
【美國達拉斯現場報導】本週舉行的美國超級電腦大會剛好滿三十周年,Nvidia公司創辦人暨執行長黃仁勳在這場活動期間,以新一代高效能運算(New HPC)為題發表演講,探討他們對於現今HPC應用的最新看法,並介紹該公司今年針對機器學習加速而發展的開放原始碼軟體套件RAPIDS,以及去年發表的雲端加速容器登錄服務NGC(Nvidia GPU Cloud)最新進展,同時,也揭露他們在雲端GPU橫向擴展應用的最新產品Nvidia T4 Cloud GPU。

加速推動資料科學應用,不能單靠深度學習技術,Nvidia重申機器學習的重要性,並且持續擴充雲端容器登錄服務版圖
在加速運算的發展上,Nvidia最著名的是旗下的GPU加速技術,然而他們長期發展的統一運算架構CUDA,也隨著該公司GPU架構的進展而持續推出新版,並且保持各個世代架構的相容,以及針對整個技術堆疊進行全面的最佳化,因此,在高效能運算的應用領域,伺服器也能因為搭配多張GPU加速卡,而獲得大幅領先純CPU伺服器的運算效能。
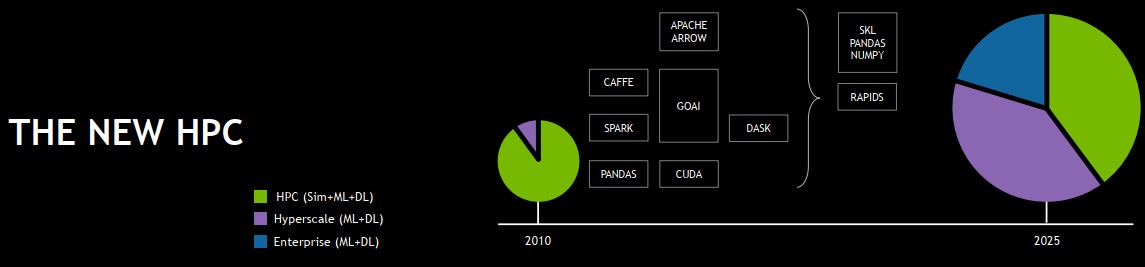
不過,承擔大量高效能運算工作負載的資料中心,現今所需執行的相關應用程式類型越來越繁雜,根據統計,有數百種、甚至數千種之多,而且除了因應高效能運算的各種模擬、機器學習、深度學習,隨著人工智慧的應用崛起,超大規模環境與企業環境的機器學習與深度學習,也將是未來高效能運算技術發展的重點。
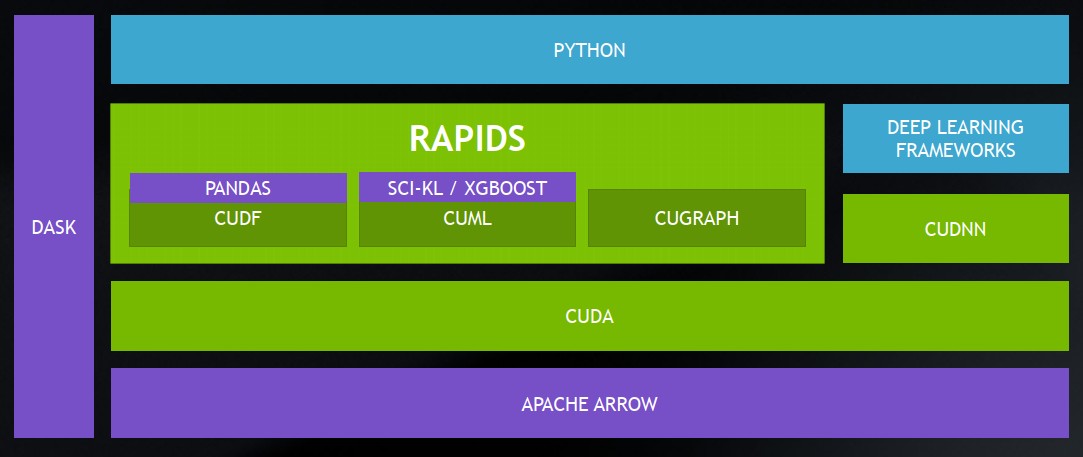
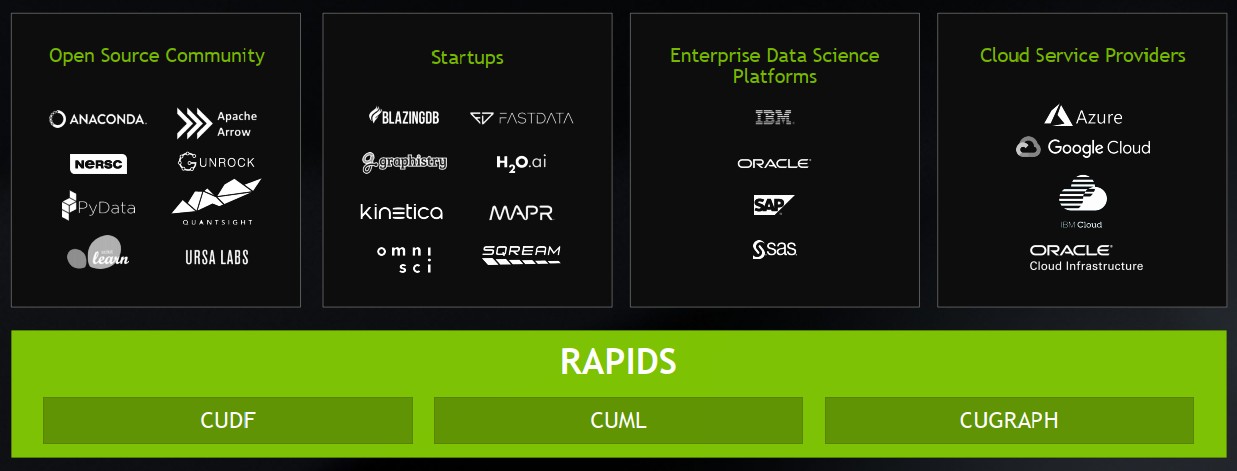
對於這樣的新局面,黃仁勳特別提到他們在GTC歐洲大會宣布推出的開源軟體套餐RAPIDS,希望透過當中整合的程式庫,提供一套支援CUDA加速的資料科學工作流程,目前已有多個開源軟體社群、新創公司、企業級資料科學平臺廠商、雲端服務業者,開始採用。
Nvidia另一個能夠協助資料科學應用開發的資源,則是他們去年發表的雲端容器登錄服務Nvidia GPU Cloud(NGC),在這次超級電腦大會期間,黃仁勳也談到目前這套服務的最新進展,像是:提供新的加速容器映像,以及多節點架構的容器部署,並且支援在高效能運算領域備受關注的容器Singularity;同時,NGC原本訴求的執行環境,主要是公有雲服務,如今也能用於獲得「NGC-Ready」認證的工作站、叢集系統、雲端服務等環境,應用情境更為寬廣。
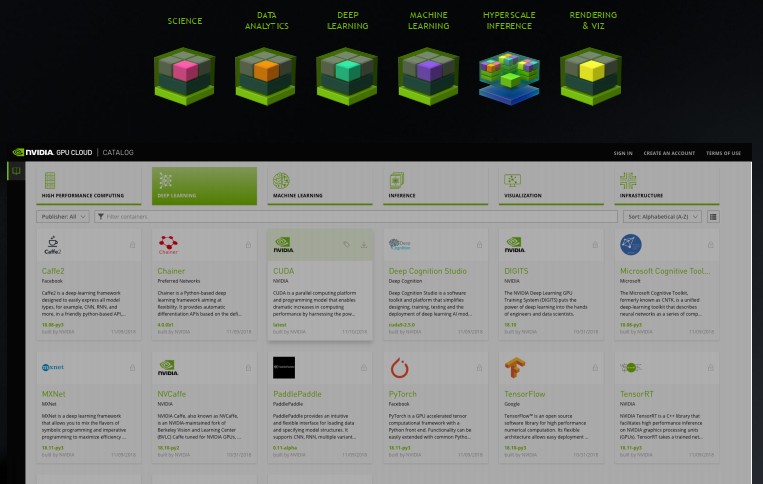
根據Nvidia的新聞稿內容,目前在伺服器的部份,總共有6款機型拿到NGC-Ready認證,分別是ATOS BullSequana X1125、Cisco UCS C480ML、Cray CS Storm NX、Dell EMC PowerEdge C4140、HPE Apollo 6500、Supermicro SYS-4029GP-TVRT;工作站的部份,則有HP Z8、聯想ThinkStation P920;而在雲端服務的部份,原本就有Amazon EC2,後來,Google Cloud Platform、Microsoft Azure、Oracle Cloud Infrastructure等業者,陸續提供支援。當然,還有Nvidia自家的DGX Systems系列整合應用設備,以及特定的Titan與Quadro GPU,也支援NGC。

針對資料中心GPU橫向擴展需求,提供新的加速卡
在資料中心對於GPU的效能擴充作法上,以往大多只能採用縱向擴展(Scale Up)的方式,改用運算效能更強勁的GPU加速卡,或是在單臺伺服器安裝多張GPU加速卡的方式,而在Nvidia今年推出的DGX-2,他們開始展現了一機16張GPU的配置,到了9月舉行的GTC日本大會,他們宣布推出新的GPU加速卡Tesla T4,以及TensorRT Hyperscale Platform,支援超大規模的人工智慧推論應用。
於本週舉行的美國超級電腦大會期間,黃仁勳則是提到可以用這套新型GPU加速卡與橫向擴展(Scale Out)架構,來因應更大量的GPU使用,而根據Nvidia的新聞稿所公布的消息來看,每臺運算節點最多可搭配20張Tesla P4,延展性有重大突破。



熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10