
IBM Security資安軟體工程師郭柏妤分享IBM如何以Quad9資料來分群網域,並從中找出惡意網域。
攝影/王若樸
IBM旗下免費DNS服務Quad9(9.9.9.9)不只是提供DNS查詢,更大特色是內建了釣魚網站資料庫,可以預先阻擋,避免使用者或端點裝置接觸到惡意網站,但是這個服務每天查詢量高達4.4億次,每天會接觸到500萬個獨特的網域名稱,IBM Security部門資安軟體工程師郭柏妤,在臺灣資安大會上揭露,IBM如何從海量時序性資料中揪出惡意網域;她指出,做到單日阻擋6千萬筆惡意網站連線行為的關鍵,就是機器學習。
利用Quad9網域查詢流量曲線,分群找出異常模式
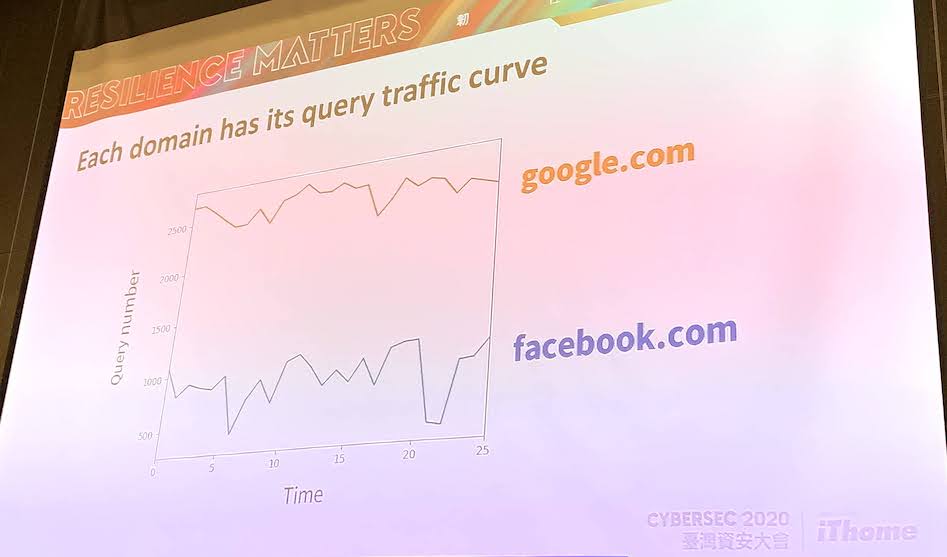
Quad9的海量資料中,還包括了網域名稱的查詢流量曲線(Query traffic curve),可讓使用者查看特定網域名稱(比如google.com)在一段時間內的查詢次數(如下圖)。郭柏妤指出,有些網域流量曲線具相似特徵,比如早上查詢流量特別多;於是,IBM就根據這些流量特徵來分群(Clustering),想從這些群中,找出擁有類似特徵的惡意網域群。
要將查詢流量曲線的分群,可分為三步驟,也就是預處理、分群和評估。郭柏妤表示,預處理十分重要,因為它影響了之後的辨識準確度。而預處理階段又可分為兩部分,首先是將自家資料預處理,「遇到資料量太大的問題時,可採用切割方法,」比如將三個月的資料量,分割為一個月,或是再細分為周、日。
不過,資料分割難免會流失資訊,這時,郭柏妤就推薦以主成分分析(PCA)來代替。「PCA能將高維度資料,轉換為低維度資料,而且轉換之後,效能會更好。」
處理完自家資料後,再來就是Quad9資料的預處理,可分為過濾(Filtering)、聚合(Aggregation)和標準化(Normalization)。過濾的目的,是要剔除不符合網域名稱規範的網域,比如loca,gaia-tech.com,同時也剔除總查詢次數少於10的網域。
再來是聚合,也就是將查詢流量對應到一段特定時間,比如在某1小時內的網域總查詢次數。最後則是標準化,要來解決不同網域間的查詢差異,比如級距、數量,如此才能聚焦於曲線本身。標準化後的值,會介於0與1之間(如下圖)。

這些預處理完的資料,會輸入到分群的機器學習模型中來計算。在這個階段,可分為三個步驟,首先是決定「要分多少群」,再來是網域之間的距離量測,最後才是演算法運算。進一步來說,在決定群的數量時,郭柏妤推薦輪廓係數(Silhouette Coefficient)方法,來計算群與群之間的距離,並找出最佳的分群數。
再來,為測量網域之間的距離,最常見的方法是歐幾里德距離(Euclidian Distance),來進行一對一的映射。然而,當兩條平行線出現波峰和波谷時,就難以準確對應,所以兩側的距離就不夠相符。
這時,可靠動態規畫(DTW)演算法來解決。DTW會先在時間序列間尋找最佳路徑,將「直線映射到直線,波峰映射到波峰,」映射完後才會開始計算距離。雖然DTW可以解決問題,「但不代表是最佳解。」郭柏妤指出,DTW所耗費的計算時間,可高達歐幾里德距離的2,800多倍。
量測距離後,下一個步驟是演算法計算。除了常見的k-means演算法,郭柏妤還推薦了DBSCAN,「因為它能夠分辨離群值(Outlier),」不像k-means會將離群值歸類到其他群。
IBM實作找出有害的DGA網域群,還可作為特徵指標
「我們也用以上方法,找出有害的域名生成演算法(DGA)網域群。」郭柏妤指出,DGA是指透過演算法和隨機字元生成網域名稱,來躲避黑名單的檢測,而在IBM實作中,團隊只用了網域查詢流量曲線,就能分群找出DGA網域,「完全不需要IP資料或其他特徵資料。」
此外,透過分群機制,IBM也找出了網域中含有Spam類別的網域,另外也成功在19個網域中,找出8個被Quad9忽略的惡意網域。
郭柏妤認為,用Quad9資料找出的分群結果,還可作為特徵指標,來幫助團隊找出惡意程式。文◎王若樸
熱門新聞

2026-02-06

2026-02-06

2026-02-09

2026-02-09

2026-02-06


2026-02-06
")
2026-02-09