深度學習函式庫TensorFlow釋出最新版本2.4,該版本支援新的分散式訓練策略,Keras還更新了混合精度功能,加速模型訓練工作,此外,TensorFlow 2.4提供Python開發者,熟悉的數值運算函式庫NumPy支援,而用於監控和診斷的分析工具也有更新,以支援新加入的功能。
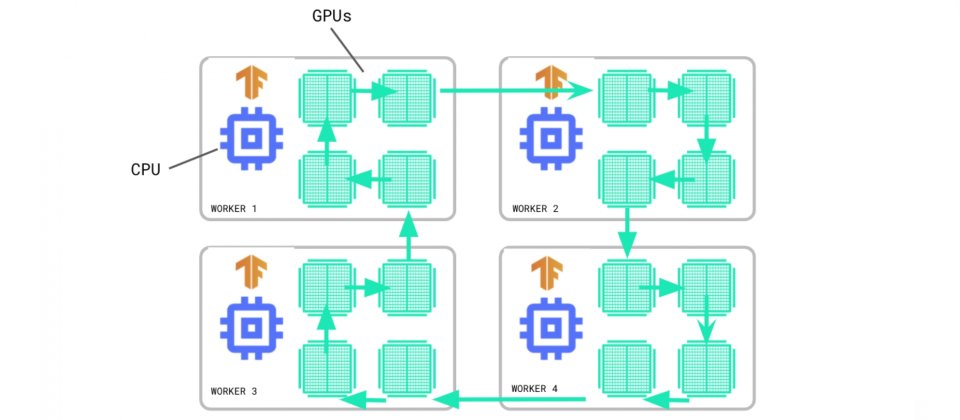
TensorFlow中分散式訓練模組tf.distribute更新兩個重要策略,tf.distribute不同策略可讓開發者以不同的方法分散運算。更新的策略分別是多工作節點鏡像策略MultiWorkerMirroredStrategy API,進入穩定階段,而參數伺服器策略ParameterServerStrategy API和自定義訓練迴圈,則開始提供實驗性支援。官方提到,ParameterServerStrategy就像是MultiWorkerMirroredStrategy一樣,是一種多工作節點資料平行策略,只不過梯度更新是以非同步的方式。
一個參數伺服器訓練叢集,由多個工作節點與參數伺服器組成,參數伺服器會創建變數,供工作節點讀取和更新,而變數讀取和更新在所有工作節點中,皆獨立進行,沒有執行任何的同步作業,而由於工作節點互不相依,因此該策略有容錯的優點,並且在先占式虛擬機器特別好用。
多工作節點鏡像策略,則脫離實驗階段成為穩定API,MultiWorkerMirroredStrategy以同步資料平行性實作分散式訓練,也就是說,開發者可以在多臺具有多個GPU的機器上,執行訓練工作。在同步訓練中,每個工作節點運算前後不同的資料片段,並會在更新模型之前匯總梯度。
TensorFlow Profiler也開始支援多節點訓練策略,TensorFlow Profiler是一套讓開發者評估,TensorFlow模型訓練效能和資源消耗的工具,供開發者探索模型操作時,硬體資源消耗以及瓶頸,以達到加快訓練速度的目的。過去TensorFlow Profiler可用來監控單一主機多GPU的訓練工作,而現在也可用來分析MultiWorkerMirroredStrategy訓練工作。
在TensorFlow 2.4中,Keras混合精度已成為穩定API。大多數TensorFlow模型都使用float32資料類型,但是部分像是float16低精度類型,使用較少的記憶體,因此在同一個模型中,同時使用32和16位元浮點數,可以提升訓練速度,官方提到,使用混合精度API可以讓模型獲得3倍效能,在TPU上效能提升60%。
另外,這個版本TensorFlow還加入支援NumPy API子集,tf.experimental.numpy模組可以執行,經TensorFlow加速的NumPy程式碼,由於新模組是以TensorFlow為基礎建構,因此可以與TensorFlow無縫互通,不只能夠存取所有TensorFlow API,還透過編譯和自動向量化,來提供最佳化執行效能。這項支援可以提供像是TensorFlow ND陣列與NumPy函式互通,或是TensorFlow NumPy函式接受tf.Tensor和np.ndarray輸入等操作。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-09

2026-02-06