
Google近期多項自動翻譯的技術改進,不只更換模型,也讓模型訓練可以應用從網路上抓取,具有許多雜訊的資料,因而大幅提升了翻譯品質,讓100多種語言翻譯到英文的的BLEU分數,平均提高5分,尤其是低資源語言的翻譯,更是有長足進展。
機器學習技術的發展,同時也帶動了自動翻譯前進的腳步,在2016年Google翻譯使用了GNMT神經翻譯模型,極大程度地提升100多種語言的翻譯品質,但即便是最先進的系統,在各方面的表現仍然遠遠落後人類,Google提到,具有大量訓練資料的語言,像是西班牙語與德語,翻譯表現較佳,但是例如馬拉雅拉姆語和約魯巴語,仍然有許多需要改進的地方。
現在有不少研究,在受控制的環境中,能提升低資源語言的翻譯品質,但Google表示,這些技術要擴展應用到從網路爬抓來的大量資料集並不容易。而Google透過合成和擴展最新方法,讓這些技術得以應用這些具有雜訊的資料集,因此能往前推進自動翻譯成果,這些技術包括改進模型基礎架構以及訓練方法、降低資料集的雜訊影響,並透過M4建模增加對多語言遷移學習。
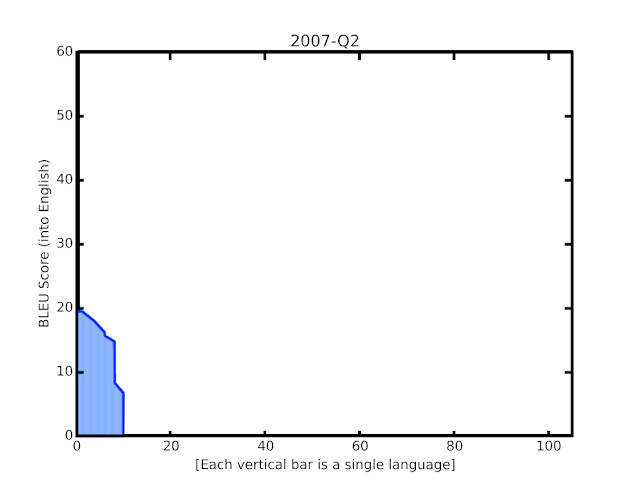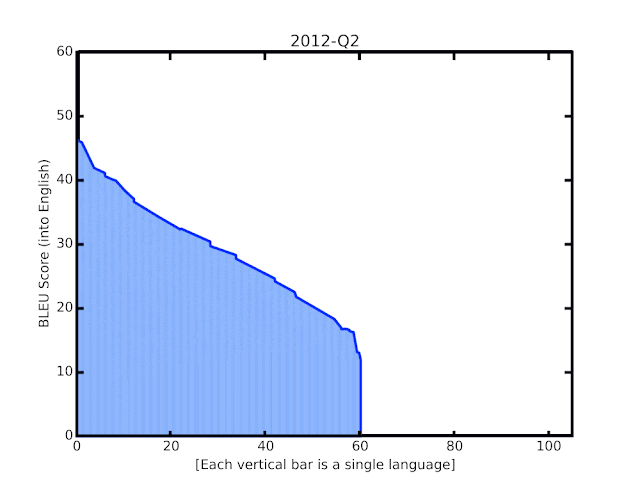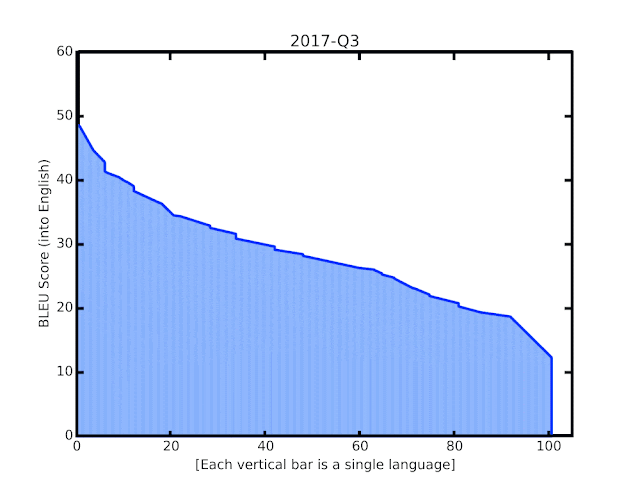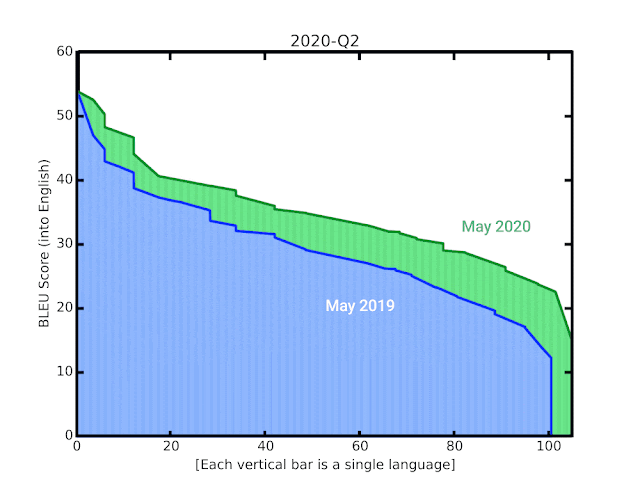
Google替換了4年前基於RNN的GNMT模型,現在以TensorFlow框架Lingvo重新實作,使用Transformer編碼器以及RNN解碼器來訓練模型。新的Transformer模型在機器翻譯上比RNN模型效果更好,Google解釋,翻譯品質提升來自Transformer編碼器,RNN解碼器則是在推理時更快,Google混合兩者,讓模型訓練更穩且延遲更短。
在神經機器翻譯中,用來訓練模型的資料,是經過翻譯的例句和文件,這些資料通常從公開的網站收集而來,而現在Google更新了資料收集系統,收集到的句子數量增加約30%,且新的資料探勘程式更講究精確率而非召回率,所收集到的訓練資料品質更好。由於訓練資料的雜訊會影響模型品質,為了解決雜訊問題,Google先讓模型用存在雜訊的資料進行訓練,接著再以較小且較乾淨的資料子集進行訓練校正。
Google翻譯現在也使用反向翻譯技術,來提升低資源語言的翻譯品質,反向翻譯是使用合成的平行資料來強化平行訓練資料,合成平行訓練資料是指人類編寫的句子,搭配以神經翻譯模型生成的句子所組成的句子對。透過將反向翻譯整合到Google翻譯中,可使網路資源較少的語言,有更好的翻譯模型輸出流利性。另外,M4建模也是一種對低資源語言有用的技術,M4使用單一大型模型,進行所有語言和英語間的翻譯,而這將能達到大規模的遷移學習,為模型提供有用的語言訊號。
這些技術的改進,提升了機器翻譯自動評估指標BLEU的分數,現在Google翻譯新模型的BLEU,比起之前GNMT模型平均高出5分,而50種少資源語言的BLEU分數,平均更是增加7分。除了整體品質提升之外,新模型對機器翻譯幻覺(Hallucination)有更好的強健性,減少輸入無意義的文字時,會產生奇怪翻譯的狀況。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-10

2026-02-09