Google發布用於訓練和評估開放領域(Open-domain)問答系統的大型語料庫Natural Questions,包含了30萬個自然產生的問題,以及來自人工以維基百科頁面註釋的答案。另外,Google還舉辦了挑戰活動,排名挑戰者以Natural Questions資料集訓練的模型效能。
開放領域問答是處理自然語言理解的基準任務,目的是在模擬人類找尋資料、閱讀和理解文件獲得問題解答的方法,像是以自然語言表達提問「天空為什麼是藍色的?」,問答系統被期望可以閱讀諸如維基百科等網頁,回傳正確的答案。
Google提到,目前沒有任何公開大型可用的自然產生問題來源,以及可以用於訓練和評估問答模型的答案,自然產生問題指的是,那些真正想要尋求解答的人所提出的問題。而缺乏這類資料集的原因則是,要匯集用於問答的高品質資料,除了需要有大量真正的問題來源外,還需要花費大量的人力尋找這些問題的答案。
現在Google釋出大型語料庫Natural Questions,以填補這個開放資料的空白,Natural Questions是第一個使用自然產生的查詢資料集,內含經閱讀整個維基百科頁面所得到的答案,並且僅是從簡短段落提取的結果。Google收集自家搜尋引擎真實匿名的查詢,並要求註釋者閱讀整個維基百科頁面尋找答案,註釋者提供兩種答案註釋,除了涵蓋所有資訊的長答案,還有簡潔的短答案。
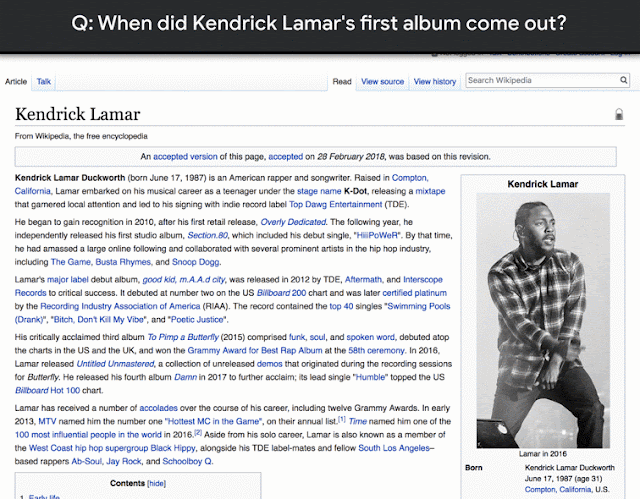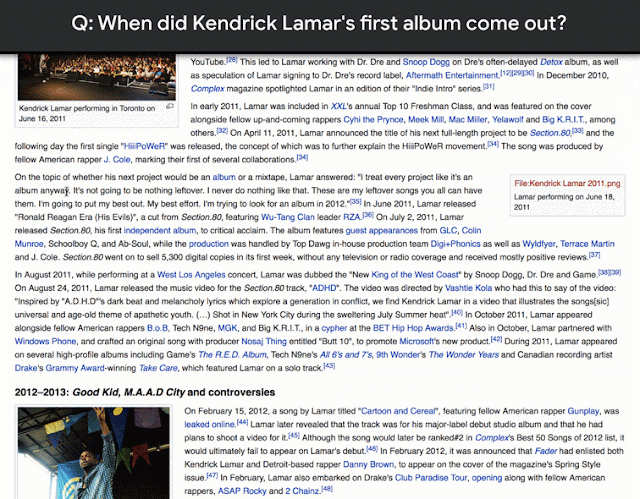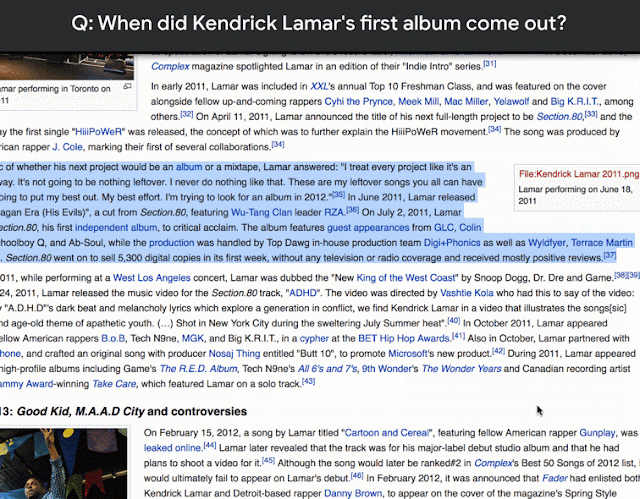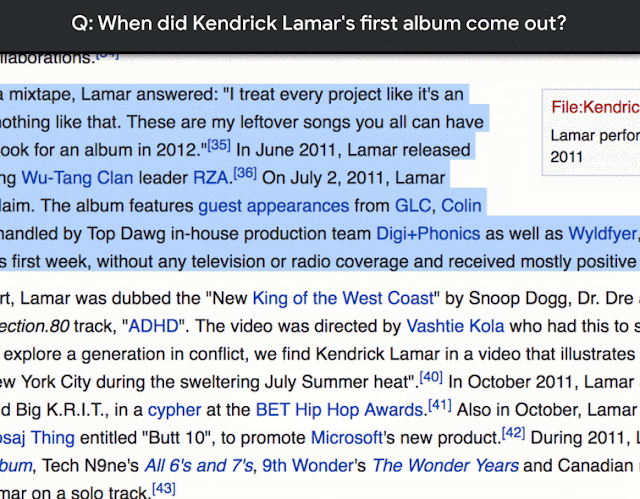
該語料庫收集了30萬個自然產生的問題與答案,而註釋的品質經測量精準度達90%,另外,Natural Questions還包括1.6萬個範例,每個問題的答案由5個不同的註釋者提供,Google表示,這種資料可以用來評估問答系統的效能。
回答Natural Questions的問題,比回答一般瑣碎問題需要更深入的理解能力,因此Google在發布Natural Questions語料庫的同時,還向社群發出戰帖公布了大挑戰,挑戰的內容是讓挑戰者上傳自己訓練的模型,執行7,842個與釋出資料集格式相同的測試資料,網站會公布效能排名分數。Google表示,挑戰的目的是希望社群能基於Natural Questions資料,提升進階自然語言理解技術的成熟度。
Google提示了挑戰可能遇到的困難,Natural Questions的目標,是要讓問答系統能夠閱讀和理解整篇維基百科的文章,並回答問題。因此系統需要先定義答案是否可回答,Google提到,這相當重要,因為許多問題本身就是錯誤的假設或者過於含糊,無法簡單扼要的回答。
下一步,系統還需要確定維基百科頁面,是否存在任何可以用來推理答案的段落,文章可能根本不包含問題的答案。Google認為,從文章中找到推理答案需要的所有訊息的長答案辨識任務,比起在長答案中尋找短答案,還需要更深層次的語言理解。
Google希望在發布Natural Questions以及挑戰後,能推動更強大的問答系統開發。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06