Amazon
Amazon近日發表了最新的文字轉語音系統,透過生成神經網路,經過幾個小時的錄音檔訓練,就能學會新聞播報員的說話風格,這項進展是為了Alexa和其他語音服務鋪路,期望在不同的對話內容,語音服務能用不同的講話風格,增加使用者體驗。
當人類說話時,會根據不同內容採用不同的說話風格,舉例來說,播報新聞頭條的主播和講床邊故事給小孩聽的父母,會用非常不一樣的說話風格,來傳達自己的意思,因此,Amazon認為,對於使用者而言,合成的語音若能夠更像真人,有講話風格的轉換,將能帶給使用者更好的使用體驗。
Amazon開發的神經文字轉語音(Neural text-to-speech, NTTS)方法,利用增加大量現有的新聞廣播錄音檔,系統可以在經過短短幾小時的錄音檔訓練後,建立新聞領域的聲音,過去用連接式合成方法的技術,是不可能達到這樣的成果。
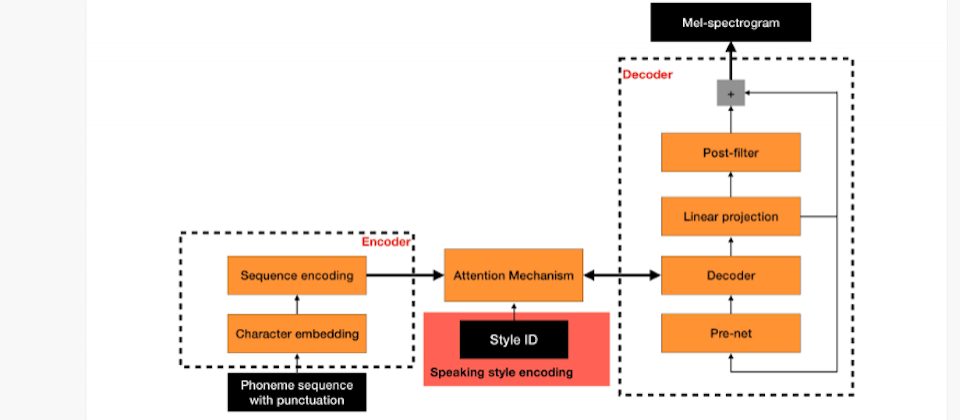
Amazon的NTTS系統包含兩個元件,一個是將音位(phonemes)序列轉換為聲譜序列的神經網路,音位為語言的最基本單位,另外一個元件是將聲譜序列轉換為連續聲音訊號的語音合成器。第一個神經網路是Sequence2sequence的模型,也就是說該模型不僅會根據輸入計算輸出,還會考慮輸出序列的位置,輸出的聲譜是用梅爾聲譜(mel-spectrograms)的方式,透過頻率來強調人腦處理說話的聲音特徵。
不過,當大量資料集訓練用於建立通用的連接式合成時,這種Sequence2sequence的方法可以製造出高品質的聲音,但是,這些數據集缺乏代表特定講話風格的獨特語音特徵,即使產生的語音品質高,卻在多樣化的表達呈現上有所限制,像是音調,停頓和節奏。另一方面,若找來朗讀人員建立相似大小的資料集,需要數十個小時的音檔才能訓練該模型,不但耗時,成本也十分昂貴。
Amazon發現可以透過調整Sequence2sequence的模型,利用大量風格中立的資料來訓練特殊風格語音合成器,Amazon不只用音位序列和梅爾聲譜,來訓練該模型,還用了風格編譯器,來辨識訓練樣本的說話風格,透過這個方法,Amazon就能夠用風格中立的語音資料,在短短的幾小時內,訓練出高品質且多樣化風格的模型。
最後,模型輸出的成果需經過語音合成器,該語音合成器是將梅爾聲譜轉換為聲波形式的神經網路,為了能夠使其成為通用的網路,語音合成器必須能夠模擬任何語音、說話者和說話風格的發音,因此,該系統採用了任何說話者的梅爾聲譜。
熱門新聞

2026-02-11

2026-02-09

2026-02-10
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-06

2026-02-10

2026-02-10

2026-02-10