Google AI研究團隊發布用於自動語音辨識的資料增強新方法SpecAugment,該新方法是將語音資料增強視為視覺的問題,而不是語音的問題,因此,Google並不用傳統資料增強的方式,針對語音音波輸入資料增強,SpecAugment是直接對聲學音譜圖(spectrogram)輸入資料進行增強,Google指出,這個方法是個簡單又便宜的方法,此外,也不需要額外的資料,同時還能有效地改善自動語音辨識模型的效能。
自動語音辨識是將語音輸入轉為文字的過程,也因為深度神經網路的進展,語音辨識技術應用在許多現代設備和產品中,像是Google語音助理、Google Home智慧音響和YouTube,但是在開發以深度學習為基礎的語音辨識系統時,還是有許多重要的挑戰要解決,其中一項含有很多參數的語音辨識模型挑戰,就是會有訓練資料過度學習(overfit)的問題,若訓練資料集不夠廣泛,模型很難處理未識別過的資料。
在缺乏足夠訓練樣本的情況下,可以透過資料增強的方法,來增加有效訓練資料,這個方法有助於大幅提升圖像分類領域的深度網路表現,一般來說,在語音辨識的案例中,資料增強的方式是靠著改變聲音音波,像是加快、減緩語音速度,或是加入背景噪音,來使得資料集有效地變大,讓神經網路模型學習更多相關特徵,來幫助模型變得更穩固、準確,不過,現有增強語音資料的傳統方法會帶來更多的運算成本,有時候還需要更多額外的資料。
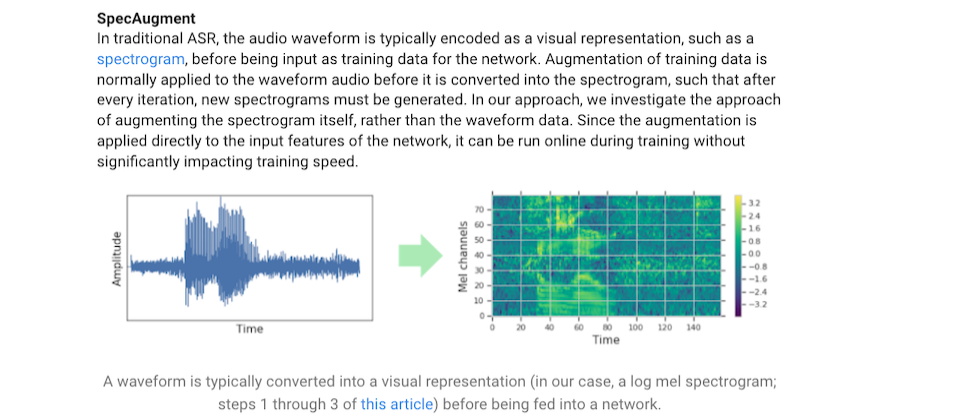
傳統的自動語音辨識模型,在將資料輸入網路模型之前,通常會將音波編譯為視覺的代表值,像是聲學音譜圖,而訓練資料增強工作通常是在音波轉換為音譜圖之前,但是,Google團隊是直接針對音譜圖的資料進行增強,並不是用音波資料,且因為SpecAugment方法是直接針對模型輸入資料的特徵進行增強,因此,可以在訓練的過程中在線上執行,並不會顯著地影響訓練速度。
SpecAugment是在時間方向上,利用改變音譜圖的方式來修改、屏蔽連續頻率通道的區塊和時間內的語句區塊,這些增強工作能夠幫神經網路模型,在時間方向上的分解、部分頻率資訊遺失和小片段語音輸入的遺失等過程,變得更加穩固。
為了測試SpecAugment方法,Google用語音資料集LibriSpeech來進行一些實驗,再透過語音辨識評估標準Word Error Rate(WER),比對模型生成的文字與目標文字的差異,實驗執行的過程中,Google將所有的超參數固定,只有改變輸入網路模型的資料,結果顯示SpecAugment方法能夠改善網路的效能,且不需要額外調整模型或是訓練參數。
更重要的是,SpecAugment能夠防止模型因為給予模型特定訓練資料,而產生過度學習的問題,此外,用SpecAugment方法訓練出來的模型,意外地超越先前所有方法的結果,甚至不需要語言模型的協助,語言模型在改善自動語音辨識網路中,扮演重要的角色,但是通常語言模型和自動語音辨識模型是分開訓練的,且語言模型因為需要大量記憶體,很難應用在小的裝置中,像是手機,因此,該研究結果能夠實際運用在訓練模型中,並且不需要語言模型的協助。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10