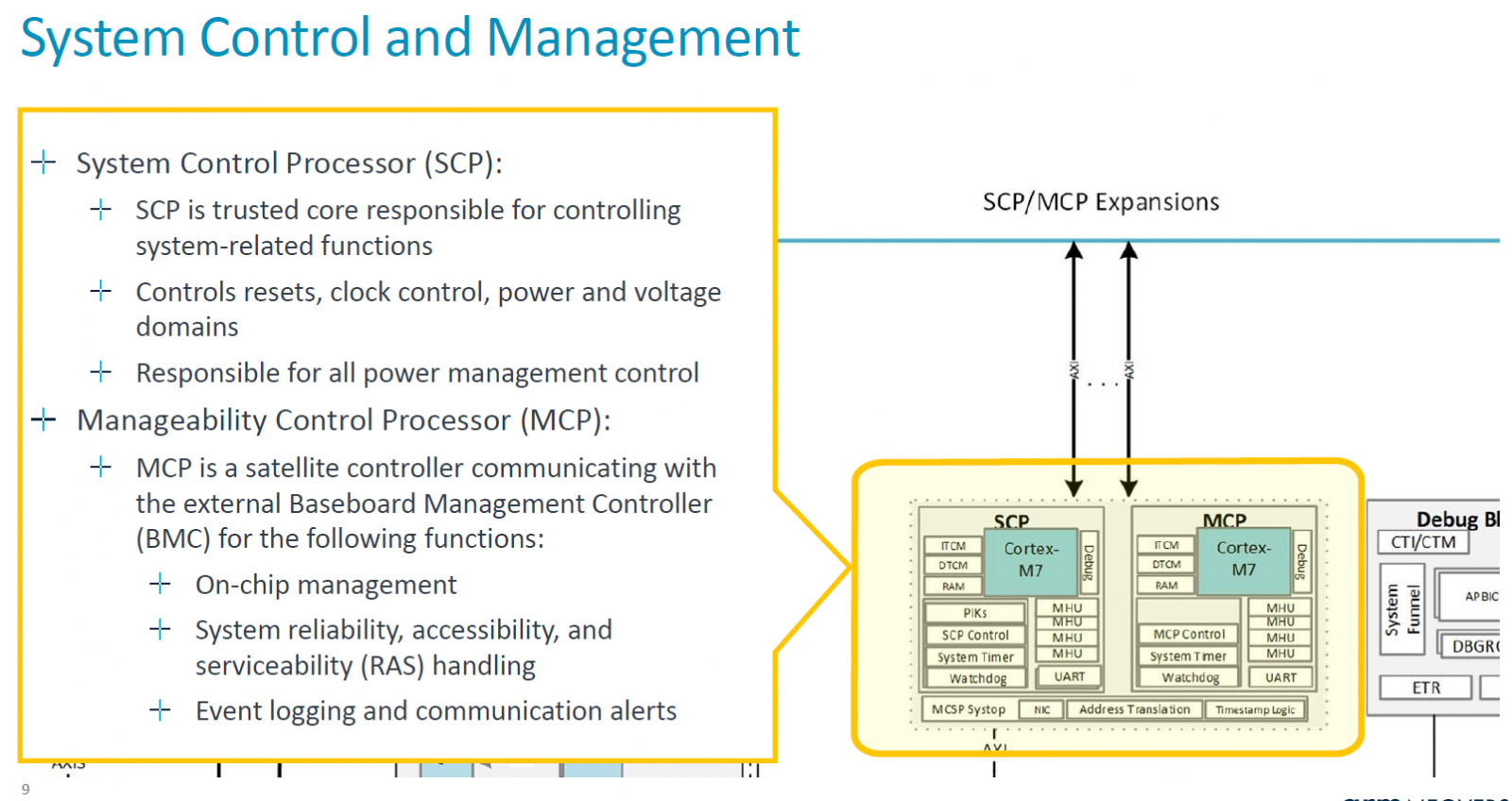
針對特製矽晶片的組建設計,Neoverse CSS N2提供的運算子系統元件,包含系統的控制與管理,而這些工作交由Arm的Cortex-M7處理器擔綱。
例如,Arm在此提供兩種處理器,一是控制系統的處理器(System Control Processor,SCP),透過可信賴的核心去控管所有的系統功能,包含時脈、耗電量、電壓,另一是控制可管理性的處理器(Manageability Control Processor,MCP),負責與CPU之外的基板控制器(BMC)進行溝通,協調晶片的管理、事件記錄、通訊警示,以及可靠度、可用性與可維護性(RAS)。
除了上述規格與元件,Neoverse CSS N2本身的設計也通過Arm的SystemReady SR認證,是專門針對伺服器與工作站而設置的產品認證計畫。基本上,這套運算子系統搭配可供合作廠商參考的韌體堆疊架構,以及虛擬的固定平臺模型,能協助合作廠商快速開發整個運算平臺的韌體、整合作業系統與服務,以及調校系統的開機流程、安全性、電源管理,並在晶片設計定案(taping out)之前完成這些工作。
招攬更多廠商發展採用Neoverse CSS設計的晶片
在2023年10月舉行的OCP全球高峰會期間,Arm為了推廣Neoverse CSS,宣布推出新的生態系計畫,稱為Arm全面設計(Arm Total Design),目的是更廣泛地帶領半導體產業,吸引更多廠商採用Arm提供的運算子系統進行創新,從而提供基於這種設計方式而成的系統單晶片。經由善用Arm的Neoverse平臺,以及源自整個生態系統的Neoverse CSS專屬的知識與技術,有助於合作廠商建立更多量身打造、最佳化解決方案,符合各自獨特的需求與目標,同時,也能增添本身特有的價值與創新,因此能突顯產品的差異。
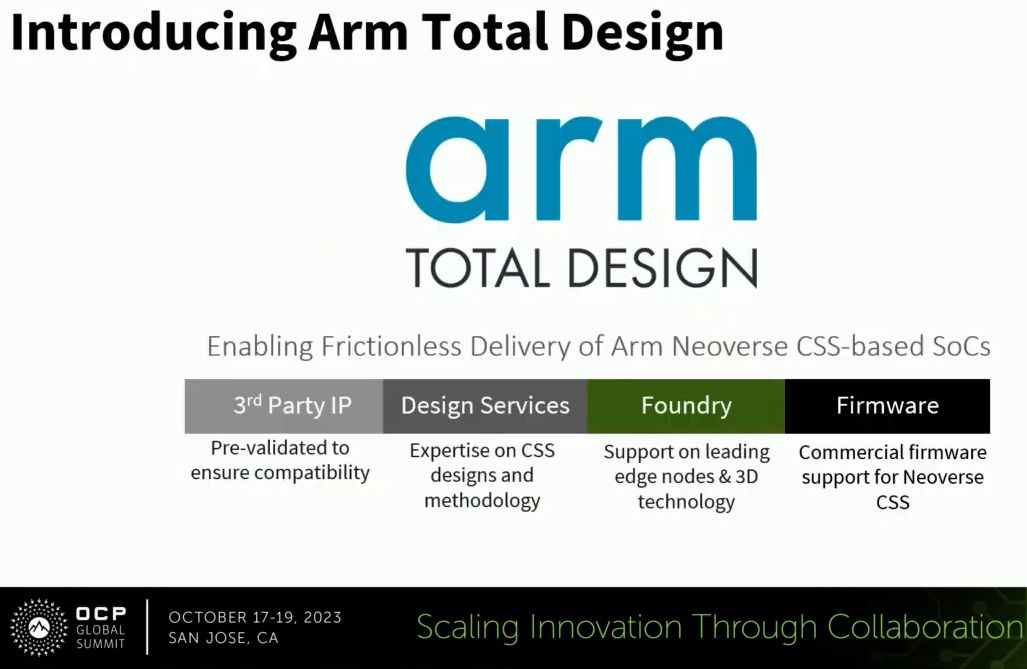
Arm希望透過這種形式團結眾人的力量,涵蓋ASIC設計公司、矽智財供應商、EDA工具廠商、晶圓代工廠商,以及韌體開發者,善用這種類型的簡化設計方式,加速開發採用Neoverse CSS的系統。對於合作廠商而言,運用Neoverse CSS可作為整體設計的起點,隨後可偕同其他合作的專業廠商,促使設計趨於完備,之後,整個產業與市場可以開始堅定、順利地採納新的特製晶片設計。

而對於加入生態系的成員而言,Arm預期他們在自行組建晶片時,可藉此獲得快速推出、降低成本與溝通摩擦等效益。

Arm強調,在Arm全面設計生態系的幫助之下,將大幅提升投入Neoverse CSS所帶來的效益,因為導入這樣的作法,能節省合作廠商整合複雜CPU子系統所耗費的心力。事實上,這個生態系統將會持續擴展配套使用的矽智財、增加設計流程的效率,以及設置更多卓越中心。Arm認為,節省工程人員的時間就是最重要的節省。抑或合作廠商能因此得到更多方法重新投入發展,以便完成更不凡的設計。對於Arm而言,成功關鍵來自橫跨全球的供應鏈,是由各國領先的設計廠商,以及三大晶圓代工廠商合作組成的技術網路,能在Arm生態系統之內,提供尖端的矽晶片設計與最先進的製程節點,以此確保特製晶片能在世界各地供應。
當時,有4種類型、共13家廠商率先響應Arm全面設計。首先,是提供預先整合與已驗證矽智財的廠商,以及EDA工具廠商,例如: 益華電腦(Cadence)、Rambus、新思科技(Synopsys),他們可協助加速矽晶片的設計,以及記憶體、安全性、周邊裝置的整合。

對於矽智財廠商而言,他們可針對Neoverse CSS所用到的技術,預先執行整合、驗證,以及調校的工作;而對於EDA廠商而言,因為這類工具與設計流程完整支援Neoverse CSS,而能促使系統單晶片的設計更為順暢。
第二種是提供設計服務的廠商,像是ADTechnology、Alphawave Semi、博通(Broadcom)、凱捷(Capgemini)、智原科技(Faraday)、索思未來科技(Socionext)、Sondrel,他們可協助整個生態系使用Neoverse CSS,以及Arm其他智財與方法論,這些公司能著手進行設計,而且可以快速供應產品。
第三種是具有先進製程節點與封裝技術的晶圓代工廠商,例如,英特爾晶圓代工服務(Intel Foundry Services),以及台積電(TSMC),可提供最佳化技術,在Neoverse CSS的設計當中,能運用專屬方式進行調校,發揮先進製程的優勢。
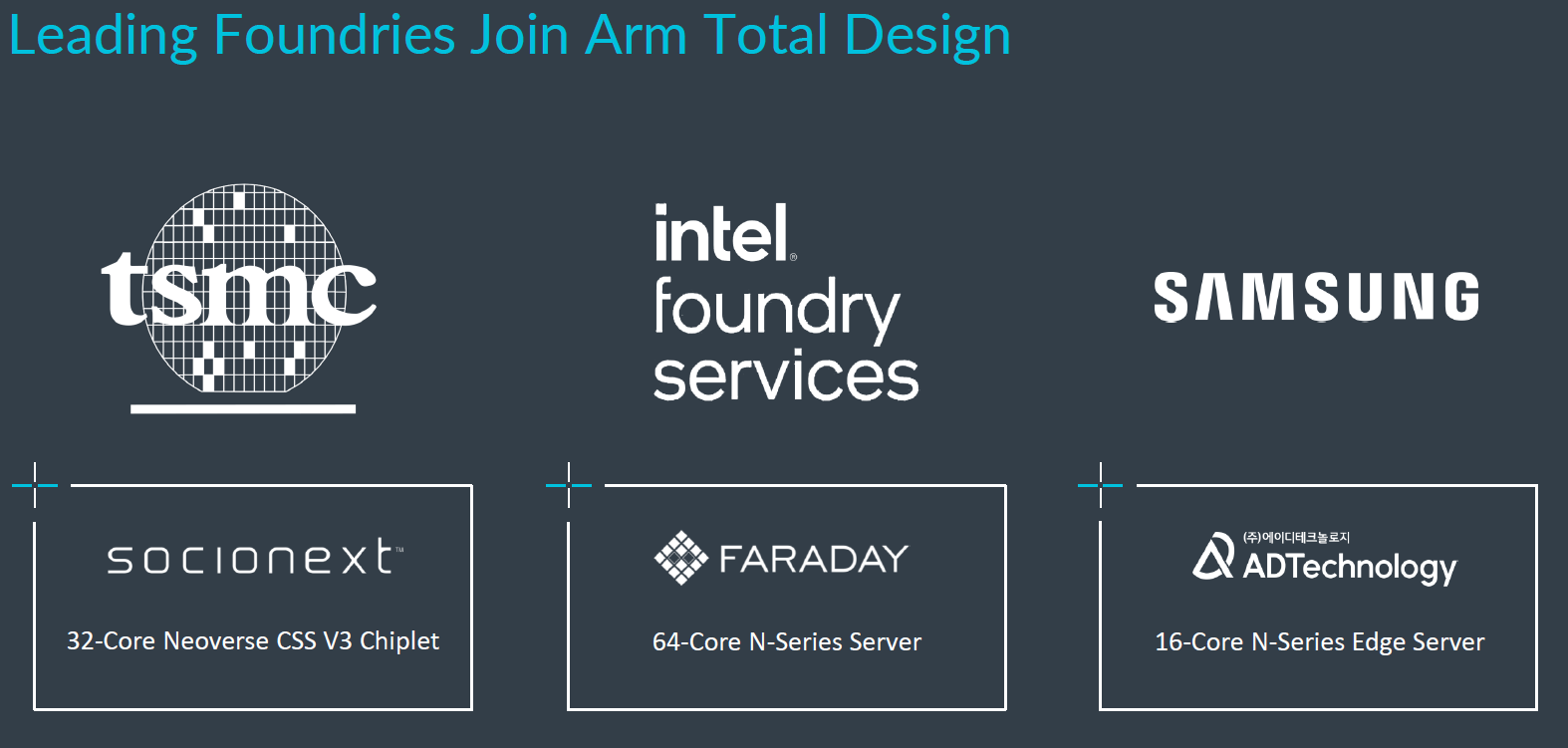
第四種是IT基礎架構韌體廠商,像是安邁科技(AMI),能提供商業化的軟體與韌體支援,因為Neoverse CSS帶來加速開發的效果,因此,在矽晶片推出之前,就能開發出商業韌體解決方案。
今年2月陸續又有9家公司加入Arm全面設計生態系,參與的廠商總數超過20家,範圍橫跨韓國、臺灣、中國、印度。就矽智財與EDA而言,分別是Ceva與Siemens EDA;設計服務方面,有ASICLand、HCLTech;晶圓代工方面,三星(Samsung)將會加入;半導體公司的部分,有雲豹智能(Jaguar Micro)、聯詠科技(Novatek)、瑞昱半導體(RealTek);在進階資料分析的應用上,有proteanTecs加入。

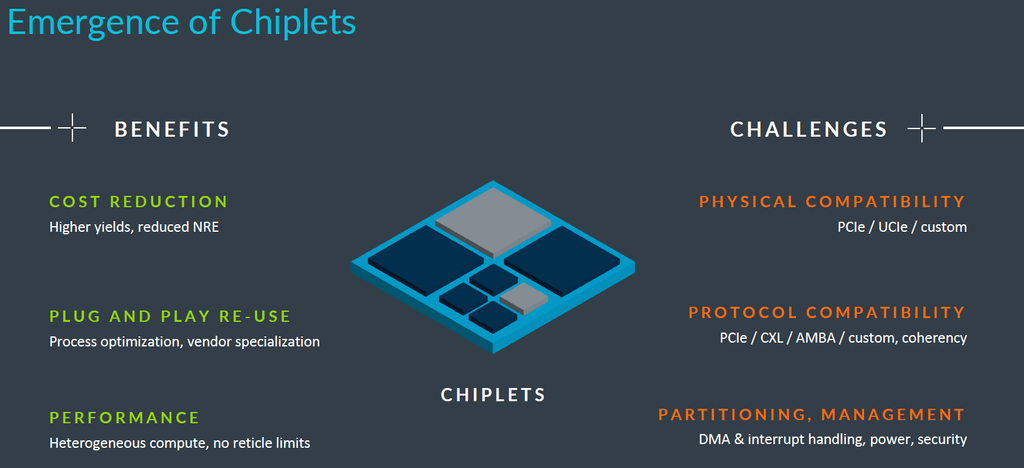
而在這幾年受到矚目的小晶片(經過封裝的小晶片,chiplet)晶片設計技術,Neoverse CSS也提供支援,參加Arm全面設計的成員,以及環繞AMBA CHI C2C、UCIe聯盟,以及其他計畫的生態系統正在進行協同作業,針對整個產業採用的基礎介面與系統架構,Arm將會進行協調與統整,促成多晶粒小晶片 (multi-die chiplet)的系統單晶片設計創新。
而這樣的技術整合模式,Arm預告即將出現多個實際案例。
首先是去年10月索思未來科技宣布相關消息,他們表示,正在發展內建多顆CPU核心的小晶片概念驗證設計,當中採用Arm Neoverse CSS與台積電2奈米製程;到了今年2月下半,Arm揭露新一代Neoverse CSS平臺的同時,提到索思未來科技設計的32顆核心小晶片採用Neoverse CSS V3,而且能結合其他小晶片,以便提供可擴展規模、具成本效益的運算解決方案,鎖定伺服器CPU、資料中心AI邊緣晶片,以及用於5G或6G網路基礎架構的晶片應用。
第二個例子出現在2023年11月底,ADTechnology簽署Arm Neoverse CSS的矽智財授權,可提供他們設計、驗證,並交由三星生產的系統單晶片樣品,支援該公司的基礎架構系統單晶片設計服務;今年2月下半,Arm揭露 ADTechnology期望能在邊緣運算環境提供更大運算能力,同樣透過三星晶圓代工服務的製造,他們將採用16顆Neoverse N系列核心的邊緣伺服器平臺。
第三個例子是智原科技,他們與Arm、英特爾在今年2月4日宣布合作,將導入Arm Neoverse CSS與英特爾18A製程節點,開發基於小晶片而成的伺服器系統單晶片,當中將採用64顆Arm Neoverse N系列核心,鎖定超大型資料中心、網路邊緣,以及5G基礎架構的部署。
發展通用框架與晶片對晶片互連協定,加速推動小晶片設計
2月中,Arm針對小晶片的設計與協同合作,推出兩項新計畫,期盼能提供共通框架,促成新一代的晶片設計者崛起,並且進一步聚焦在更多的協同合作與投資。
首先,是設置小晶片系統架構(Chiplet System Architecture,CSA)。針對採用小晶片的系統,Arm與超過20個合作廠商正在分析與訂定最佳的分割方式,希望能夠開發出一套架構,使多家廠商更能重複使用實體設計智財、軟體智財等元件,而且,這群廠商涵蓋多個市場應用領域,包括手機、車輛、基礎架構,他們想要針對不同類型的小晶片,找出提升系統設計標準化的做法,例如,在橫跨多個小晶片或系統記憶體、信任根等高階屬性的狀態下,針對基於Arm而成的系統,尋求理想的切分方式。

Arm第二項相關的計畫是更新AMBA架構,使小晶片的存取協定能夠成為標準,這會涉及兩個規格:一是2023年5月登場的晶片互連協定AMBA CHI C2C,現在正式公開——透過這項技術,我們可運用既有的晶片層級協定CHI,以及定義轉為封包的方式,而得以在各個(小)晶片之間傳輸;另一是AMBA AXI C2C,Arm承諾提供開放的規格,以便矽晶片廠商能夠採用,而且可以馬上在單一晶片設計獲得好處。
隨著上述兩種標準持續發展,合作廠商面對由多個矽智財區塊組成的單體晶片時,更能將拆分為基於多個小晶片而成的Arm系統,展望未來,Arm預告將針對三大領域推動產業合作。
首先是實體層,例如 UCIe這類業界標準。Arm認為,對於單一封裝的多個小晶片,需要定義資料傳輸的實體協定,像是AMBA、PCIe,以及伴隨多個小晶片而來的系統匯聚共通層面。
第二是協定。Arm期望業界標準PCIe、CXL,以及晶片層級的互連協定AMBA,可促使相關應用市場的發展,將主機板設置多個明確定義的周邊,能夠匯集至單一封裝之內。
第三是高階屬性與分割。對於採用AMBA協定的Arm系統,若能將系統單晶片拆解成多個小晶片的設計,將帶來無窮的彈性,在這部分的發展上,透過CSA架構,Arm生態系統對於採用最有效益的分割方式,可以取得共識,而減少支離破碎的狀況。
Arm第二批運算子系統上場,同時宣告Neoverse邁入第三代
繼2023年8月發表第一代Arm運算子系統Neoverse CSS N2,今年2月接續推出第二批運算子系統,分別是:Neoverse CSS N3、Neoverse CSS V3,同時也揭示Arm Neoverse平臺進入第三代,帶出下一階段主推的邊緣至雲端服務應用的矽智財,會是Neoverse N3、Neoverse V3、Neoverse E3,而在基礎架構系統層級的矽智財,Arm現在提出正式的命名,稱為Neoverse S系列,而在此時推出的產品稱為Neoverse S3。
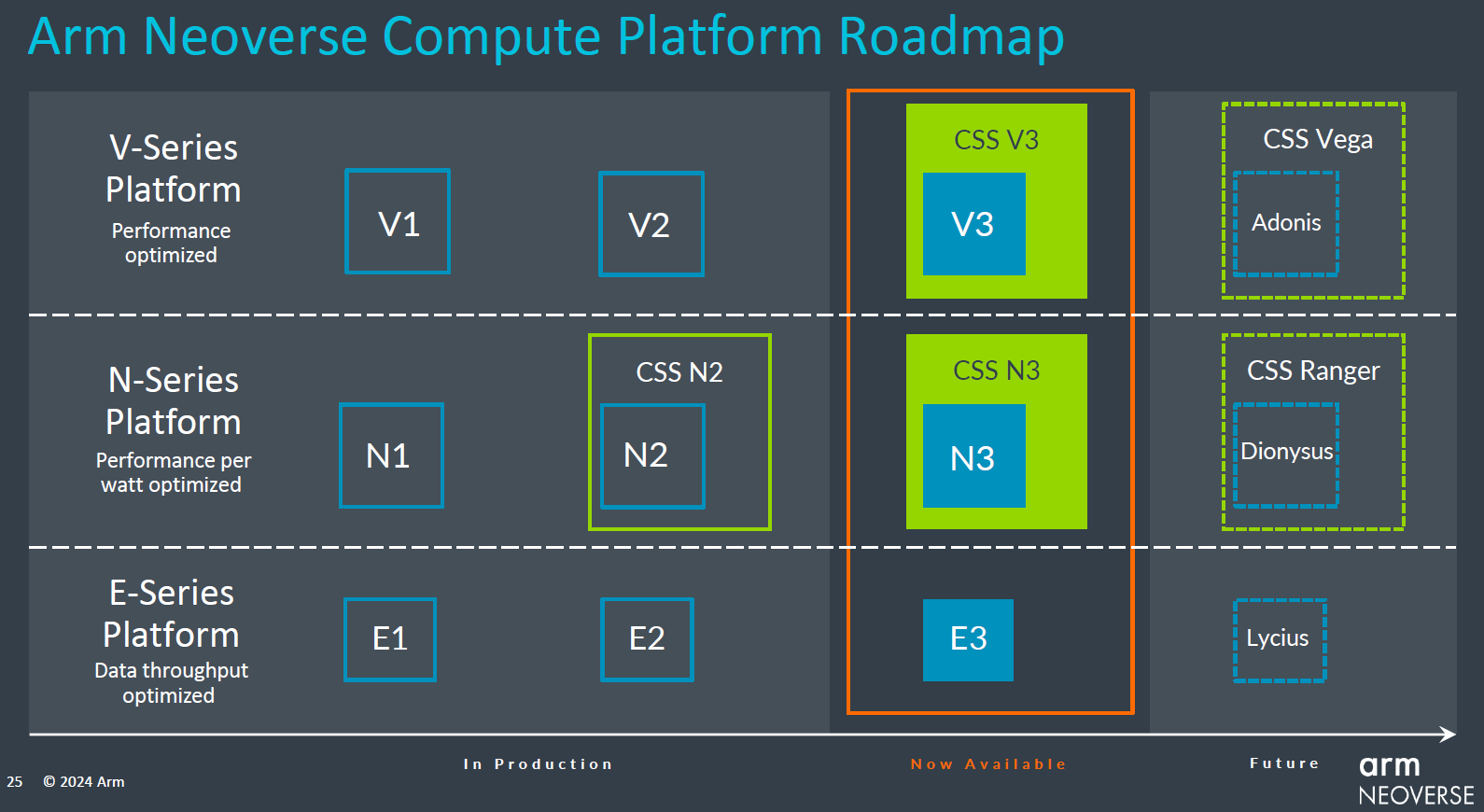
Arm Neoverse平臺的發展今年進入第三個世代,現在不只是針對V系列、N系列、E系列推出新產品V3、N3、E3,去年8月Arm基於Neoverse N2推出運算子系統之後,今年2月宣布推出基於Neoverse N3、Neoverse V3的運算子系統,並預告下一代各系列產品與運算子系統的代號。
以運算子系統的層次來比較,Arm表示,在對應高能源使用成效(performance efficiency)需求的N系列產品線中,Neoverse CSS N3的每瓦效能,超越Neoverse CSS N2的幅度為20%;而在對應提供最強效能(performance-focused或performance-optimized)需求的V系列,Neoverse CSS V3的單顆(插槽)處理器效能,領先Neoverse CSS N2的幅度可達到50%。(可能因為沒有Neoverse CSS V2,所以這裡只能對照Neoverse CSS N2)
Neoverse CSS N3每瓦效能增強2成
顧名思義,Neoverse CSS N3是基於CPU矽智財Neoverse N3,以及系統矽智財Neoverse S3而成的產品。Arm預告採用Neoverse N3、Neoverse CSS N3設計的合作廠商晶片,將於2024年底之後推出。
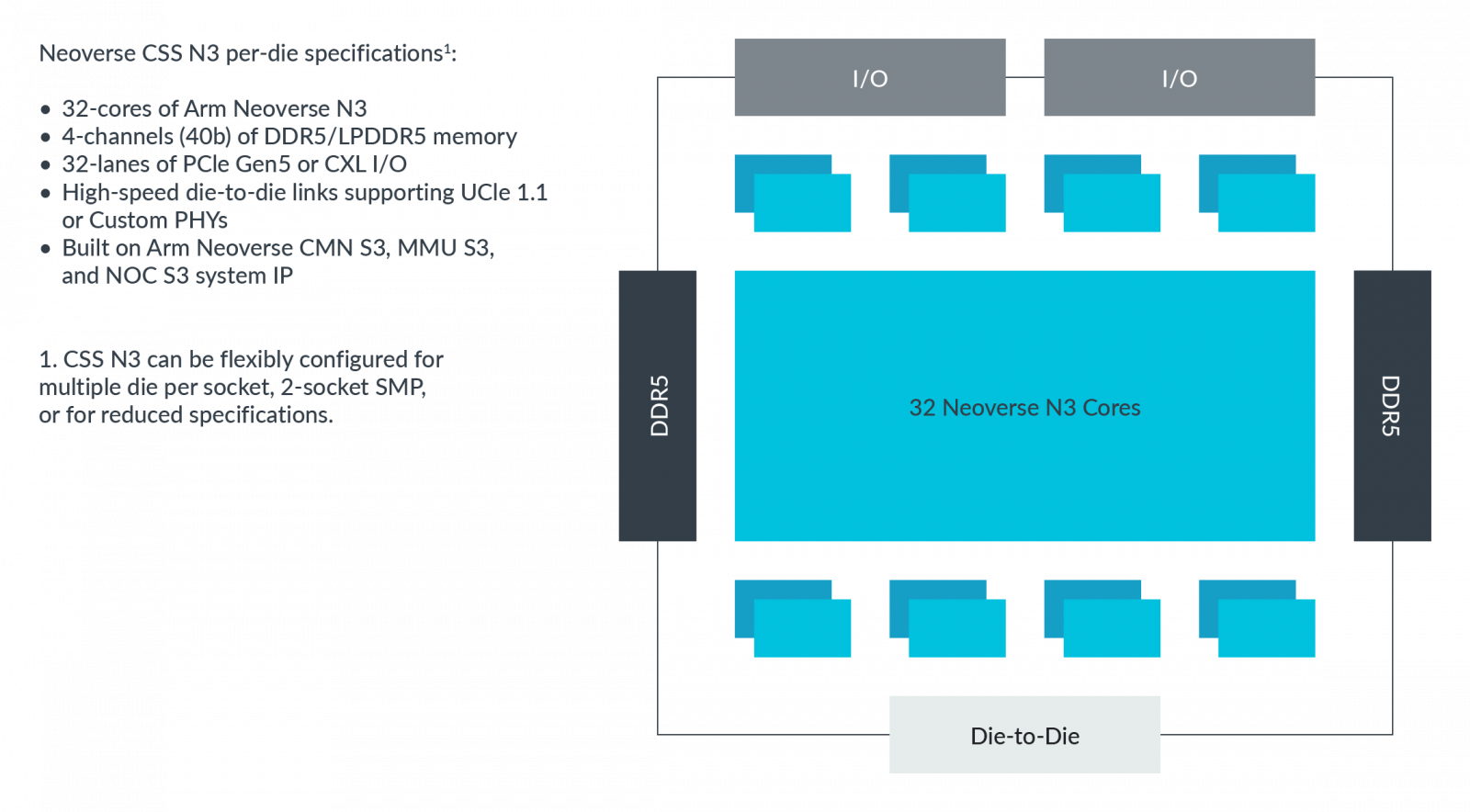
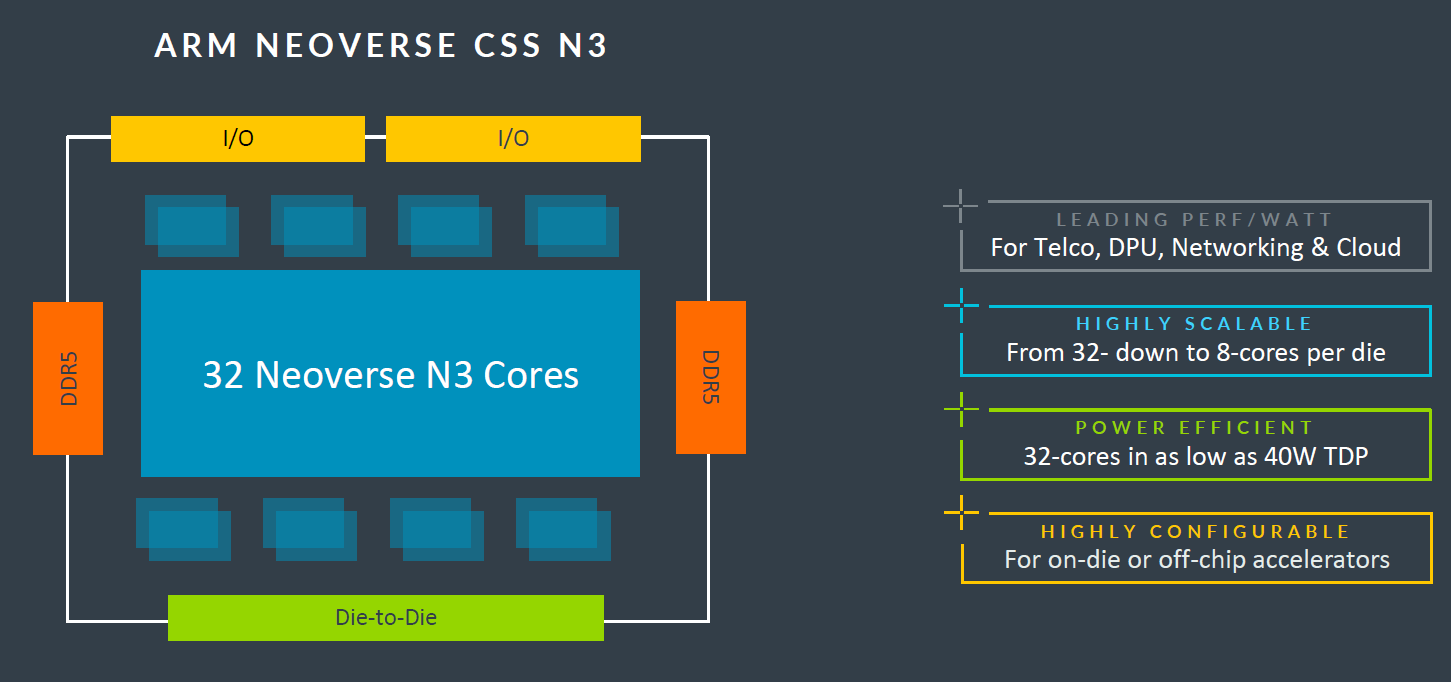
Arm推出主打每瓦效能、具有高能源使用效益的Neoverse CSS N3,可搭配32顆基於Neoverse N3的核心、4個通道存取的DDR5記憶體、32個PCIe 5.0或CXL的I/O通道。
單純檢視Neoverse N3本身,承接Neoverse N2具備的高能源使用成效特性,Arm表示,他們的CPU設計團隊進一步強化分支預測器(branch predictor)、預取器(prefetchers),並調校微架構的運作效率——他們改善電力耗用管理,也增添每顆核心動態電壓與時脈擴展的細部調整機制(per-core DVFS),從而提供更高的能源使用成效,也是Neoverse CSS N3效能之所以比上一代增長20%的主要原因。
在系統單晶片的設計上,Neoverse N3支援多種配置,例如,專攻網路應用的16核心、用於電信無線存取網路(RAN)或雲端環境資料處理器(DPU)的32核心、支援超大型資料中心與雲端服務伺服器CPU的192核心,比起Neoverse N2,能效領先幅度為20%至50%。
若從運算子系統Neoverse CSS N3的角度而言,每顆晶粒可支援8核心至32核心的設計,若希望獲得最大效能,可採用32核心,此時的耗電量僅需40瓦。
關於快取記憶體的配置上,Neoverse N3提供更多彈性,以因應不同運算應用需求。就L2快取而言,Neoverse N3不只與Neoverse N2一樣,提供1MB容量的搭配,支援多種一般用途的運算需求,像是5G/6G無線通訊基礎架構、企業網路、資料處理器、智慧型網卡(SmartNIC)、超大型伺服器系統,也特別新增2 MB容量的選項,支援橫向擴展的雲端資料分析與資料庫應用系統,使其在更靠近CPU核心的位置獲得更寬大的快取暫存空間。
而在L1快取的部分,Neoverse N3最低可設置32 KB、最大128 KB(I-cache為32 KB或64KB,D-cache為32 KB或64KB),能因應對快取容量大小不敏感的工作負載,並且均能將運算的耗電控制在很低的狀態。相較之下,Neoverse N2的L1快取配置,則是I-cache、D-cache皆為64KB。
關於小晶片設計的部分,Neoverse CSS N3支援UCIe 1.1標準,當中搭配Arm新推出的AMBA CHI C2C協定,因此,這套平臺可作為組建異質、加速運算產品的基礎。Arm表示,基於Neoverse CSS N3而成的小晶片,可透過AMBA CHI C2C協定連接IO一致性加速器(IO coherent accelerator),而能在晶片封裝的層級提供更理想的效能與能源使用效率。在此之前,若使用傳統的解決方案——需經由晶片以外的PCIe連接加速器,往往會導致較高的存取延遲、軟體複雜度與耗電量。

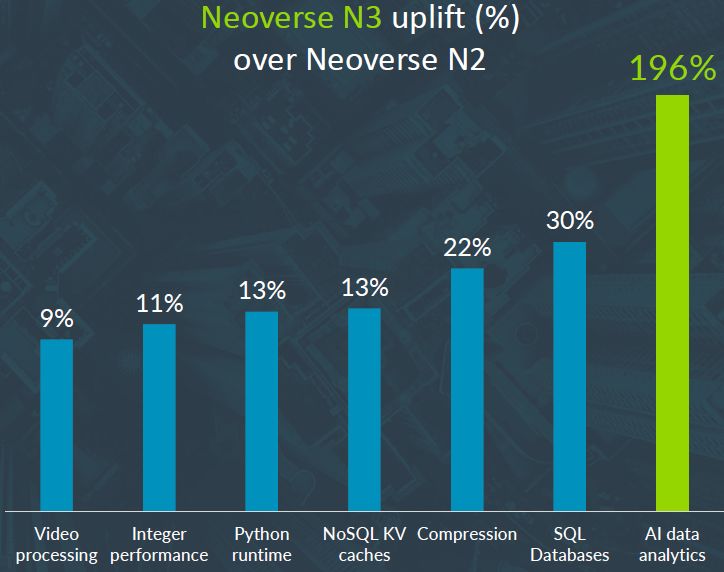
Neoverse N3除了具有更好的能效表現,Arm也揭露此平臺承擔不同應用的效能表現。舉例來說,對比於晶片面積與耗電設置幾乎相同的Neoverse N2與Neoverse N3,設置在相同技術的運算節點設備上,若執行機器學習與資料分析工作負載,新的N3平臺可達到逼近3倍的改善幅度;用在SQL資料庫系統,N3效能提升30%;針對特定壓縮應用,N3效能增加20%;在整數運算處理上,N3效能超越幅度為10%。
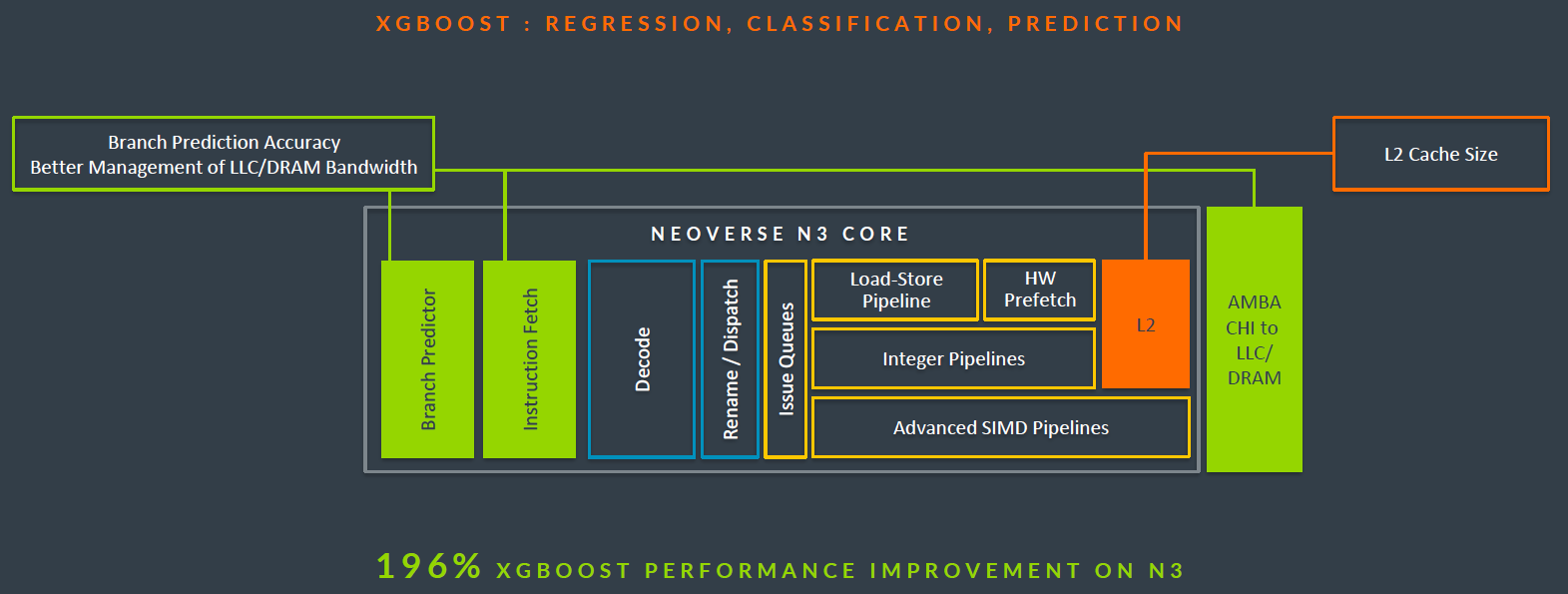
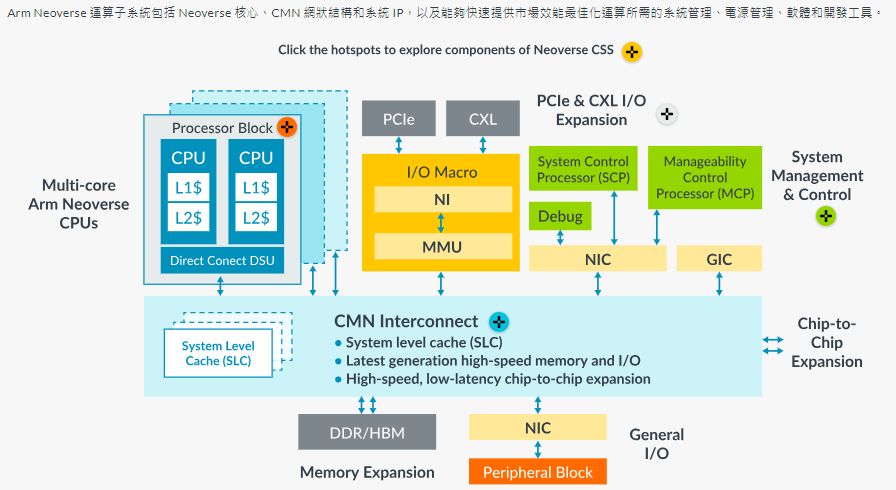
至於系統矽智財方面,Neoverse CSS N3搭配的技術,包括:互連匯流排CMN S3、系統記憶體管理單元MMU S3、網路單晶片NOC S3。此外,Neoverse CSS N3也內建系統管理與本機控制處理器(應該是Neoverse CSS N2推出時提到的SCP與MCP)、以及CPU與系統矽智財的共同設計與開發,進而提供更精良的晶片功耗、性能及面積,以及系統層級的特色。
Neoverse CSS V3單顆處理器效能比Neoverse CSS N2提升50%
Neoverse V系列是鎖定超強運算效能的產品線,而在技術組成的方式上,Neoverse CSS V3同樣是架構在CPU矽智財Neoverse V3、系統矽智財Neoverse S3,以及小晶片互連協定AMBA CHI C2C、耗電量管理技術per-core DVFS等技術之上,值得注意的是,Arm也強調這裡包含他們發展的機密運算架構CCA(Arm Confidential Compute Architecture)。
在Arm網站設立的Neoverse V3專屬說明網頁當中,也特別列出幾項特色標榜其不凡地位。首先,他們表明這是Arm運算速度最快的CPU產品,可支援資料庫、快取、機器學習等多種關鍵工作負載;第二,此平臺可提供大型、可快捷存取的記憶體子系統、高速的晶粒互連,相當適合用於AI加速器的開發;第三,強調Neoverse V3是第一個支援CCA的CPU平臺,可用來建置支援記憶體加密的高安全性雲端服務虛擬機器。
從處理器核心數量配置來看,Neoverse CSS V3支援單插槽與雙插槽,以單顆處理器而言,最多內建128顆,Arm表示,這個運算子系統也能支援較小型的組態,例如32顆核心。而在產品導入的製作技術方面,他們認為Neoverse CSS V3鎖定3奈米等級的製程,之後將提供支援的設計布局與實作流程,期盼能藉此大幅降低實體設計的風險。

若單論Neoverse V3,Arm目前強調兩大特點:硬體平臺的安全性與可靠性,以及總體持有成本(TCO)的最佳化。
這裡提到的安全性,主要是指Neoverse V3可因應大規模的機密運算部署需求,解決當前在多租戶環境、多用途系統面臨的資料安全議題,預防來自內部與外部的資安威脅因素。而所謂的可靠性,是指Neoverse V3將提供頂尖的可靠度、可用性與可維護性機制(RAS),以及遙測(Telemetry)技術,Arm預告將提供分支紀錄緩衝延伸指令集(Branch Record Buffer Extension,BRBE),以便減少IT基礎架構的平均故障間隔時間(MTBF)。

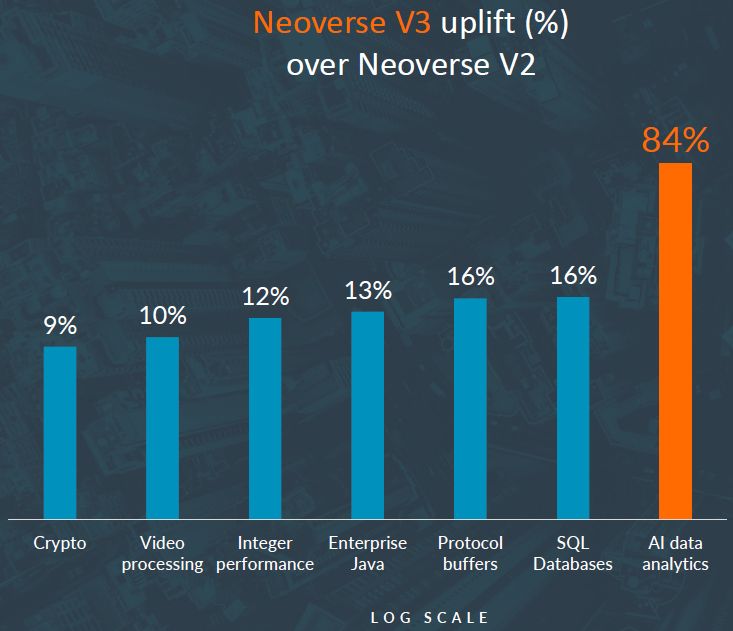
關於TCO的特色,Arm想要標榜Neoverse V3帶來的效能突破。他們列出執行多種工作負載的改善幅度。其中以機器學習最亮眼,相較於Neoverse V2,Neoverse V3的效能領先96%,用於關聯式資料庫管理系統增加16%,密碼學處理提升9%,執行整數運算則是超越12%。
在細部規格的部分,Neoverse CSS V3與Neoverse V3目前揭露的資訊,比起Neoverse CSS N3 與Neoverse N3少,例如內建核心數量,Arm在Neoverse CSS V3網站專頁的圖解寫明為64核心,於技術部落格文章僅提及Neoverse CSS V3最多提供128核心,但在該公司網頁與部落格文章並未交代Neoverse V3的相關規格,若對照上一代Neoverse V2的設計,最多可提供256核心 ,而且,Arm尚未預告Neoverse CSS V3與Neoverse N3上市時間。
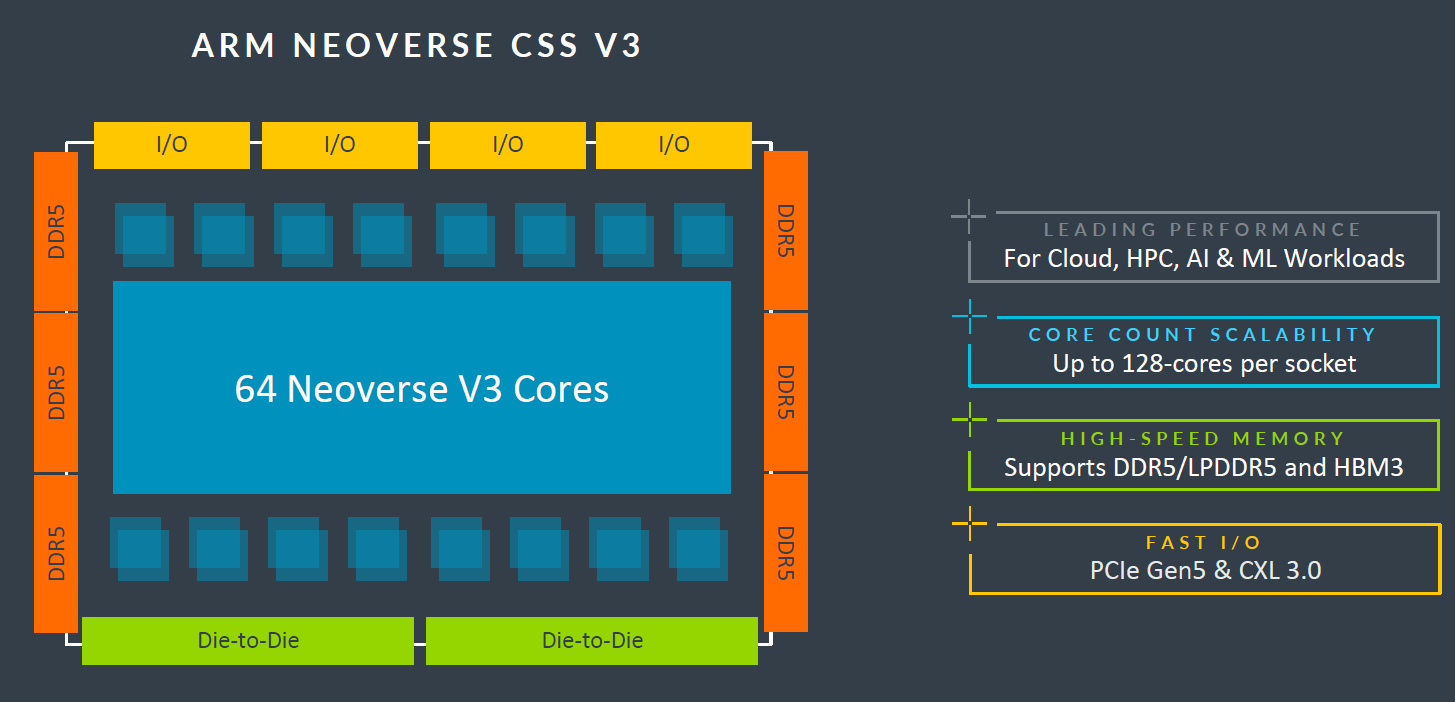
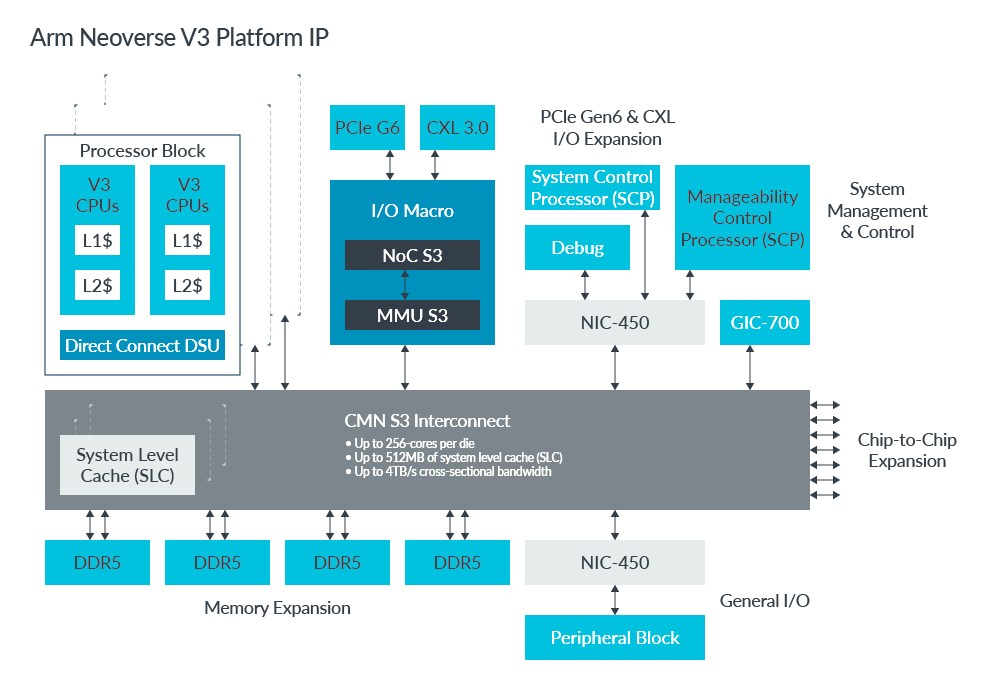
強調可提供高效能的Neoverse CSS V3,搭配64顆基於Neoverse V3的核心、12個通道存取的DDR5記憶體、64個PCIe 5.0或CXL的I/O通道,而且,也囊括可強化資安的Arm機密運算架構(CCA)。
回顧去年8月至今年2月,Arm已陸續推出3款Neoverse CSS平臺,再加上持續擴充Arm全面設計的生態系,集結的廠商數量與類型日漸增加,顯見大家都看好自行設計處理器與加速器的需求,Arm應該也說服合作廠商擁抱、支持這項策略,市面上勢必將會出現更多特製處理器與加速晶片。而對於整個IT業界而言,也正在期待採用Neoverse CSS N2而成的微軟Azure Cobalt,何時進入大量部署、採用階段,以及後續是否有更多廠商公開這方面的產品布局,而率先採用Neoverse CSS N3與Neoverse CSS V3。
熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05