
為利用健保大數據對腦瘤辨識模型DeepMets重複訓練,臺北榮總放射線部主任郭萬祐先將DeepMets作為標註工具,將健保署提供的資料標註後,自己再檢視、標註剩餘資料,並利用這些標註好的資料,來訓練DeepMets,以此循環。
臺北榮總
影像辨識AI要有良好的成效,就得要有夠多樣的訓練資料,單一家醫院訓練的AI模型,放到其他醫院也能適用嗎?臺北榮總放射線部主任郭萬祐6日分享健保AI大數據應用成果,透過3,000多例、來自不同醫院的去識別化腦瘤MRI的資料,改善了原本自家腦轉移瘤辨識模型 ,可以用來辨識來自不同廠牌MRI設備的影像。臺北榮總更進一步,在國網中心來測試聯合學習(Federated Learning)分散式訓練;這也是臺灣的醫院首度利用本土資料嘗試的聯合學習試驗,發現訓練後的模型,不太會受到不同廠牌和掃描參數的資料的影響,就算各家醫院影像品質落差很大也能適用。
用20多年數據開發腦瘤AI,30秒就能揪出病灶
2018年,臺北榮總與臺灣人工智慧實驗室(AI Labs)聯手,利用院內20幾年累積下來的加馬刀手術資料,來打造一套腦轉移瘤AI模型DeepMets。參與開發的核心人物郭萬祐指出,臺北榮總提供1,100例經標註的腦轉移瘤MRI,給臺灣人工智慧實驗室當作訓練資料。經過半年訓練、調校,才開發出這套可以成功辨識腦轉移瘤的AI模型。
這套DeepMets,大幅縮短了原始的作業流程。原本,一位病患接受一次腦部MRI 掃描,會產生數百張各式切面的影像,而這些影像會傳送至醫院的PACS(醫療影像儲存與傳輸系統)上,再由醫生判讀。一般來說,醫生平均需要30分鐘才能完成病灶標註,如果需要再次檢查,就需要更長的時間。
但是,有了AI模型,醫生可直接從PACS中點選DeepMets,讓AI自動判讀MRI。只要30秒,就能從數百張MRI中標示出病灶位置、自動計算出腫瘤體積,作為醫生的第二參考意見。要是AI出錯,醫生也能手動校正。經過幾次微調,DeepMets的敏感度與準確度分別達到96%與86%的水準。
採用健保大數據蒐集不同來源的異值資料,來強化AI
不過,郭萬祐指出,有些人質疑,這套利用自家醫院均值影像訓練的AI系統,「走出臺北榮總後,還能存活嗎?」
為探討這個議題,他利用轉診患者的腦部MRI,來檢測DeepMets的判斷能力。這些轉診患者的腦部MRI是在不同醫院拍攝,來自不同廠牌、不同型號和不同掃描參數的異質資料,而非原本DeepMets的訓練資料源的拍攝環境。
實驗結果,「DeepMets雖有能力辨識,」但不夠理想。所以,郭萬祐去年夏季,決定申請健保署推動的健保資料AI應用服務試辦計畫,「走出臺北榮總牆外,」讓團隊利用健保雲端集中式的異質醫療影像資料,來改善DeepMets表現。
為了這項計畫,健保署也規畫了「AI工作區」讓團隊研究。他們層層把關,不僅設備無法對外連線,也採獨立特殊網段區隔;在資料方面,除了將所有資料去識別化,也禁止團隊攜出任何資料,「甚至連我做的筆記,也要經過審核才能帶出,」郭萬祐說。
在流程上,臺北榮總首先將DeepMets模型作為標註工具,來註釋健保署提供的3,000多例資料,接著由郭萬祐人工檢視、標註其餘未標註的病灶資料,然後再將這些標註好的資料,結合臺北榮總的資料,對DeepMets進行再訓練。重複多遍,來找出提高模型表現的參數。
為了測驗改良過的DeepMets,郭萬祐將原本已知的腦瘤MRI個案,依難易度分為簡單、中等、難和陰性等四種,並依廠牌分為A、B、C三種(如下圖),總共120例。
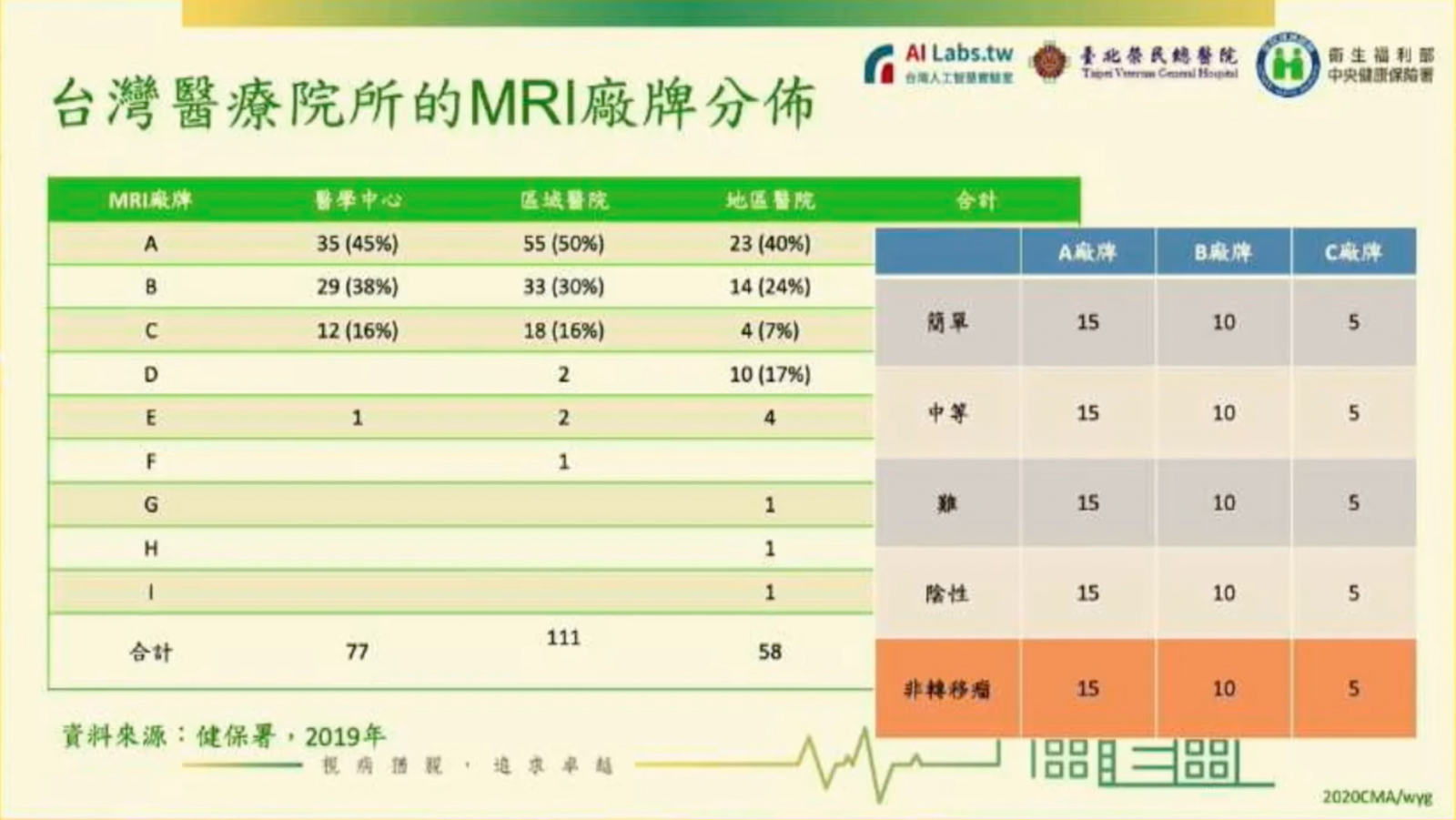
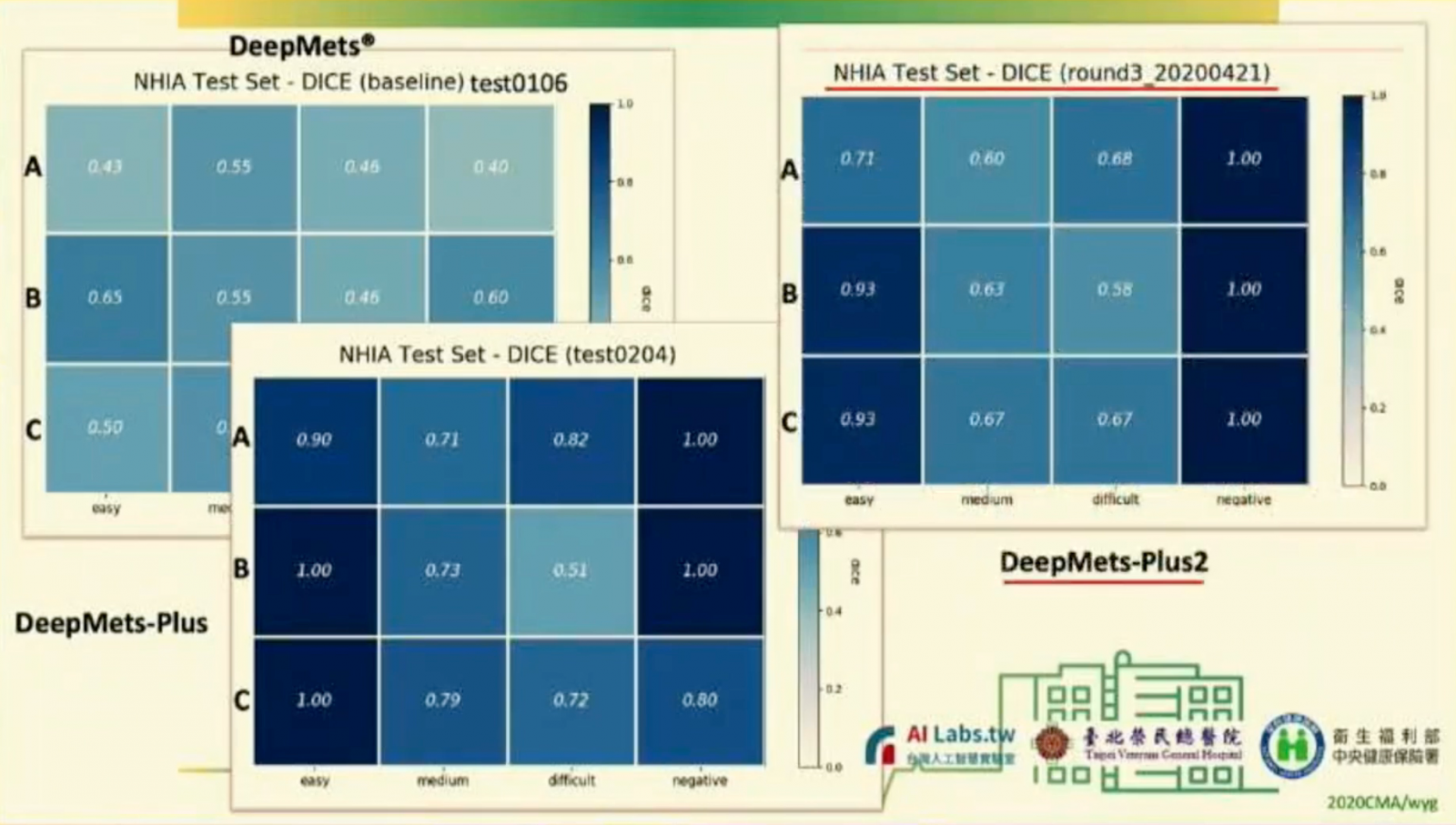
接著,他再把經過異質資料訓練的模型,來判斷這120例個案,並與原本各自人工判讀的結果比較,還利用DICE相似係數,來比較,同一個模型對不同廠牌拍攝影像的辨識能力。其中,顏色越深,代表越相近;從比對結果可發現,經過越多次異質資料訓練,AI模型辨識結果的DICE值可以越高(如下圖),越能判斷多元的醫療影像。而最終的腦瘤辨識模型,就命名為DeepMets-Plus。
有趣的是,「在這個過程中,我們注意到臺灣醫療院所的MRI廠牌占有率,對模型訓練來說很重要。」少數幾家市占越高,容易取得這些主流廠牌的影像來訓練,模型的解讀能力也會越好,他指出,如此一來,模型才能在未來的市場上存活。
利用異質性資料精進的AI,來驗證聯合學習共享模型在臺的可行性
郭萬祐指出,健保署握有全國醫院上傳的醫療影像資料,成立國家級巨量醫療影像資料庫,是獨步全球的作法。但要,這個方法很難應用到重視個資隱私的國家,更遑論要求各分院上傳患者資料,來共同打造一套模型,來改善模型異質性資料不足的問題。
也因此,近年來國際上興起一種做法,也就是聯合學習(Federated Learning),透過分散式機器學習訓練,將參與研究的各個據點,其訓練出的AI模型上傳至聯合學習中心,再以數學統計方式,來整合模型,再下放回各研究據點,導入原臨床場域試用。在這個過程中,敏感的個資不需離開各原始研究據點,以共享模型來取代共享資料,來進行研究。
於是,臺北榮總也測試了聯合學習在臺灣的可行性。團隊利用國網中心的雲端虛擬環境,建置了代表不同醫院的資訊環境,並各自利用用不同來源的腦部MRI,來訓練各自的腦瘤辨識模型。
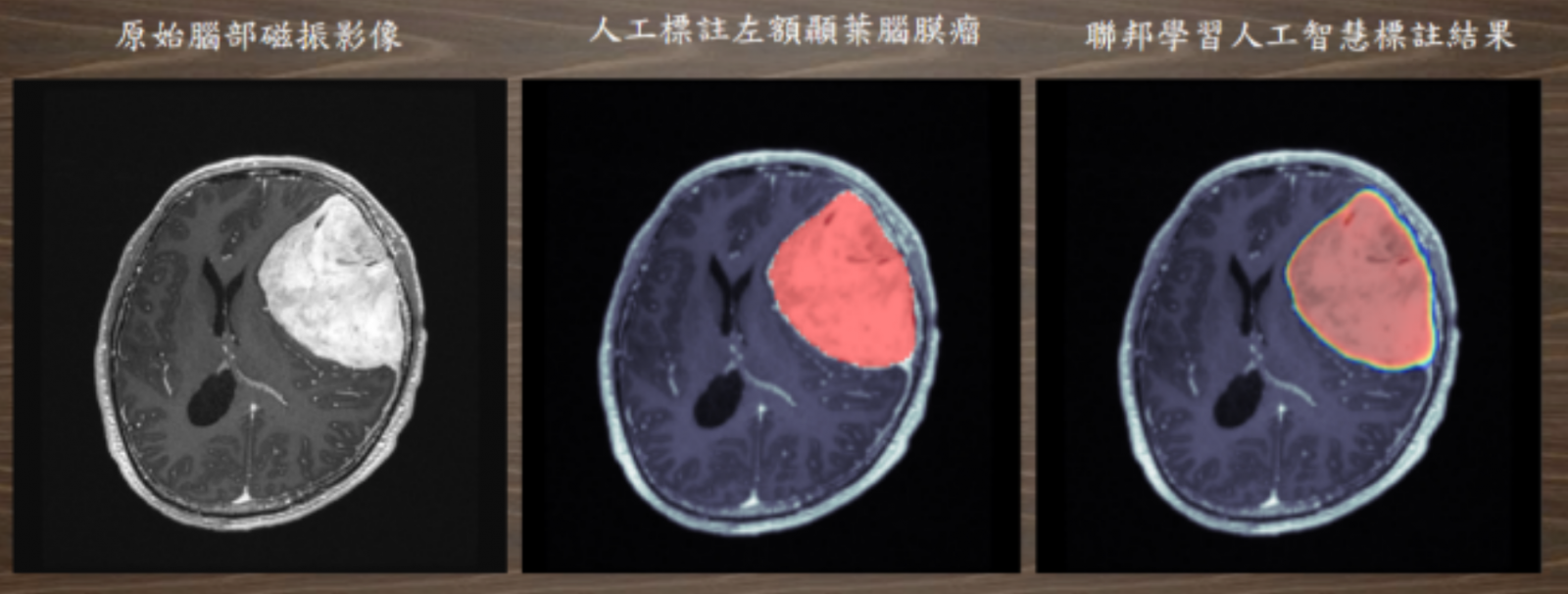
接著,團隊再將這些虛擬醫學中心的模型統計值,統一上傳至一套母模型,來進行聯合學習訓練。結果顯示,透過聯合學習訓練出來的AI模型,同樣可以辨識7種腦瘤,如同利用健保署異質資料進行集中式訓練的AI模型;測試結果也發現,在聯合學習架構下,「不同廠牌和掃描參數的影響並不大,也不受影像品質影響。」郭萬祐也秀了一張比對圖,來證明聯合學習的成效,與人工標註的病灶區域相差無幾(如下圖)。郭萬祐認為,聯合學習可望解決集中式學習所遇到的困難,來克服異質性資料不足的問題。文◎王若樸
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-12

2026-02-10


2026-02-06