
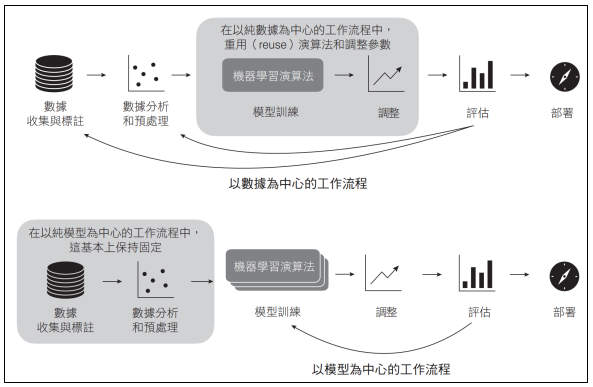
以數據為中心的AI是一種範式(paradigm)或一個工作流程(workflow);在這個範式或工作流程中,我們保持模型的訓練程序固定,並對數據集進行迭代,以提升模型的預測效能。
以數據為中心的 vs. 以模型為中心的AI
雖然以數據為中心的AI(data-centric AI)算是一個相對較新的專有名詞,但它背後的理念並非新鮮事物。我曾與許多人交談過,他們都說,在這個專有名詞被創造出來之前,他們的專案就已經使用以數據為中心的方法了。在我看來,以數據為中心的AI的出現,是為了重新強調「關心數據品質」這件事的重要性,因為數據的收集(collection)和管理(curation)常常被認為是單調乏味或無足輕重的工作。
圖片來源/博碩文化
我們需要在「以數據為中心的AI」和「以模型為中心的AI」之間做選擇?還是可以同時依賴這兩者?簡單來說,「以數據為中心的AI」重點在於「透過更改數據來提升效能」,而「以模型為中心的方法」重點在於「透過修改模型來提升效能」。理想情況下,我們應該在實際的應用場景中使用這兩者,以獲得最佳的預測效能。然而,在研究環境或是在應用專案(applied project)的探索階段中,同時處理過多的變數只會帶來混亂。如果我們同時更改「模型」和「數據」,就很難確定是哪一種變化帶來了改進。
需要強調的是,以數據為中心的AI是一種範式和工作流程,而不是一種特定的技術。因此,以數據為中心的AI隱含地包括了以下內容:
●針對訓練數據的分析和修改,從移除離群值到填補遺漏值
●數據合成(data synthesis)與數據增強技術
●數據標註(data labeling)與標籤清理方法(label-cleaning method)
●在典型的主動學習(active learning)的設定中,模型會建議哪些數據點(data point)需要標籤
如果我們只更改數據(使用這裡列出的方法),而不更改建模管線的其他方面,我們就認為這種方法是以為數據為中心(data centric)的。
在機器學習和人工智慧的領域中,我們經常使用「垃圾進,垃圾出」(garbage in, garbage out)這句話,意思是「品質差的數據」會導致預測模型的效果很差。換句話說,我們不能期望從「低品質的數據集」中得到一個效能良好的模型。
我注意到在應用學術專案中,有一種常見的模式,即研究者試圖使用機器學習來取代現有的方法。通常,研究者只有一小部分數據集(如數百個訓練樣本)。而標註數據(labeling data)通常很昂貴,或被認為很無聊,因此最好避免。在這些情況下,研究者會花費大量時間實驗不同的機器學習算法,並調整模型。為了解決這個問題,投資更多時間或資源來標註更多數據,是非常值得的。
以數據為中心AI的主要優勢在於它把「數據」放到首位,這樣一來,如果我們投入資源建立一個品質更高的數據集,所有的建模方法都將從中受益。
建議
在應用專案中,如果我們希望提升預測效能,來解決某個特定問題,那麼我們通常會採取「以數據為中心」的方法。在這種情況下,從建立模型為基線(baseline)開始,然後改善數據集,這種做法是有意義的;這經常比嘗試使用「更大、更昂貴的模型」還更有價值。
如果我們的任務是開發一種全新的(或者更好的)方法論,例如一種全新的神經網路架構或是損失函數,那麼「以模型為中心」的方法可能是一個更好的選擇。使用一個固定的基準數據集而不去改變它,可以更容易地比較「新的建模方法」和「之前的工作」。增加「模型的大小」通常可以改善效能,但是增加「訓練樣本」也有同樣的效果。對於分類、抽取式問答(extractive question answering)和多項選擇的任務(multiple-choice task)等小型訓練集(< 2k)來說,「增加一百個樣本」可以產生與「增加數十億個參數」相同的效能提升。
在實際專案中,在「以數據為中心」和「以模型為中心」之間切換,是很合理的做法。提前投入資源,提高數據品質,會讓所有的模型受益。一旦擁有高品質的數據集,我們就可以開始專注於模型調整,進一步提升效能。
LLM的評估指標
困惑度、BLEU、ROUGE和BERTScore是自然語言處理中最常用的一些評估指標(evaluation metric),用來評估大型語言模型(LLM)在各種任務中的表現。雖然最終無法超越人類判斷的品質,但人類的評估既繁瑣又昂貴,難以自動化且主觀性很強。因此,我們研發了一些指標,來提供客觀的摘要評分,以測量進步與否,並比較不同的方法。
困惑度指標(perplexity metric)與用於預訓練LLM的損失函數直接相關,並經常用於評估文字生成模型和文字補全模型(text completion model)。從本質上來說,它量化了模型在指定語境中預測下一個字詞的平均不確定性(average uncertainty)──即困惑度越低越好。
雙語評估替換(BiLingual Evaluation Understudy,BLEU)分數,是一個廣泛用於評估機器翻譯品質的指標。它測量的是「機器生成的翻譯」與「一組人工生成的參考翻譯」之間的n-gram(n元)重疊程度。更高的BLEU分數表示效能更好,範圍從0(最差)到1(最好)。
召回率導向的摘要評估(Recall-Oriented Understudy for Gisting Evaluation,ROUGE)分數,是一個主要用於評估自動摘要模型(有時還包括機器翻譯模型)的指標。它評估「生成的摘要」與「參考摘要」之間的重疊程度。
我們可以把困惑度視為內在指標(intrinsic metric),而把BLEU和ROUGE視為外在指標(extrinsic metric)。為了說明這兩類指標之間的區別,請想像一下,我們正在最佳化「傳統的交叉熵」來訓練一個圖像分類器。交叉熵是我們在訓練過程中最佳化的損失函數,但我們的最終目標是最大化分類準確性。由於「分類準確性」不能在訓練過程中直接最佳化,因為它不是可微分的,所以我們要最小化「交叉熵」這樣的替代損失函數。最小化交叉熵損失(cross entropy loss)和最大化分類準確性(classification accuracy)或多或少是相關的。
困惑度經常被用來當作比較「不同語言模型的效能」的評估指標,但在訓練過程中,它並非最佳化的目標。BLEU和ROUGE更接近分類準確性(或者說更接近精確度和召回率)。事實上,BLEU是一種類準確率分數(a precision-like score),用來評估翻譯後的文字品質,而ROUGE則是一種類召回率分數(a recall-like score),用來評估摘要文字。(本文摘錄整理自《機器學習與人工智慧深度問答集》,博碩文化提供)

圖片來源/博碩文化
書名 機器學習與人工智慧深度問答集(Machine Learning Q and AI)
Sebastian Raschka/著;博碩AI編輯室/編譯;劉立民/審校
博碩文化出版
定價:650元

作者簡介
Sebastian Raschka博士是一位對教學懷抱強烈熱忱的機器學習和AI研究者。身為Lightning AI的Lead AI Educator(首席AI教育家),他熱衷於使AI和深度學習變得更加普及,並教導人們如何大規模地利用這些技術。在全力投入Lightning AI之前,Sebastian曾在University of Wisconsin-Madison(威斯康辛大學麥迪遜分校)擔任統計學助理教授,專門研究深度學習和機器學習。你可以造訪他的網站,了解更多他的研究資訊:sebastianraschka.com。
熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05