
微軟發表FastSpeech模型,可加速仿真語音的生成,透過長度調節器來解決音素與梅爾頻譜生成的時間差。
微軟
重點新聞(1213~1219)
微軟 FastSpeech 語音合成
不只快還不漏字!微軟發表FastSpeech模型能加速仿真人語音生成
微軟日前發表一套仿真人語音生成AI模型FastSpeech,要來解決神經語音合成速度緩慢的困境。微軟指出,現今仿真人的神經語音合成技術,包括Google Assistant、Alexa和AWS Polly所採用的技術,多半是先根據文本產生一個梅爾頻譜,再用聲碼器(Vocoder)來合成語音,但它們都有同樣的缺點,也就是要產生梅爾頻譜的推論速度緩慢,而且合成的語音容易重複或跳過某些單字。
為解決這些問題,微軟聯合浙江大學共同開發出FastSpeech,透過其中的長度調節器,來調整梅爾頻譜和音素(Phonemes)序列的時間長度。進一步來說,音素通常比梅爾頻譜要短,一個音素會對應到好幾個梅爾頻譜,而調節器可拉長音素的時間,讓兩者一樣,使語音產生的速度恰到好處。而調節器之所以能準確調整時間長度,還有賴於FastSpeech的長度預測器。它由1個線性層和2個卷積層組成,專門來預測音素應持續多久。
微軟指出,就實驗成果看來,FastSpeech不僅在合成語音的速度上,比現有的基準模型快上38倍,而且產生梅爾頻譜的速度,更快上270倍。此外,它還可以減少語音合成常見的錯誤,像是跳過單字,而且還能進行速度和斷字微調。未來,微軟計畫將FastSpeech與聲碼器整合為同一個模型,要打造端到端文字轉語音服務。(詳全文)

Google 自然語言 AutoML
Google正式推出AutoML Natural Language,新增PDF判讀功能
經過幾個月測試,Google日前終於正式發布AutoML Natural Language,全球用戶皆可使用。這次GA版除了有常見的機器學習分類、情緒分析、命名實體識別等功能,還新增了PDF檔的語意判讀功能,可讀取PDF原生檔案和PDF掃描檔。
此外,為了強化複雜的語意理解應用,比如理解法律文件或是大型複雜的文件分類,AutoML Natural Language現可支援5,000個分類標籤,也能支援更大量的訓練資料,數量最高可達1百萬筆文件,單一檔案則可達10MB。另一方面,AutoML也加強了命名實體識別功能,可分析其他上下文資訊,比如文件的空間結構、版面配置資訊等,來加強模型訓練和預測結果,特別是發票、收據、履歷和合約等類文件的辨識。(詳全文)
Nvidia 深度學習 TensorRT
鎖定即時推論需求,Nvidia發表新一代深度學習推論軟體TensorRT 7
瞄準即時AI推論需求,Nvidia在自家技術年會GCT China上揭露最新一代高效能深度學習推論軟體開發套件(SDK)TensorRT 7,大幅優化了編譯器,來改善即時推論的工作負載。
Nvidia表示,這個優化的編譯器,可自動加速迴歸和Transformer模型的運算,像是熱門的語音合成模型WaveRNN、Google的Tacotron 2和BERT等,而且與傳統處理器相比,速度可快上10倍以上,延遲低於300毫秒。TensorRT 7將免費開放給Nvidia開發者專案會員,而最新的外掛、分析器、樣本等都會發布在TensorRT的GitHub儲存庫。(詳全文)
紐約大學 FastMRI 資料集
臉書和紐約大學聯手釋出超大型腦部MRI資料集
臉書與紐約大學醫學院合作的FastMRI研究計畫,日前釋出最新的MRI資料集,而且一併開放基準模型和新增的研究論文,來推動AI醫療影像的研究發展。這次釋出的MRI資料集,包含了6,970個完全去識別化的腦部MRI病例k-space原始檔,以及10,000多個病例,裡面共有370,000張DICOM格式的圖像切片。這個資料集,可說是目前最大的k-space格式腦部MRI公開資料集。
k-space格式資料是MRI掃描過程產生的,通常在合成圖像後就不再使用,但臉書指出,k-space格式資料可用來訓練AI模型、驗證效能等。在資料隱私上,臉書強調,該資料集經紐約大學Langone Health委員會審查,完全不含可用來識別病患身份的元資料與內容。目前,研究人員可在NYU Langone Health的FastMRI網站,下載新釋出的大腦MRI資料集、論文和基準模型。(詳全文)

萊迪思 FPGA 動態調整
萊迪思28奈米全新嵌入式FPGA產品亮相,加入動態調整設計對應不同場景
美國老牌FPGA廠商萊迪思(Lattice)近日推出首款28奈米嵌入式FPGA產品CrossLink-NX,不只尺寸更小、更省電,還加入AI處理執行能力,並具動態調整設計的能力。CrossLink-NX是萊迪思第一款採28奈米Lattice Nexus平臺開發推出的FPGA產品。
由於採用28奈米FD-SOI新製程技術開發,在FPGA設計上,使用彈性便大幅提升,可對應不同應用場景,動態調整邏輯電路,來降低硬體成本。例如,假設要在沒有加裝電池的IoT裝置上使用,可選擇低功耗的FPGA模式,但若需要執行更高算力的AI推論時,就可切換到高效能處理模式,讓同一顆FPGA晶片可在這2個不同應用場景上執行。(詳全文)
北市聯醫 工研院 遠距照護
負傷不便遠行就醫有解法!北市聯醫聯手工研院開發遠距傷口照護App
臺北市立聯合醫院聯手工研院,耗時一年打造一款遠距傷口照護App,由護理人員攜帶智慧型手機與熱感影像感應器,至偏遠地區、行動不便的重症病患家中,來拍攝傷口照片,再透過雲端系統分辨上皮、肉芽、焦痂、浸潤、腐肉等5種傷口狀態,並計算傷口面積、傷口壞死情形、是否浸潤和發炎等。在遠端的醫生,可藉這套系統來診斷,讓不便遠行就醫的患者或長輩,在家也能接受傷口照護服務。
進一步來說,在拍照方面,醫護人員可先透過熱感影像儀,拍下傷口照片,透過不同溫度而呈現的不同顏色分布,來判斷傷口周圍皮膚是否有發炎現象。再來,透過工研院自建的傷口大小判讀AI模型,只要用手機拍下傷口與對照物的照片,或是利用熱感影像的紅外線測距,就能自動計算傷口的長與寬,未來,工研院還要開發出能計算傷口深度的AI模型,來給醫生更多治療的參考資訊。(詳全文)
.JPG)
Google 機器學習 公平性
Google推出機器學習公平性量測工具,要來降低模型偏差
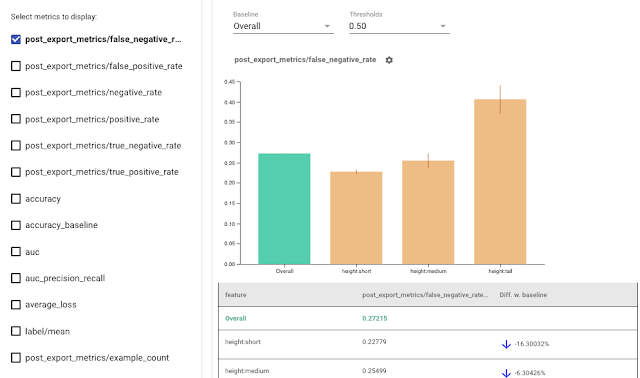
Google發布AI公平性量測工具Fairness Indicators測試版,可針對二元和多類別分類進行運算與視覺化,幫助開發團隊評估、修正模型的偏差。進一步來說,這個工具可針對誤報率等常用的分類模型公平性指標來評估,還能計算信賴區間、評估多個閾值。在使用者介面上,使用者可以切換基準群組並調查不同指標的效能,也可為自己的使用案例,增加自定義的視覺化指標,也可用來產生透明性報告指標,幫助開發人員調校模型。
Google表示,公平性的顧慮與評估會因為案例而不同,因此Fairness Indicators工具還包含了一個互動式研究案例,提供Jigsaw毒性資料產生的意外偏差,說明檢測和修補機器學習模型偏差的方法。(詳全文)
保險 保單健診系統 自然語言處理
2周縮短成10分鐘!錠嵂啟用新AI保單健診系統
瞄準製作保單健診事倍功半的痛點,錠嵂保經宣布啟用AI保單健診系統,保險業務只需用手機拍下保戶的舊有保單,上傳至雲端平臺後,系統就能在幾分鐘內,自動產生保戶的保單健診報告,包括現有的保單明細、保障額度、不同險種的保障分析等。
這套系統利用OCR來辨識保單上的文字,要是有些因紙張皺褶、光線變化而難以辨識,就可透過NLP來理解上下文,推測出正確的字詞。此外,系統也與一套險專業知識資料庫整合,涵蓋2萬3千多條險種文件資料,幾乎涵蓋全臺灣的保險商品種類,來供系統精準判斷險種。目前AI系統已上線,供全臺2千多名業務人員使用。未來,錠嵂保經計畫開放這套系統,讓自家保戶可上網自行分析,提高保險透明度。(詳全文)
攝影/王若樸
圖片來源/Google、臉書、微軟
AI趨勢近期新聞
1. 鎖定高解析串流分析,清大開源CNN架構HarDNet,影像分類速度比常見ResNet-50架構快30%
2. Amazon向企業用戶推出Alexa知識技能,提供無程式碼查詢企業內資料的方法
3. 聯想智慧鬧鐘新增AI情境理解功能,可根據當下時間和天氣來播放不同鬧鈴
資料來源:iThome整理,2019年12月
熱門新聞

2026-02-11

2026-02-09

2026-02-10
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-06

2026-02-10

2026-02-10

2026-02-10