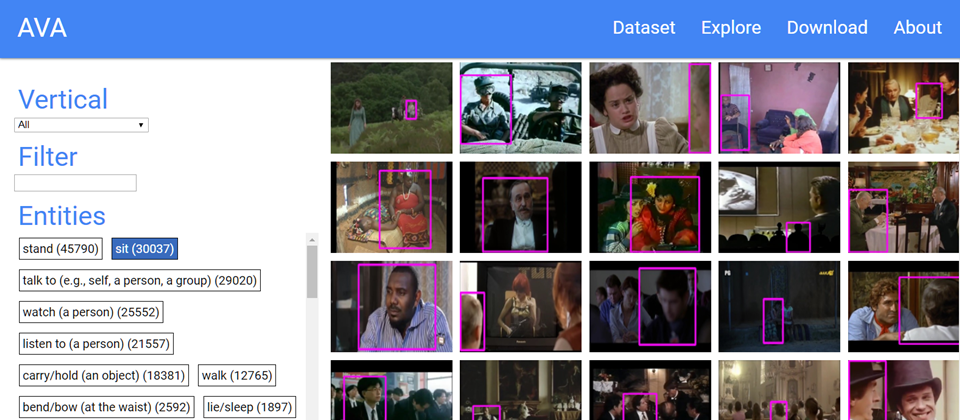
為了加速影像動作識別的研究,Google近日推出人類動作理解資料集AVA(Atomic Visual Actions),提供影片中針對每個人多種動作的標籤,AVA收集YouTube公開的影片,將80個動作標註標籤,包含走、踢、握手等動作,最後AVA資料集分析57,600個影片段,標註了96,000個人類動作,產生210,000個動作標籤。
Google收集不同類型的YouTube影片,主要聚焦在電影和電視類別的影片,擷取還自不同國籍的專業演員動作,將影片每15分鐘切割為一個片段,再將15分鐘的影片切割為300個非重疊的3秒片段,每個採集資料樣本都採取這樣的策略。
接著,Google的研究團隊手動將每個3秒片段的人物,標註邊框,再為每個被標註邊框的人,從預設的80個動作標籤貼上適合的動作標籤,來描述該位人物的動作,這些動作可大致分為3個類別:姿勢或移動動作、人與物體互動動作、人與人互動動作。由於Google對所有人物貼上標籤,因此標籤的機率分布會呈現長尾分布。
在設計AVA資料集時,Google也嘗試了一些特別的作法,舉例來說,Google試著給一群人貼上至少2個動作標籤,就能分析出動作標籤同時發生的模式(Co-occurrence Pattern),像是人類通常在演奏樂器的同時演唱、在與小孩嬉玩耍時將人舉起,或是擁抱同時親吻。
Google在部落格的文章中表示,教導電腦理解人類在影片中的動作,一直是電腦視覺技術還未突破的難題,像是個人影片搜尋、動作分析、手勢操作介面的應用等,儘管過去幾年,圖像中的物件辨識和分類有所突破,但是人類動作的辨識仍然是個挑戰,因為人類的動作是自然的,很難用定義物件的方式來辨識,因次也難創造出人類動作理解的資料集。
許多標準的資料集,例如UCF101、ActivityNet,以及DeepMind的Kinetics,都採用了圖像分類的貼標籤(Label)方法,為資料集中的每一個影片,或是影片的片段,貼上一個標籤,但是還是沒有辦法識別出,不同人產生的不同動作。
Google指出,與其他動作資料集相比會發現,AVA有著3個不同的特質,AVA以人為中心貼標籤(Person-centric annotation)、標籤識別的時間區段,以及採用真實影片。
AVA的分析中,每個動作標籤是以人為主,而不是以影片的片段為主,因此,可以在同一個場景之下,針對多個人、不同的動作來辨識,另外,AVA將動作標籤的識別控制在3秒,3秒是動作可以被清楚識別的時間。
此外,AVA還採用了真實的影片來源,用電影影片當作訓練素材,收集來自不同類型和國家的素材,如此一來,AVA資料集就包含了一般大眾人類的動作。
Google希望藉由釋出AVA資料集,來協助人類動作識別系統的開發,提供更多將複雜動作模型化的可能性,Google將持續改進AVA,也期望開發社群給予回饋,做為未來修改與發展方向的參考。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-06

2026-02-09